1、文本分类 1.1 n-gram 由于Bag of words不考虑词语的顺序,因此引入bag of n-gram。针对英文,词内的是char n-gram,用于词向量;词之间的是word n-gram,用于分类;对于中文,存在词粒度和字粒度。
举个例子,句子A为”今天天气真不错”,这里以词粒度举例,先分词为[“今天”,”天气”,”真“,”不错“]
uni-gram:今天 天气 真 不错
2-gram为:今天/天气 天气/真 真/不错
3-gram为:今天/天气/真 天气/真/不错
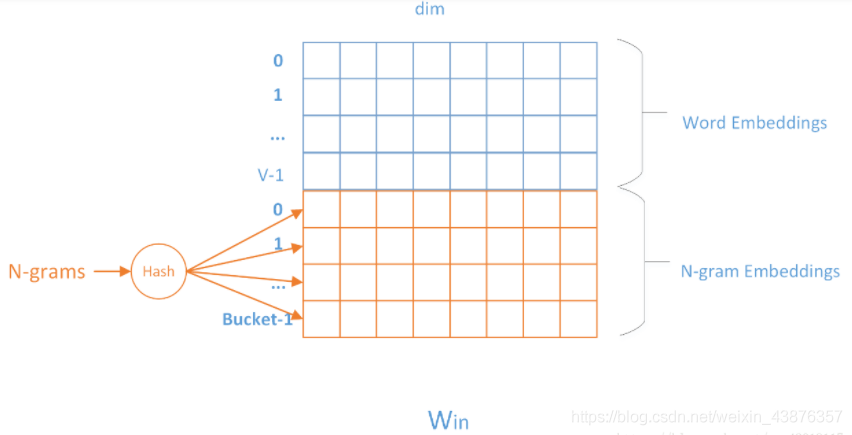
由于n-gram的量远比word大的多,完全存下所有的n-gram也不现实。FastText采用了hashing trick的方式,如下图所示:
用哈希的方式既能保证查找时O(1)的效率,又可能把内存消耗控制在O(buckets * dim)范围内。不过这种方法潜在的问题是存在哈希冲突,不同的n-gram可能会共享同一个embedding。如果buckets取的足够大,这种影响会很小。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 def build_dataset(config, ues_word): if ues_word: tokenizer = lambda x: x.split(' ') # word-level else: tokenizer = lambda x: [y for y in x] # char-level if os.path.exists(config.vocab_path): vocab = pkl.load(open(config.vocab_path, 'rb')) else: vocab = build_vocab(config.train_path, tokenizer=tokenizer, max_size=MAX_VOCAB_SIZE, min_freq=1) pkl.dump(vocab, open(config.vocab_path, 'wb')) print(f"Vocab size: {len(vocab)}") def biGramHash(sequence, t, buckets): t1 = sequence[t - 1] if t - 1 >= 0 else 0 return (t1 * 14918087) % buckets def triGramHash(sequence, t, buckets): t1 = sequence[t - 1] if t - 1 >= 0 else 0 t2 = sequence[t - 2] if t - 2 >= 0 else 0 return (t2 * 14918087 * 18408749 + t1 * 14918087) % buckets def load_dataset(path, pad_size=32): contents = [] with open(path, 'r', encoding='UTF-8') as f: for line in tqdm(f): lin = line.strip() if not lin: continue content, label = lin.split('\t') words_line = [] token = tokenizer(content) seq_len = len(token) if pad_size: if len(token) < pad_size: token.extend([PAD] * (pad_size - len(token))) else: token = token[:pad_size] seq_len = pad_size # word to id for word in token: words_line.append(vocab.get(word, vocab.get(UNK))) # fasttext ngram buckets = config.n_gram_vocab bigram = [] trigram = [] # ------ngram------ for i in range(pad_size): bigram.append(biGramHash(words_line, i, buckets)) trigram.append(triGramHash(words_line, i, buckets)) # ----------------- contents.append((words_line, int(label), seq_len, bigram, trigram)) return contents # [([...], 0), ([...], 1), ...] train = load_dataset(config.train_path, config.pad_size) dev = load_dataset(config.dev_path, config.pad_size) test = load_dataset(config.test_path, config.pad_size) return vocab, train, dev, test
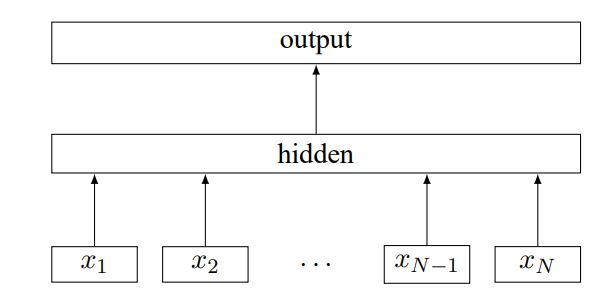
1.2 网络结构
模型结构上word2vec的cbow模型很像
输入层:举个例子,输入文本”今天天气真不错”,词粒度的2-gram为
中间层:线形层+relu作为激活函数
输出层:为简单的线形层
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Model(nn.Module): def __init__(self, config): super(Model, self).__init__() if config.embedding_pretrained is not None: self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False) else: self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1) self.embedding_ngram2 = nn.Embedding(config.n_gram_vocab, config.embed) self.embedding_ngram3 = nn.Embedding(config.n_gram_vocab, config.embed) self.dropout = nn.Dropout(config.dropout) self.fc1 = nn.Linear(config.embed * 3, config.hidden_size) # self.dropout2 = nn.Dropout(config.dropout) self.fc2 = nn.Linear(config.hidden_size, config.num_classes) def forward(self, x): out_word = self.embedding(x[0]) out_bigram = self.embedding_ngram2(x[2]) out_trigram = self.embedding_ngram3(x[3]) out = torch.cat((out_word, out_bigram, out_trigram), -1) out = out.mean(dim=1) out = self.dropout(out) out = self.fc1(out) out = F.relu(out) out = self.fc2(out) return out
1.3 分层softmax 对于分类问题,神经网络的输出结果需要经过softmax将其转为概率分布后才可以利用交叉熵计算loss
由于普通softmax的计算效率比较低,计算效率为$O(Kd)$使用分层的softmax时间复杂度可以达到$dlogK$,$K$为分类的数量,$d$为向量的维度
1.3.1 普通softmax 假设输出为$Y_{pred}=[y_1,y_2,…,y_K]$,则$P_{y_i}$为
其中$y_i$的维度为$d$,从公式可以看出计算效率为$O(Kd)$
1.3.2 分层softmax 霍夫曼树可以参考 https://zhuanlan.zhihu.com/p/154356949
为什么要霍夫曼,普通的不行?
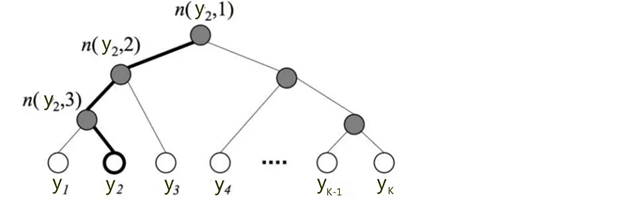
分层softmax核心思想为利用训练样本构建霍夫曼树,如下
树的结构是根据不同类在样本中出现的频次构造的,即频次越大的节点距离根节点越近。$K$个不同的类组成所有的叶子节点,$K-1个$内部节点作为参数。从根节点到某个叶子节点$y_i$经过的节点和边形成一条路径,路径长度表示为 $L_{y_i}$,$n_{(y_i,j)}$表示路径上的节点,那么
从公式可以看出时间复杂度降低至$dlogK$。
以图中$y_2$为例:
从根节点走到叶子节点 $y_2$ ,实际上是在做了3次逻辑回归。
2.训练词向量 https://arxiv.org/abs/1607.04606
参考 https://arxiv.org/abs/1607.01759
https://zhuanlan.zhihu.com/p/32965521
https://blog.csdn.net/qq_27009517/article/details/80676022
http://alex.smola.org/papers/2009/Weinbergeretal09.pdf
https://arxiv.org/abs/1607.04606
fasttext工具 https://github.com/facebookresearch/fastText