文本表示
文本表示的表示形式可以是单一数值(基本没人用),可以是向量(目前主流),好奇有没有高纬tensor表示的?下文是基于向量表示的。
1.词语表示
1.1 one hot
举个例子,有样本如下:
Jane wants to go to Shenzhen.
Bob wants to go to Shanghai.
基于上述两个文档中出现的单词,构建如下一个词典:
Vocabulary= [Jane, wants, to, go, Shenzhen, Bob, Shanghai]
那么wants 可以表示为
1 | [0,1,0,0,0,0,0] |
1.2 word embedding
词向量模型是考虑词语位置关系的一种模型。通过大量语料的训练,将每一个词语映射到高维度的向量空间当中,使得语意相似的词在向量空间上也会比较相近,举个例子,如
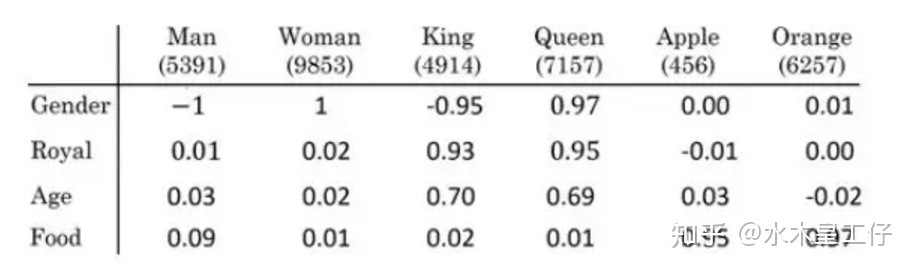
上表为词向量矩阵,其中行表示不同特征,列表示不同词,Man可以表示为
1 | [-1,0.01,0.03,0.09] |
性质:$emb_{Man}-emb_{Women}\approx emb_{King}-emb_{Queen}$
常见的词向量矩阵构建方法有,word2vec,GloVe
2.句子表示
2.1 词袋模型
词袋模型不考虑文本中词与词之间的上下文关系,仅仅只考虑所有词的权重。而权重与词在文本中出现的频率有关。
例句:
Jane wants to go to Shenzhen.
Bob wants to go to Shanghai.
基于上述两个文档中出现的单词,构建如下一个词典:
Vocabulary= [Jane, wants, to, go, Shenzhen, Bob, Shanghai]
那么上面两个例句就可以用以下两个向量表示,其值为该词语出现的次数:
1 | [1,1,2,1,1,0,0] |
2.2 Sentence Embedding
2.2.1 评价工具
SentEval is a popular toolkit to evaluate the quality of sentence embeddings.
2.2.2 常见方法
sentence BERT
BERT-flow
https://zhuanlan.zhihu.com/p/444346578
参考文献
https://zhuanlan.zhihu.com/p/353187575
1.Bert系列之句向量生成
2.token embedding
3.SimCSE Simple Contrastive Learning of Sentence Embeddings
4.ConSERT A Contrastive Framework for Self-Supervised Sentence Representation Transfer
5.word2vec
6.nlp中使用预训练的词向量和随机初始化的词向量的区别在哪里?
7.Sentence-BERT Sentence Embeddings using Siamese BERT-Networks

