bert(Pre-training of Deep Bidirectional Transformers for Language Understanding)
https://arxiv.org/abs/1810.04805
1 结构
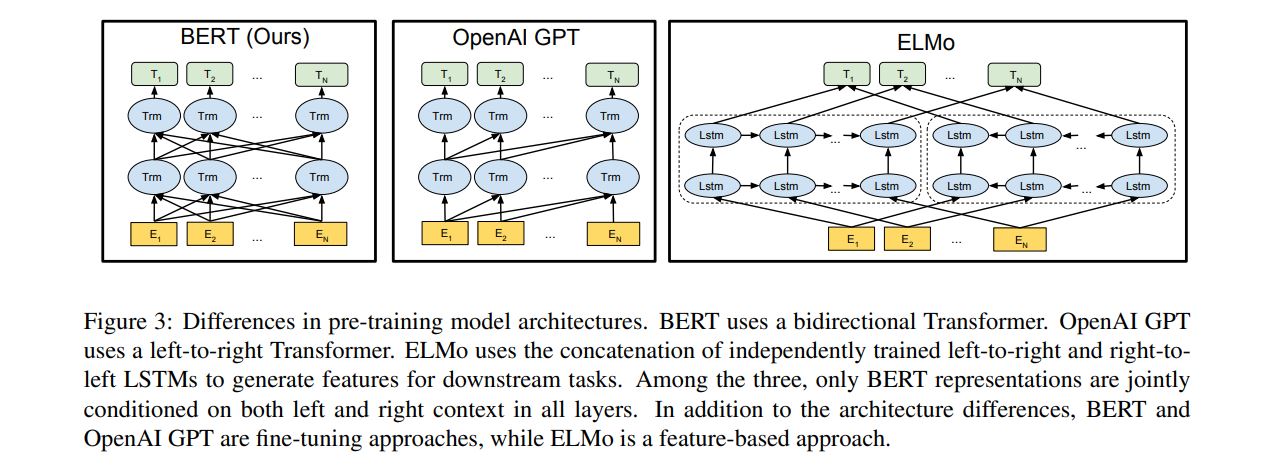
整体结构如上图,基本单元为Transformer 的encoder部分。作者对结构的描述为:BERT’s model architecture is a multi-layer bidirectional Transformer encoder。
2 Input/Output Representations
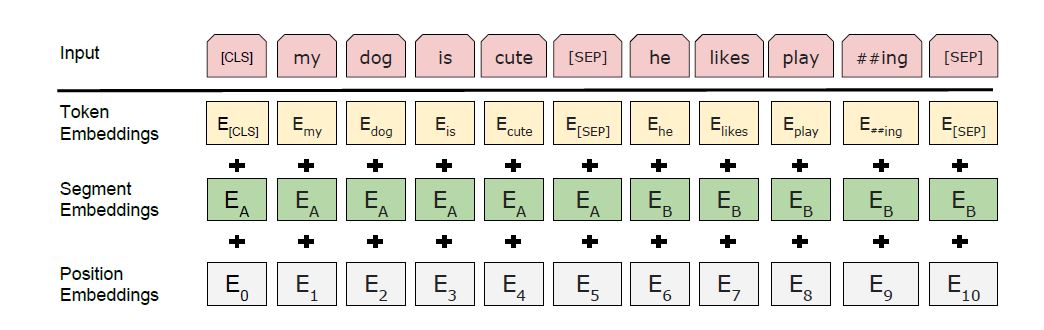
[CLS]表征句子开始,[SEP]表示句子结束以及分割两个句子
Token Embedding为词向量的表示,Position Embedding为位置信息,Segment Embedding表示A,B两句话,最后的输入向量为三者相加。比起transformer多一个Segment Embedding。
具体例子:https://www.cnblogs.com/d0main/p/10447853.html
3 预训练任务
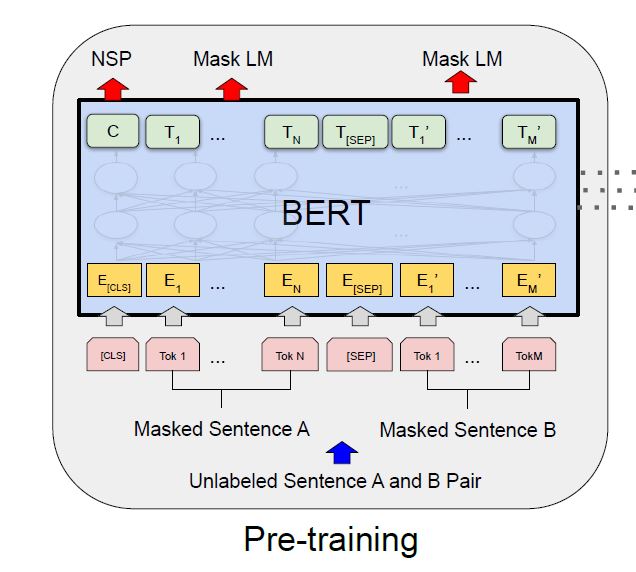
1 Masked LM
standard conditional language models can only be trained left-to-right or right-to-left , since bidirectional conditioning would allow each word to indirectly “see itself”.In order to train a deep bidirectional representation,MLM
The training data generator chooses 15% of the token positions at random for prediction. If the i-th token is chosen, we replace the i-th token with (1) the [MASK] token 80% of the time (2) a random token 10% of the time (3) the unchanged i-th token 10% of the time.
2 Next Sentence Prediction (NSP)
In order to train a model that understands sentence relationships
choosing the sentences A and B for each pretraining example, 50% of the time B is the actual next sentence that follows A (labeled as IsNext), and 50% of the time it is a random sentence from the corpus (labeled as NotNext).
4 Fine-tuning BERT
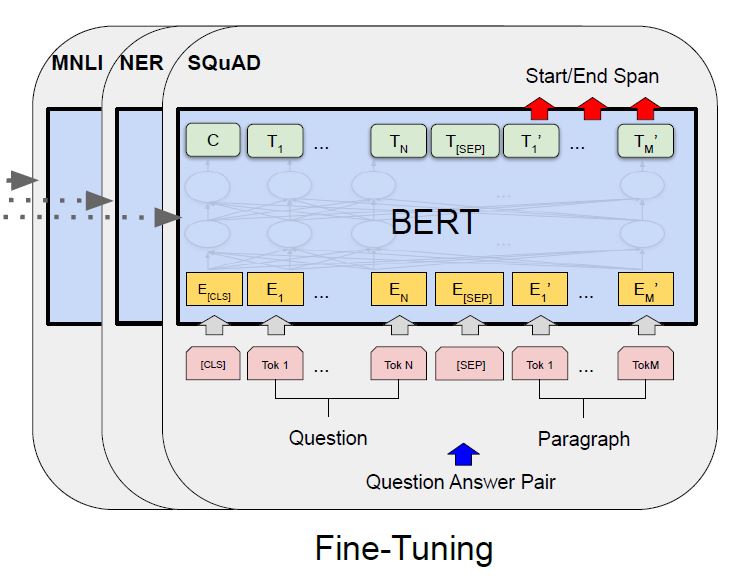
For each task, we simply plug in the task specific inputs and outputs into BERT and finetune all the parameters end-to-end.
输入: 可以为句子对或者单句,取决于特定任务
输出:At the output, the token representations are fed into an output layer for token level tasks, such as sequence tagging or question answering, and the [CLS] representation is fed into an output layer for classification, such as entailment or sentiment analysis.
5 常见问题
1 bert为什么双向,gpt单向?
1.结构的不同
因为BERT用了transformer的encoder,在编码某个token的时候同时利用了其上下文的token,但是gptT用了transformer的decoder,只能利用上文
2.预训练任务的不同
2 为什么bert长度固定?
因为bert是基于transformer encoder的,不同位置的词语都是并行的,所以长度要提前固定,不可变
bert的输入输出长度为max_length,大于截断,小于padding,max_length的最大值为512
3 为什么bert需要补充位置信息?
因为是并行,不像迭代,没有天然的位置信息,需要补充position embedding。
bert(Pre-training of Deep Bidirectional Transformers for Language Understanding)

