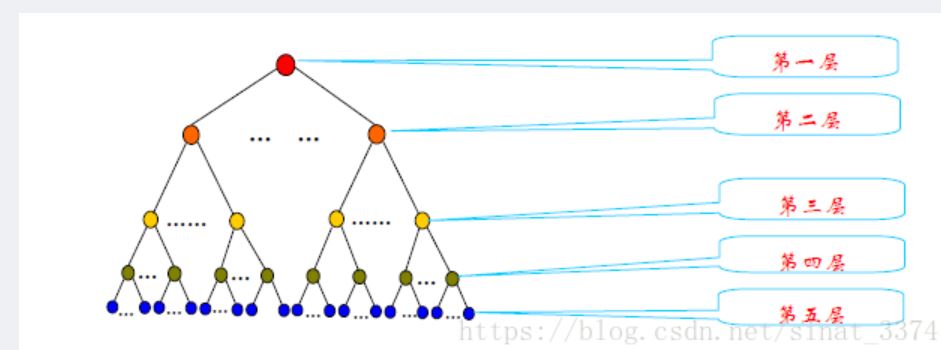
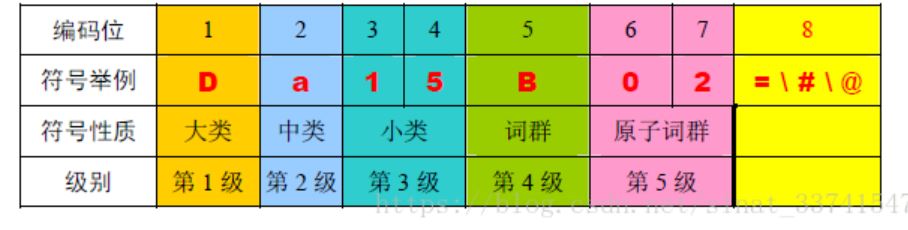
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
| from hownet.howNet import How_Similarity
from cilin.V3.ciLin import CilinSimilarity
class HybridSim():
'''
混合相似度计算策略。使用了词林与知网词汇量的并集。扩大了词汇覆盖范围。
'''
ci_lin = CilinSimilarity() # 实例化词林相似度计算对象
how_net = How_Similarity() # 实例化知网相似度计算对象
Common = ci_lin.vocab & how_net.vocab
A = how_net.vocab - ci_lin.vocab
B = ci_lin.vocab - how_net.vocab
@classmethod
def get_Final_sim(cls, w1, w2):
lin = cls.ci_lin.sim2018(w1, w2) if w1 in cls.ci_lin.vocab and w2 in cls.ci_lin.vocab else 0
how = cls.how_net.calc(w1, w2) if w1 in cls.how_net.vocab and w2 in cls.how_net.vocab else 0
if w1 in cls.Common and w2 in cls.Common: # 两个词都被词林和知网共同收录。
# print('两个词都被词林和知网共同收录。', end='\t')
# print(w1, w2, '词林改进版相似度:', lin, end='\t')
# print('知网相似度结果为:', how, end='\t')
return lin * 1 + how * 0 # 可以调节两者的权重,以获取更优结果!!
if w1 in cls.A and w2 in cls.A: # 两个词都只被知网收录。
return how
if w1 in cls.B and w2 in cls.B: # 两个词都只被词林收录。
return lin
if w1 in cls.A and w2 in cls.B: # 一个只被词林收录,另一个只被知网收录。
print('触发策略三,左词为知网,右词为词林')
same_words = cls.ci_lin.code_word[cls.ci_lin.word_code[w2][0]]
if not same_words:
return 0.2
all_sims = [cls.how_net.calc(word, w1) for word in same_words]
print(same_words, all_sims, end='\t')
return max(all_sims)
if w2 in cls.A and w1 in cls.B:
print('触发策略三,左词为词林,右词为知网')
same_words = cls.ci_lin.code_word[cls.ci_lin.word_code[w1][0]]
if not same_words:
return 0.2
all_sims = [cls.how_net.calc(word, w2) for word in same_words]
print(w1, '词林同义词有:', same_words, all_sims, end='\t')
return max(all_sims)
if w1 in cls.A and w2 in cls.Common:
print('策略四(左知网):知网相似度结果为:', how)
same_words = cls.ci_lin.code_word[cls.ci_lin.word_code[w2][0]]
if not same_words:
return how
all_sims = [cls.how_net.calc(word, w1) for word in same_words]
print(w2, '词林同义词有:', same_words, all_sims, end='\t')
return 0.6 * how + 0.4 * max(all_sims)
if w2 in cls.A and w1 in cls.Common:
print('策略四(右知网):知网相似度结果为:', how)
same_words = cls.ci_lin.code_word[cls.ci_lin.word_code[w1][0]]
if not same_words:
return how
all_sims = [cls.how_net.calc(word, w2) for word in same_words]
print(same_words, all_sims, end='\t')
return 0.6 * how + 0.4 * max(all_sims)
if w1 in cls.B and w2 in cls.Common:
print(w1, w2, '策略五(左词林):词林改进版相似度:', lin)
same_words = cls.ci_lin.code_word[cls.ci_lin.word_code[w1][0]]
if not same_words:
return lin
all_sims = [cls.how_net.calc(word, w2) for word in same_words]
print(w1, '词林同义词有:', same_words, all_sims, end='\t')
return 0.6 * lin + 0.4 * max(all_sims)
if w2 in cls.B and w1 in cls.Common:
print(w1, w2, '策略五(右词林):词林改进版相似度:', lin)
same_words = cls.ci_lin.code_word[cls.ci_lin.word_code[w2][0]]
if not same_words:
return lin
all_sims = [cls.how_net.calc(word, w1) for word in same_words]
print(w2, '词林同义词有:', same_words, all_sims, end='\t')
return 0.6 * lin + 0.4 * max(all_sims)
print('对不起,词语可能未收录,无法计算相似度!')
return -1
|