attention seq2seq
1.结构
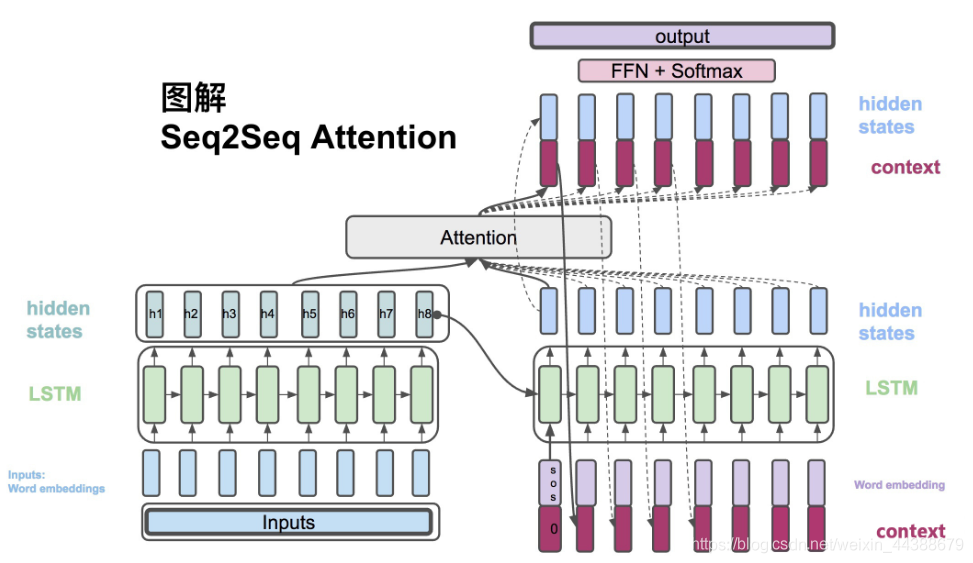
左边为encoder,对输入文本编码,右边为decoder,解码并应用。
整个流程的图解可以参考https://blog.csdn.net/weixin_44388679/article/details/102575223 中的“四、图解Attention Seq2Seq”,非常详细。
2.Teacher Forcing
在训练阶段,如果使用Teacher Forcing策略,那么目标句子单词的word embedding使用真值,否则使用预测结果;至于预测阶段不能使用Teacher Forcing。
3.beam search
beam search本质为介于蛮力与贪心之间的策略。对于贪心,每一级的输出只选择top1的结果作为下一级输入,然后top1的结果只是局部最优,不一定是全局最优,精度可能较低。对于蛮力,每级将全部结果输入下级,假设$L$为词表大小,那么最后一级的数据量为$L^{m}$,$m$为decoder 的cell数量,计算效率太低。对于beam search,每级选择top k作为下级输入,综合了效率和精度。
4 常见问题
0 为什么rnn based seq2seq不需要额外添加位置信息?
天然有位置信息(迭代顺序)
1 为什么rnn based seq2seq输入输出长度可变?
因为rnn based seq2seq是迭代进行的,所以长度可变
2 训练的时候要padding吗?
不用padding
参考
https://zhuanlan.zhihu.com/p/47929039
attention seq2seq

