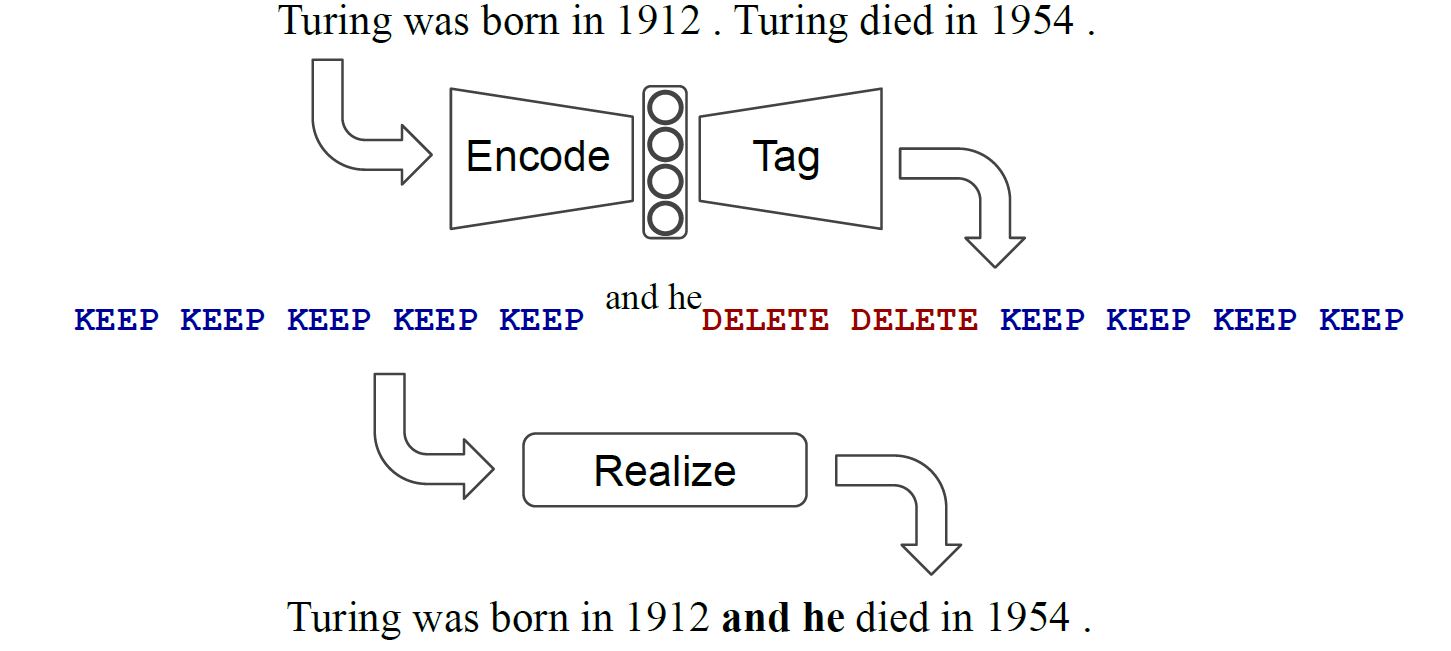
一般情况,tag分为两个大类: base tag $B$和 add tag $P$。对于base tag,就是$KEEP$或者$DELETE$当前token;对于add tag,就是要添加一个词到token前面,添加的词来源于词表$V$。实际在工程中,将$B$和$P$结合来表示,即$^{P}B$,总的tag数量大约等于$B$的数量乘以$P$的数量,即$2|V|$。对于某些任务可以引入特定的tag,比如对于句子融合,可以引入$SWAP$,如下图。
4.1.1 词表V的构建
构建目标:
最小化词汇表规模;
最大化目标词语的比例
限制词汇表的词组数量可以减少相应输出的决策量;最大化目标词语的比例可以防止模型添加无效词。
构建过程:
通过$LCS$算法(longest common sequence,最长公共子序列,注意和最长公共子串不是一回事),找出输入和输出序列的最长公共子序列,输出剩下的序列,就是需要$add$的token,添加到词表$V$,词表中的词基于词频排序,然后选择$l$个常用的。
def _compute_single_tag( self, source_token, target_token_idx, target_tokens): """Computes a single tag.
The tag may match multiple target tokens (via tag.added_phrase) so we return the next unmatched target token.
Args: source_token: The token to be tagged. target_token_idx: Index of the current target tag. target_tokens: List of all target tokens.
Returns: A tuple with (1) the computed tag and (2) the next target_token_idx. """ source_token = source_token.lower() target_token = target_tokens[target_token_idx].lower() if source_token == target_token: return tagging.Tag('KEEP'), target_token_idx + 1 # source_token!=target_token added_phrase = '' for num_added_tokens in range(1, self._max_added_phrase_length + 1): if target_token not in self._token_vocabulary: break added_phrase += (' ' if added_phrase else '') + target_token next_target_token_idx = target_token_idx + num_added_tokens if next_target_token_idx >= len(target_tokens): break target_token = target_tokens[next_target_token_idx].lower() if (source_token == target_token and added_phrase in self._phrase_vocabulary): return tagging.Tag('KEEP|' + added_phrase), next_target_token_idx + 1 return tagging.Tag('DELETE'), target_token_idx
def _compute_tags_fixed_order(self, source_tokens, target_tokens): """Computes tags when the order of sources is fixed.
Args: source_tokens: List of source tokens. target_tokens: List of tokens to be obtained via edit operations.
Returns: List of tagging.Tag objects. If the source couldn't be converted into the target via tagging, returns an empty list. """ tags = [tagging.Tag('DELETE') for _ in source_tokens] # Indices of the tokens currently being processed. source_token_idx = 0 target_token_idx = 0 while target_token_idx < len(target_tokens): tags[source_token_idx], target_token_idx = self._compute_single_tag( source_tokens[source_token_idx], target_token_idx, target_tokens) #################################################################################### # If we're adding a phrase and the previous source token(s) were deleted, # we could add the phrase before a previously deleted token and still get # the same realized output. For example: # [DELETE, DELETE, KEEP|"what is"] # and # [DELETE|"what is", DELETE, KEEP] # Would yield the same realized output. Experimentally, we noticed that # the model works better / the learning task becomes easier when phrases # are always added before the first deleted token. Also note that in the # current implementation, this way of moving the added phrase backward is # the only way a DELETE tag can have an added phrase, so sequences like # [DELETE|"What", DELETE|"is"] will never be created. if tags[source_token_idx].added_phrase: # # the learning task becomes easier when phrases are always added before the first deleted token first_deletion_idx = self._find_first_deletion_idx( source_token_idx, tags) if first_deletion_idx != source_token_idx: tags[first_deletion_idx].added_phrase = ( tags[source_token_idx].added_phrase) tags[source_token_idx].added_phrase = '' ######################################################################################## source_token_idx += 1 if source_token_idx >= len(tags): break
# If all target tokens have been consumed, we have found a conversion and # can return the tags. Note that if there are remaining source tokens, they # are already marked deleted when initializing the tag list. if target_token_idx >= len(target_tokens): # all target tokens have been consumed return tags return [] # TODO
def _compute_tags_fixed_order(self, source_tokens, target_tokens): """Computes tags when the order of sources is fixed.
Args: source_tokens: List of source tokens. target_tokens: List of tokens to be obtained via edit operations.
Returns: List of tagging.Tag objects. If the source couldn't be converted into the target via tagging, returns an empty list. """
tags = [tagging.Tag('DELETE') for _ in source_tokens] # Indices of the tokens currently being processed. source_token_idx = 0 target_token_idx = 0 while target_token_idx < len(target_tokens): tags[source_token_idx], target_token_idx = self._compute_single_tag( source_tokens[source_token_idx], target_token_idx, target_tokens) ######################################################################################### # If we're adding a phrase and the previous source token(s) were deleted, # we could add the phrase before a previously deleted token and still get # the same realized output. For example: # [DELETE, DELETE, KEEP|"what is"] # and # [DELETE|"what is", DELETE, KEEP] # Would yield the same realized output. Experimentally, we noticed that # the model works better / the learning task becomes easier when phrases # are always added before the first deleted token. Also note that in the # current implementation, this way of moving the added phrase backward is # the only way a DELETE tag can have an added phrase, so sequences like # [DELETE|"What", DELETE|"is"] will never be created. if tags[source_token_idx].added_phrase: # # the learning task becomes easier when phrases are always added before the first deleted token first_deletion_idx = self._find_first_deletion_idx( source_token_idx, tags) if first_deletion_idx != source_token_idx: tags[first_deletion_idx].added_phrase = ( tags[source_token_idx].added_phrase) tags[source_token_idx].added_phrase = '' #######################################################################################
source_token_idx += 1 if source_token_idx >= len(tags): break
# If all target tokens have been consumed, we have found a conversion and # can return the tags. Note that if there are remaining source tokens, they # are already marked deleted when initializing the tag list. if target_token_idx >= len(target_tokens): # all target tokens have been consumed return tags ####fix bug by lavine
###strategy1 added_phrase = "".join(target_tokens[target_token_idx:]) if added_phrase in self._phrase_vocabulary: tags[-1] = tagging.Tag('DELETE|' + added_phrase) print(''.join(source_tokens)) print(''.join(target_tokens)) print(str([str(tag) for tag in tags] if tags != None else None)) return tags ###strategy2 return [] # TODO
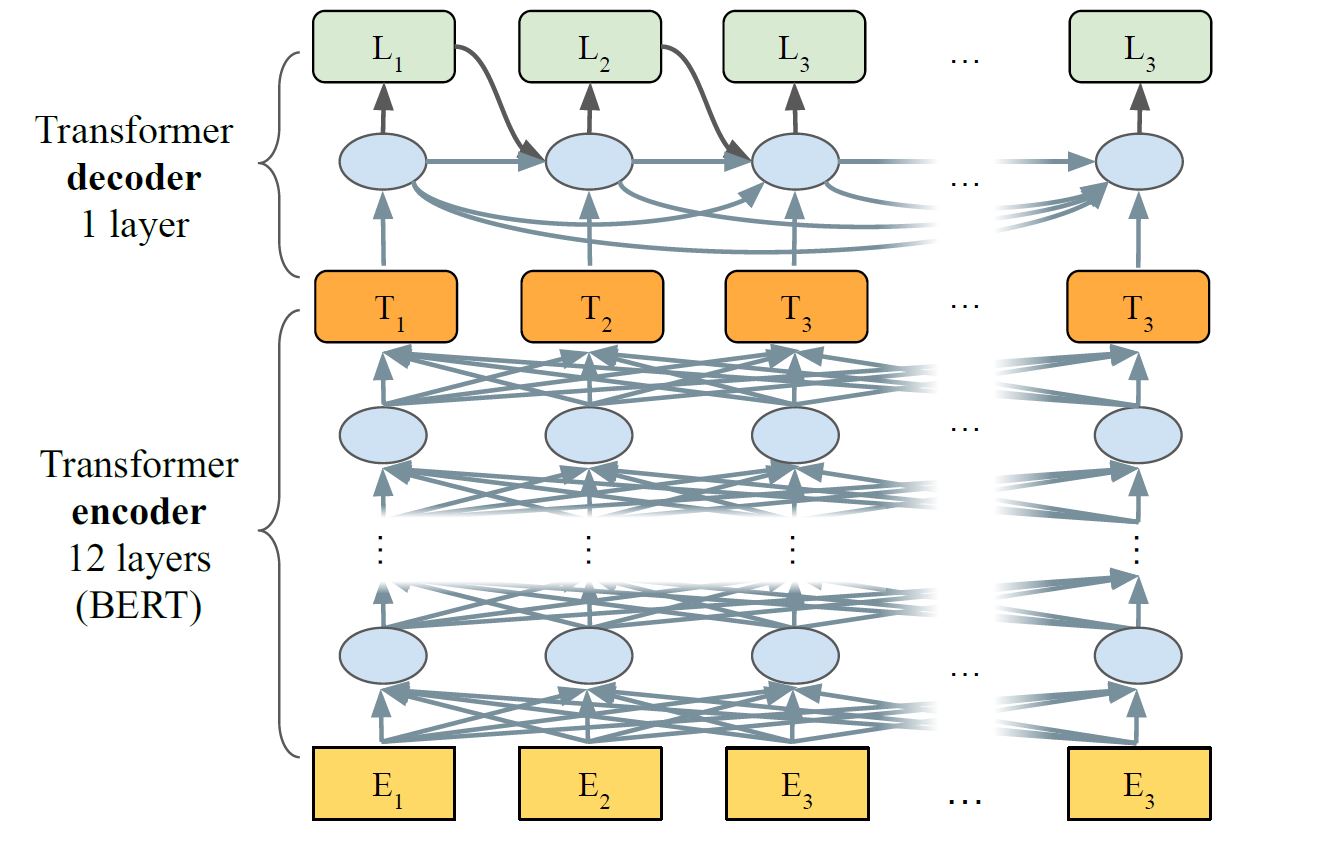
4.3 模型结构
模型主要包含两个部分:1.encoder:generates activation vectors for each element in the input sequence 2.decoder:converts encoder activations into tag labels
为了考虑标注词的关联性,decode使用了Transformer decoder,单向连接,记作$LASERTAGGER_{AR}$,这种encoder和decoder的组合的有点像BERT结合GPT的感觉decoder 和encoder在以下方面交流:(i) through a full attention over the sequence of encoder activations (ii) by directly consuming the encoder activation at the current step
Exact score :percentage of exactly correctly predicted fusions(类似accuracy)
SARI :average F1 scores of the added, kept, and deleted n-grams
2 Split and Rephrase
SARI
3 Abstractive Summarization
ROUGE-L
4 Grammatical Error Correction (GEC)
precision and recall, F0:5
七.实验结果
baseline: based on Transformer where both the encoder and decoder replicate the $BERT_{base}$ architecture
速度:1.$LASERTAGGER_{AR} $is already 10x faster than comparable-in-accuracy $SEQ2SEQ_{BERT}$ baseline. This difference is due to the former model using a 1-layer decoder (instead of 12 layers) and no encoder-decoder cross attention. 2.$LASERTAGGER_{FF}$ is more than 100x faster