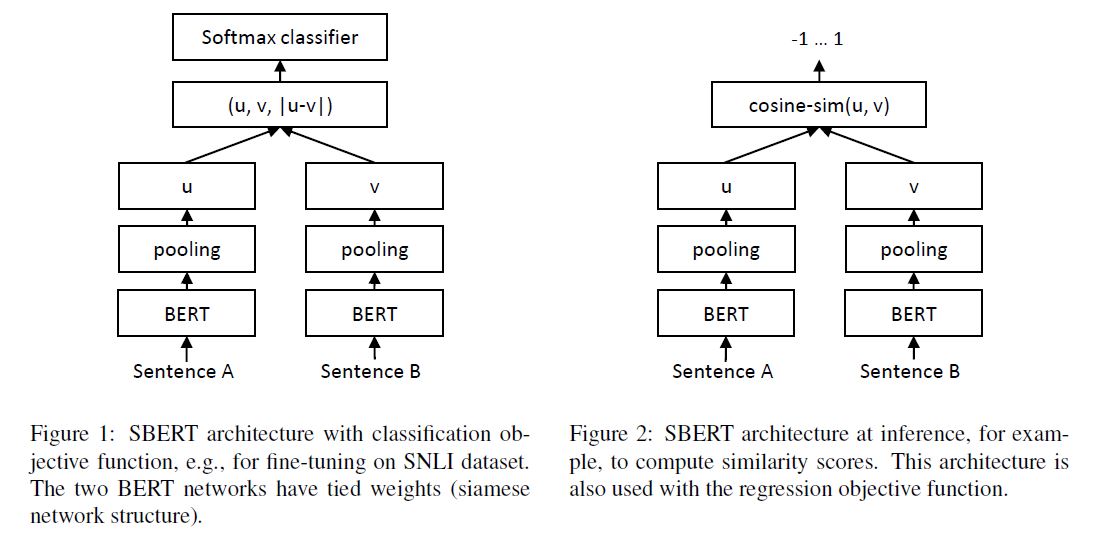
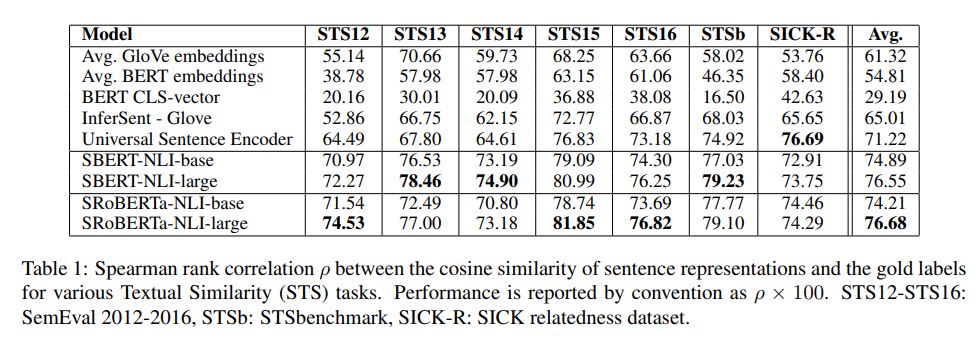
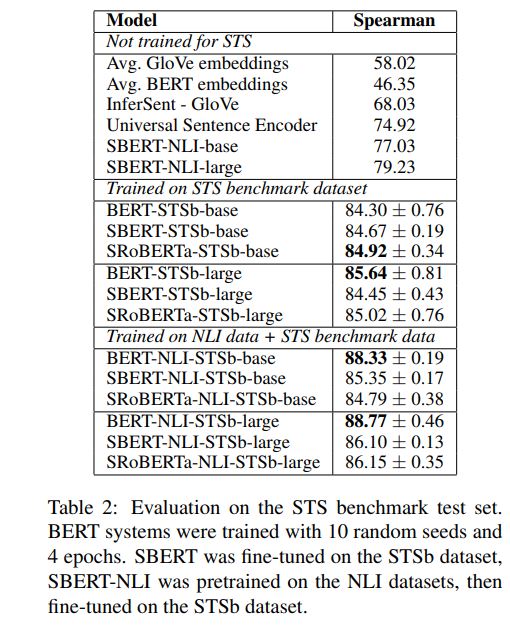
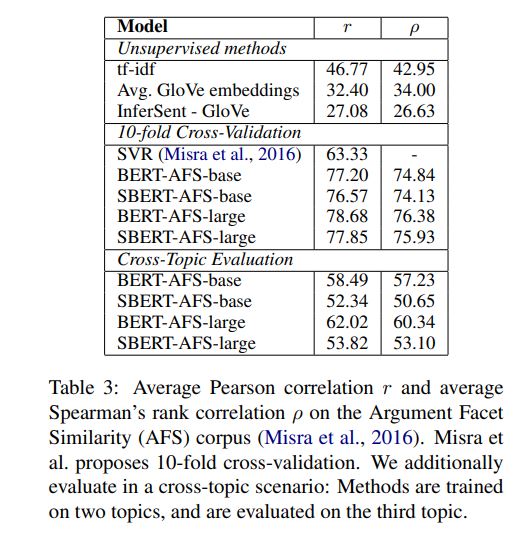
1.Using the output of the CLS-token 2.computing the mean of all output vectors (MEAN_strategy) 3.computing a max-over-time of the output vectors (MAX_strategy). The default configuration is MEAN.
from sentence_bert.sentence_transformers import SentenceTransformer, util
###load model model = SentenceTransformer(model_path)
# Single list of sentences sentences = ['The cat sits outside', 'A man is playing guitar', 'I love pasta', 'The new movie is awesome', 'The cat plays in the garden', 'A woman watches TV', 'The new movie is so great', 'Do you like pizza?']
#Compute cosine-similarities for each sentence with each other sentence cosine_scores = util.pytorch_cos_sim(embeddings, embeddings)
#Find the pairs with the highest cosine similarity scores pairs = [] for i in range(len(cosine_scores)-1): for j in range(i+1, len(cosine_scores)): pairs.append({'index': [i, j], 'score': cosine_scores[i][j]})
#Sort scores in decreasing order pairs = sorted(pairs, key=lambda x: x['score'], reverse=True)
for pair in pairs[0:10]: i, j = pair['index'] print("{} \t\t {} \t\t Score: {:.4f}".format(sentences[i], sentences[j], pair['score']))
1 2 3 4 5 6 7 8 9 10 11
The new movie is awesome The new movie is so great Score: 0.9283 The cat sits outside The cat plays in the garden Score: 0.6855 I love pasta Do you like pizza? Score: 0.5420 I love pasta The new movie is awesome Score: 0.2629 I love pasta The new movie is so great Score: 0.2268 The new movie is awesome Do you like pizza? Score: 0.1885 A man is playing guitar A woman watches TV Score: 0.1759 The new movie is so great Do you like pizza? Score: 0.1615 The cat plays in the garden A woman watches TV Score: 0.1521 The cat sits outside The new movie is awesome Score: 0.1475
Sentence-BERT Sentence Embeddings using Siamese BERT-Networks