ELMo(Deep contextualized word representations)
引入了新的深度考虑上下文的词语表示,模型考虑了两个方面:(1)词语的复杂特性,包括语法和语义,(2)在语境中的不同含义。模型使用了深度双向语言模型,并且在大预料库上做了预训练。这个模型可以很方便地和现有的模型结合,并且在NLP的6个任务上取得了SOTA。作者还揭露了预训练网络的深层构件是关键,这使得下游模型能够混合不同类型的半监督信号。
3 ELMo: Embeddings from Language Models
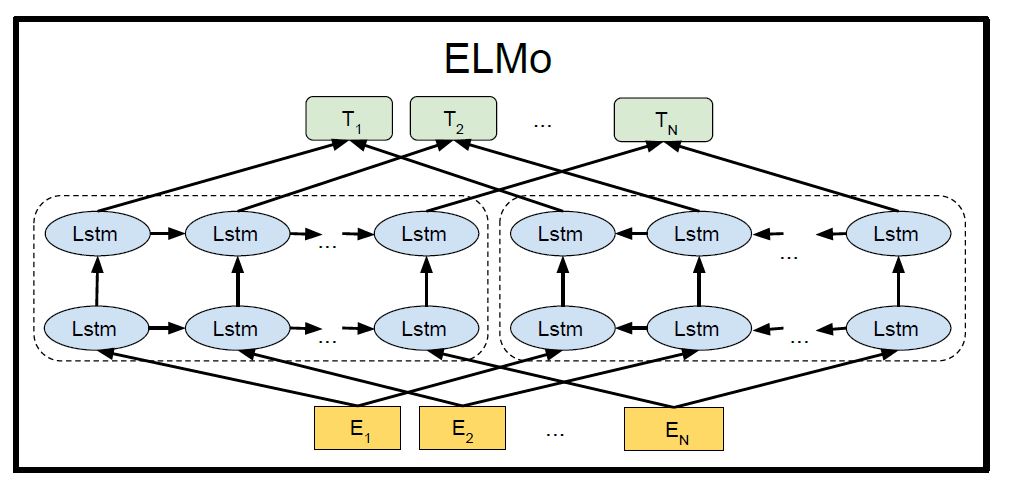
模型的整体机构如上所示,由左右两个单向的多层LSTM网络构成,左边为正向,右边为反向。
3.1 Bidirectional language models(预训练)
假定一个句子有$N$个token,分别为$(t_1,t_2,…,t_N)$,正向的语言模型的句子概率为:
反向的语言模型的句子概率为:
得到正向和反向的语言后,将其结合可以得到双向的语言模型,这里取对数表示为:
其中$\Theta_x$为token表示的参数,$\Theta_s$为softmax层的参数,$\overrightarrow{\Theta}_{LSTM}$表示前向语言模型的参数,$\overleftarrow{\Theta}_{LSTM}$表示反向语言模型的参数。
3.2 ELMo(如何表示词向量)
得到$L$层的预训练双向深度语言模型后,对于token $t_k$,一共包含了$2L+1$个相关的表示,集合如下
注意$h_{k,0}^{LM}=x_{k}^{LM},h_{k,j}^{LM}=[\overrightarrow{h^{LM}_{k,j}};\overleftarrow{h^{LM}_{k,j}}]$,其中$x_{k}^{LM}$为token表示,$\overrightarrow{h^{LM}_{k,j}},\overleftarrow{h^{LM}_{k,j}}$分别为正反向语言模型的表示
对于下游任务,需要将$2L+1$个表示压缩到一个向量$ELmo_k^{task}$,最简单的做法是只取顶层的表示,即
更加通用的做法为线形组合输出,如下图,公式表达为
其中$\gamma^{task}$用于缩放向量,$s_{j}^{task}$表示权重,通过下游任务学习。
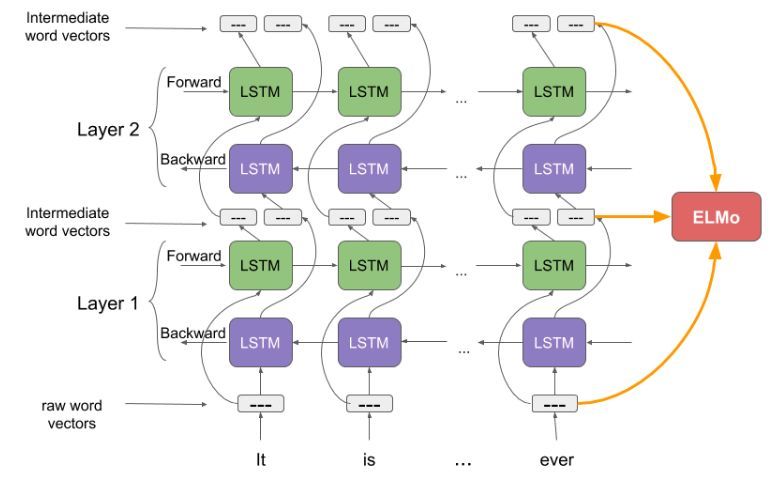
3.3 Using biLMs for supervised NLP tasks(fine tune)
对于下游任务模型,可以得到不考虑上下文的静态词向量$x_k$和考虑上下文的向量表示$h_k$
对于一部分任务,将$x_k$和$ ELMo_k^{task}$ 拼接作为下游任务的特征:$[x_k;ELMo_k^{task}]$
对于一部分任务,将 $h_k$和 $ ELMo_k^{task}$ 拼接可提升效果:$[h_k;ELMo_k^{task}]$
参考
https://blog.csdn.net/linchuhai/article/details/97170541
https://zhuanlan.zhihu.com/p/63115885
ELMo(Deep contextualized word representations)

