gpt
GPT三部曲宣告NLP的“预训练+微调”时代的崛起和走向辉煌。
原文分别为:
《Improving Language Understanding by Generative Pre-Training》
《Language Models are Unsupervised Multitask Learners》
《Language Models are Few-Shot Learners》
1.GPT1
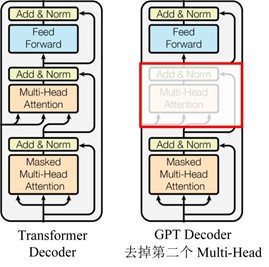
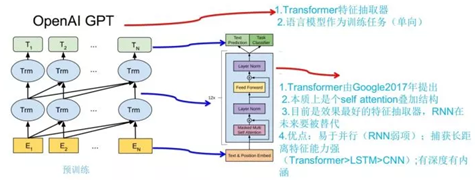
模型的整体结构如上图所示。使用过程过程分为两步:第一步预训练,利用大量语料学习得到high-capacity的语言模型;第二步是fine_tuning,利用标签数据使其拟合到特定任务。
1.1 Unsupervised pre-training
作者将transformer decoder中Encoder-Decoder Attention层去掉后作为基本单元,然后多层堆叠作为语言模型的主体,然后将输出经过一个softmax层,来得到目标词的输出分布:
其中$U=\{u_{-k},…,u_{-1}\}$ 是预测词$u $前$k$个token的独热编码序列,$n$是模型的层数,$W_e$是token embedding matrix,$W_p$是position embedding matrix。
给定一个无监督的语料库$\mathcal{U}$,use a standard language modeling objective to maximize the following likelihood
其中$k$ 是上下文窗口大小。
1.2 Supervised fine-tuning
对于数据集$\mathcal{C}$,有数据$(x^1,x^2,…,x^m,y)$
其中$W_y$为全连接层的参数
作者发现,使用语言模型来辅助监督学习进行微调,有两个好处:
- 提高监督模型的泛化能力;
- 加速收敛。
所以,最终下游使用的监督模型损失函数为:
1.3 Task-specific input transformations
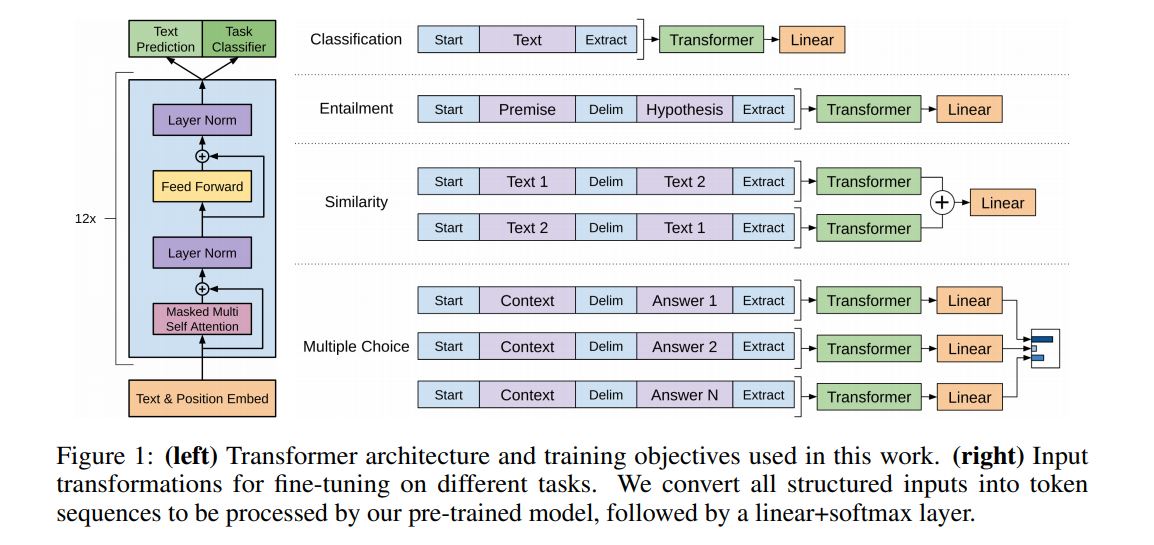
所有的输入文本都会加上开始和结合token$(s),(e)$
分类
分类过程可如上1.2,输入表示为$[(s);Context;(e)]$
文本蕴含
将输入拼接成$[(s); premise; ($) ; hypothesis ; (e)]$
相似度
由于文本相似度与两个比较文本的前后顺序没有关系,因此将两种文本顺序都考虑进来,如上图所示
问答与常识推理
假设文档为$z$,问题为$q$,一系列答案为$\{a_k\}$,将其输入表示为$[(s); z; q; ($); a_k;(e)]$,然后多个回答组合的形式,如上图。
2.GPT2
总结就是:多任务预训练+超大数据集+超大规模模型。通过一个超大数据集涵盖NLP的大多任务,然后使用一个超大规模模型进行多任务预训练,使其无需任何下游任务的finetune就可以做到多个NLP任务的SOTA。举个例子,拿高考为例,人的智力和脑容量可以理解为参数大小,由于个体差异,可以将不同的学生理解为不同参数量的模型,卷子可以理解为数据集,不同的学科可以理解为不同任务。GPT2有点类似学霸,就是有超高的智力和脑容量,然后刷大量不同学科的题目,因此对高考这个多任务的下游任务就可以取得好成绩。
GPT2相对于GPT1有哪些不同呢?
GPT2去掉了fine-tuning:不再针对不同任务分别进行微调建模,模型会自动识别出来需要做什么任务。这就好比一个人博览群书,你问他什么类型的问题,他都可以顺手拈来,GPT2就是这样一个博览群书的模型。
超大数据集:WebText,该数据集做了一些简单的数据清理,并且实验结果表明目前模型仍然处于一个欠拟合的情况。
增加网络参数:GPT2将Transformer堆叠的层数增加到48层,隐层的维度为1600,参数量更是达到了15亿。15亿什么概念呢,Bert的参数量也才只有3亿哦~当然,这样的参数量也不是说谁都能达到的,这也得取决于money的多少啊~
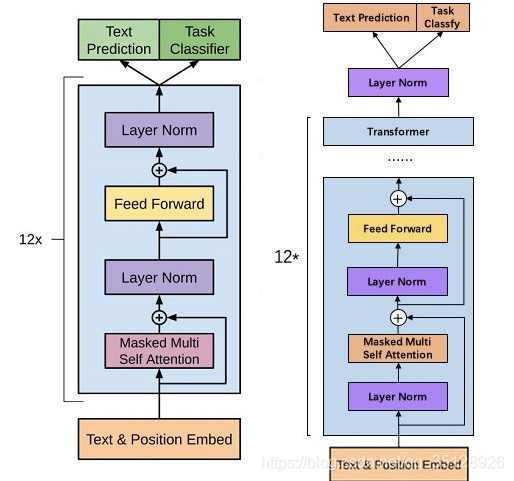
调整transformer:将layer normalization放到每个sub-block之前,并在最后一个transformer后再增加一个layer normalization,如下图。
输入表示:GPT2采用了BPE这种subword的结构作为输入
其他:GPT2将词汇表数量增加到50257个;最大的上下文大小 (context size) 从GPT的512提升到了1024 tokens;batchsize增加到512。
GPT2的输入是完全的文本,什么提示都不加吗?
当然不是,它也会加入提示词,比如:$TL;DR:$,GPT2模型就会知道是做摘要工作了,输入的格式就是 $文本+TL;DR:$,然后就等待输出就行了~
3.GPT3
GPT3,这是一种具有1750亿个参数的超大规模模型,比GPT2大100倍,感觉真是进入算力时代了。距离个人用户太远了,就不深挖了。
参考
https://zhuanlan.zhihu.com/p/146719974
https://zhuanlan.zhihu.com/p/125139937
https://www.cnblogs.com/yifanrensheng/p/13167796.html#_label1_0
https://www.jianshu.com/p/96c5d5d5c468
https://blog.csdn.net/qq_35128926/article/details/111399679
https://zhuanlan.zhihu.com/p/96791725
https://terrifyzhao.github.io/2019/02/18/GPT2.0%E8%AE%BA%E6%96%87%E8%A7%A3%E8%AF%BB.html

