ConSERT A Contrastive Framework for Self-Supervised Sentence Representation Transfer
https://arxiv.org/abs/2105.11741
https://tech.meituan.com/2021/06/03/acl-2021-consert-bert.html
1.背景
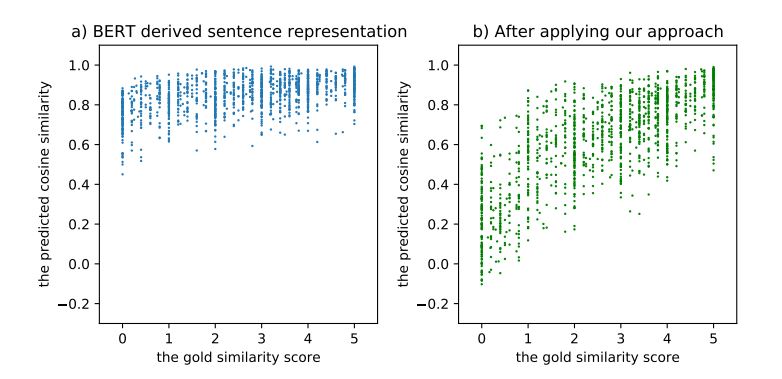
首先,BERT其自身导出的句向量(不经过Fine-tune,对所有词向量求平均)会出现“坍缩(Collapse)”现象,即所有的句子都倾向于编码到一个较小的空间区域内,如图。为了解决这个问题,将对比学习结合到finetune过程,借助无标签数据来提升模型的能力。
2.原理
给定一个类似BERT的预训练语言模型$\textbf{M}$,以及从目标领域数据分布中收集的无标签文本语料库$\mathcal{D}$,我们希望通过构建自监督任务在$\mathcal{D}$上对$\textbf{M}$进行Fine-tune,使得Fine-tune后的模型能够在目标任务(文本语义匹配)上表现最好。
2.1 整体框架
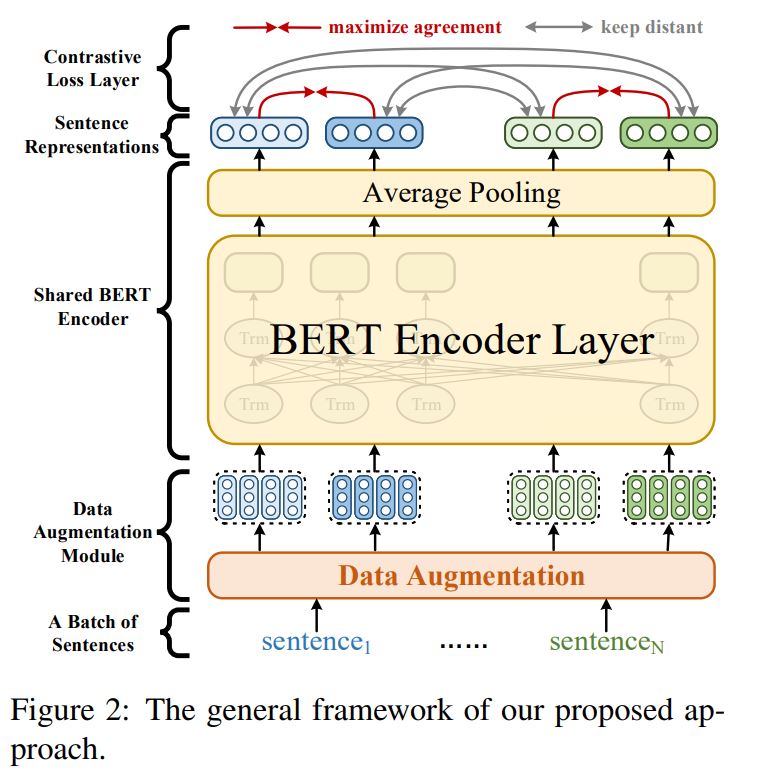
模型整体结构如上图所示,主要由三个部分组成
A data augmentation module that generates different views for input samples at the token embedding layer.
A shared BERT encoder that computes sentence representations for each input text. During training, we use the average pooling of the token embeddings at the last layer to obtain sentence representations.
A contrastive loss layer on top of the BERT encoder. It maximizes the agreement between one representation and its corresponding version that is augmented from the same sentence while keeping it distant from other sentence representations in the same batch.
对于任意一个句子输入$x$,得到其对应的两个增强向量$e_i=T_1(x),e_j=T_2(x),e_i,e_j\in \mathbb{R}^{L\times d}$,然后经过shared BERT encoder编码为$r_i,r_j$,其中$T_1,T_2$为不同的数据增强方式,$L$为句子$x$的长度,$d$为隐藏单元的数量。对于每个train step,从$\mathcal{D}$随机选取$N$个样本作为mini-batch,然后得到$2N$个增强样本,使用NT-Xent构造loss为
其中$sim(.)$为余弦相似度计算,$\tau$表示temperature,是一个超参数,实验中取0.1,$\mathbb{1}$是指示器,当$k=i$时,值为0。上式分子为正样本,分母为全部(但是基本为负样本,所以可以看成负样本),所以loss变小就是让分子变大,分母变小,也就是让正样本相似度变大,负样本相似度变小
2.2 数据增强策略
显式生成增强样本的方法包括:回译、同义词替换、意译等,然而这些方法一方面不一定能保证语义一致。所以考虑了在Embedding层隐式生成增强样本的方法。
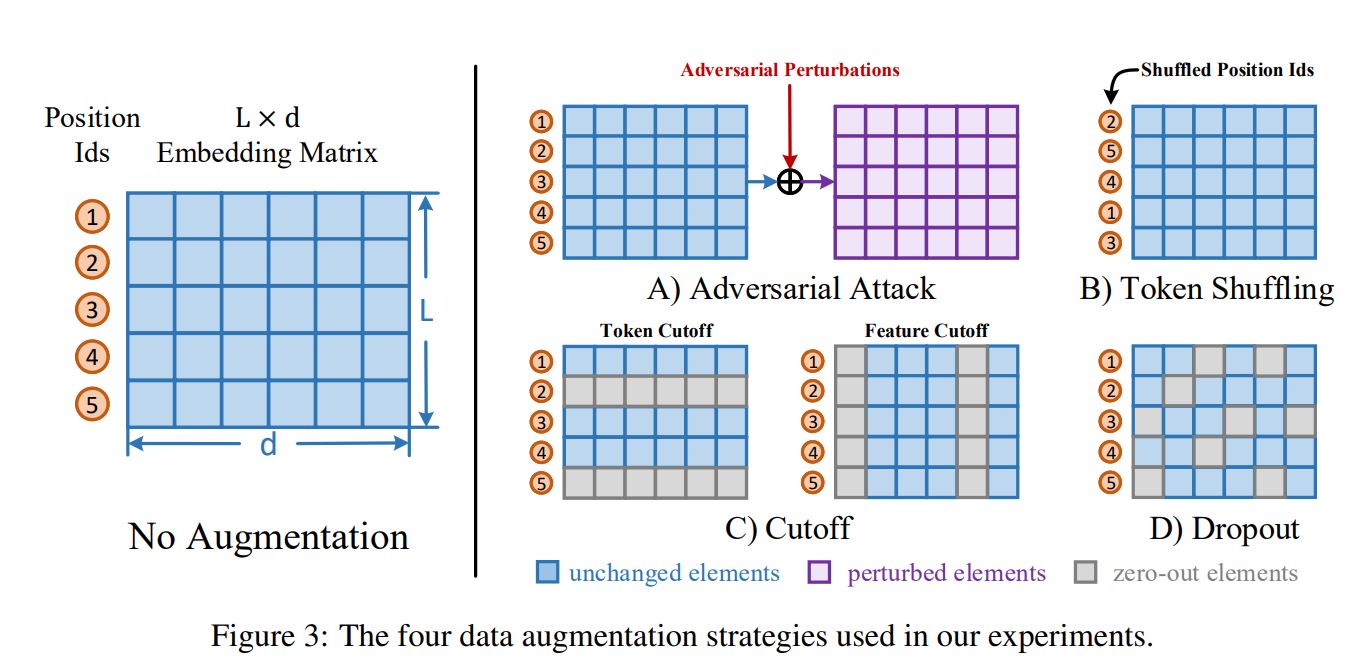
对抗攻击(Adversarial Attack):这一方法通过梯度反传生成对抗扰动,将该扰动加到原本的Embedding矩阵上,就能得到增强后的样本。由于生成对抗扰动需要梯度反传,因此这一数据增强方法仅适用于有监督训练的场景。
打乱词序(Token Shuffling):这一方法扰乱输入样本的词序。由于Transformer结构没有“位置”的概念,模型对Token位置的感知全靠Embedding中的Position Ids得到。因此在实现上,我们只需要将Position Ids进行Shuffle即可。
裁剪(Cutoff)
:又可以进一步分为两种:
- Token Cutoff:随机选取Token,将对应Token的Embedding整行置为零。
- Feature Cutoff:随机选取Embedding的Feature,将选取的Feature维度整列置为零。
Dropout:Embedding中的每一个元素都以一定概率置为零,与Cutoff不同的是,该方法并没有按行或者按列的约束。
2.3 融合监督信号
除了无监督训练以外,作者给出3种进一步融合监督信号的策略,以NLI任务为例:
Joint training (joint):
Supervised training then unsupervised transfer (sup-unsup):
first train the model with $\mathcal{L}_{ce}$on NLI dataset, then use $\mathcal{L}_{con}$to finetune it on the target dataset.
Joint training then unsupervised transfer (joint-unsup):
first train the model with the $\mathcal{L}_{joint}$on NLI dataset, then use $\mathcal{L}_{con }$to fine-tune it on the target dataset.
3.定性分析
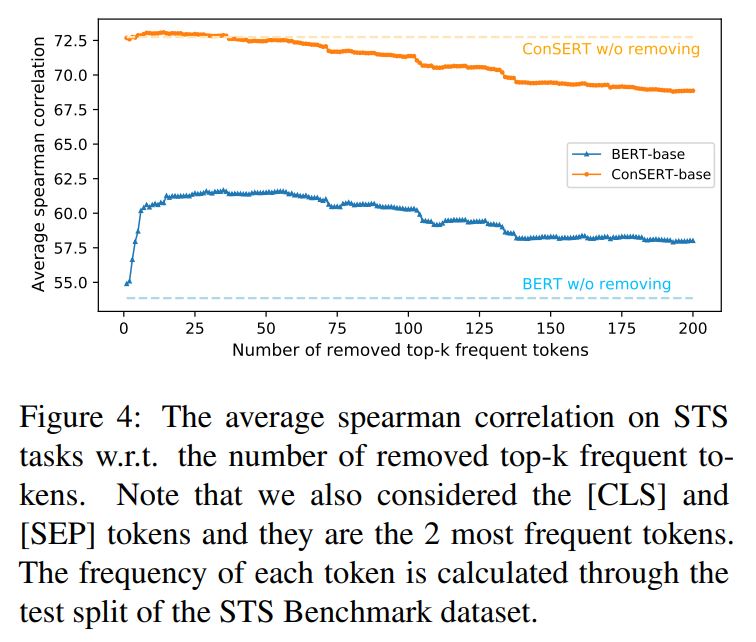
后又发现BERT句向量表示的坍缩和句子中的高频词有关。具体来说,当通过平均词向量的方式计算句向量时,那些高频词的词向量将会主导句向量,使之难以体现其原本的语义。当计算句向量时去除若干高频词时,坍缩现象可以在一定程度上得到缓解(如图2蓝色曲线所示)。
4 实验结果
4.1 Unsupervised Results
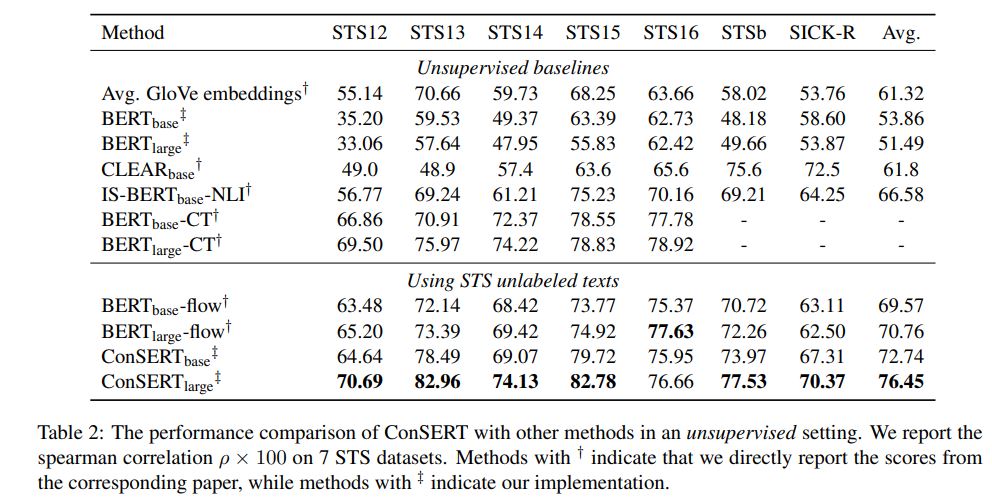
4.2 Supervised Results
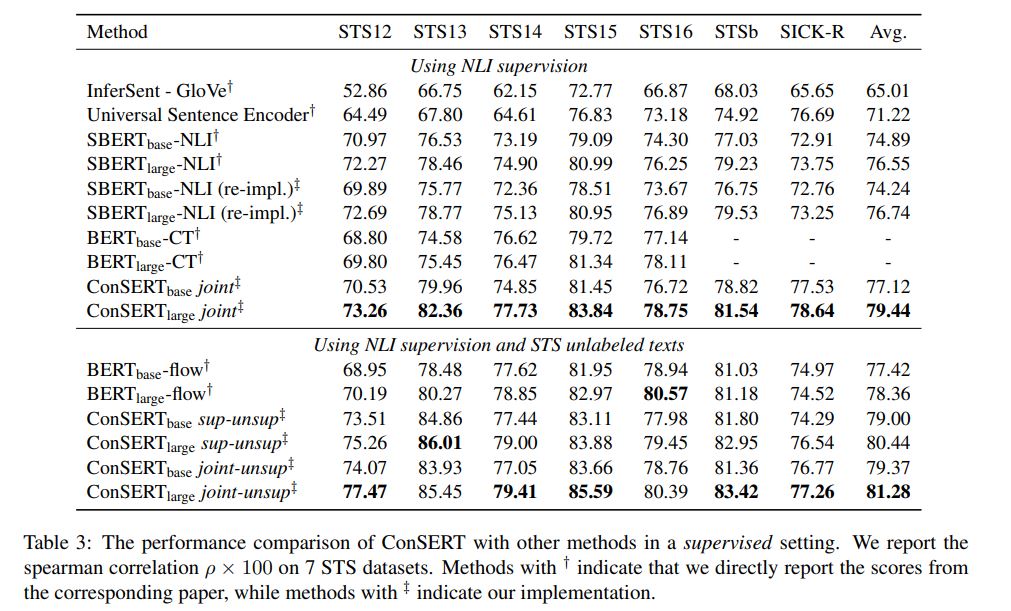
ConSERT A Contrastive Framework for Self-Supervised Sentence Representation Transfer

