RoBERTa A Robustly Optimized BERT Pretraining Approach
1.和BERT比较
在结构上和原版BERT没有差异,主要的改动在于:
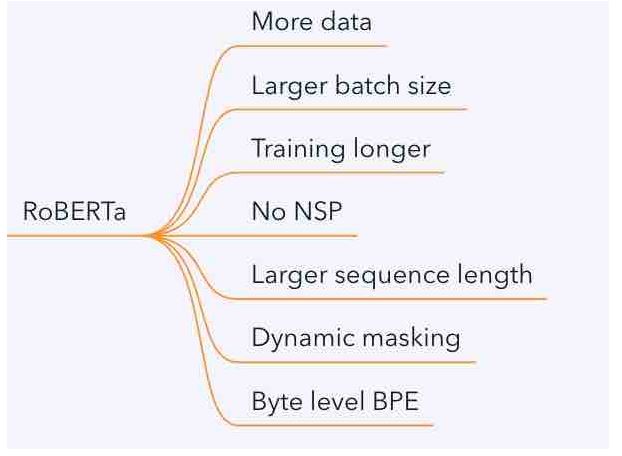
2.改动分析
2.1 Static vs. Dynamic Masking
static masking: 原本的BERT采用的是static mask的方式,就是在create pretraining data中,先对数据进行提前的mask
dynamic masking: 每一次将训练example喂给模型的时候,才进行随机mask。
结果对比:
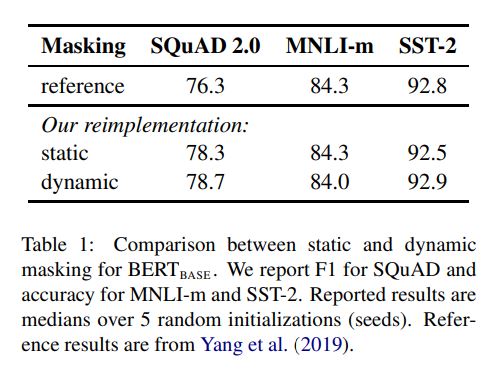
结论:动态占优
2.2 Model Input Format and Next Sentence Prediction
做了结果对比试验,结果如下:
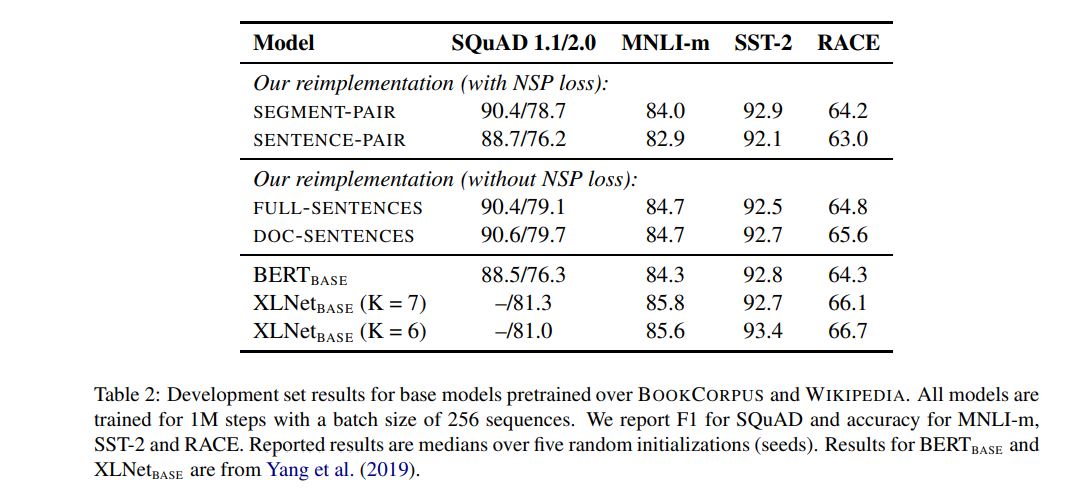
结论:
Model Input Format:
1.find that using individual sentences hurts performance on downstream tasks
Next Sentence Prediction:
1.removing the NSP loss matches or slightly improves downstream task performance
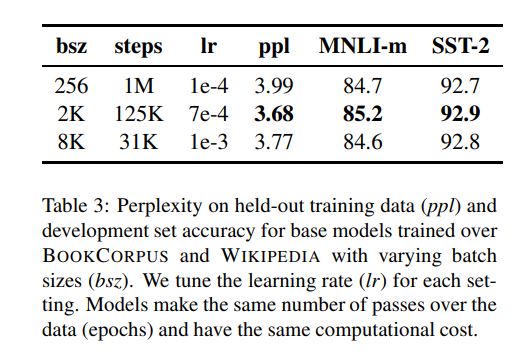
2.3 Training with large batches
2.4 Text Encoding
采用BBPE而不是wordpiece
3 常见问题
1 roberta tokenizer 没有token_type_ids?
roberta 取消了NSP,所以不需要segment embedding 也就不需要token_type_ids,但是使用的时候发现中文是有token_type_ids的,英文没有token_type_ids的。没有token_type_ids,两句话怎么区别,分隔符sep还是有的,只是没有segment embedding
2 使用避坑
https://blog.csdn.net/zwqjoy/article/details/107533184
https://hub.fastgit.org/ymcui/Chinese-BERT-wwm
参考
https://zhuanlan.zhihu.com/p/103205929
https://zhuanlan.zhihu.com/p/143064748
RoBERTa A Robustly Optimized BERT Pretraining Approach

