Embedding based Product Retrieval in Taobao Search
https://arxiv.org/pdf/2106.09297.pdf
http://xtf615.com/2021/10/07/taobao-ebr/
1.INTRODUCTION
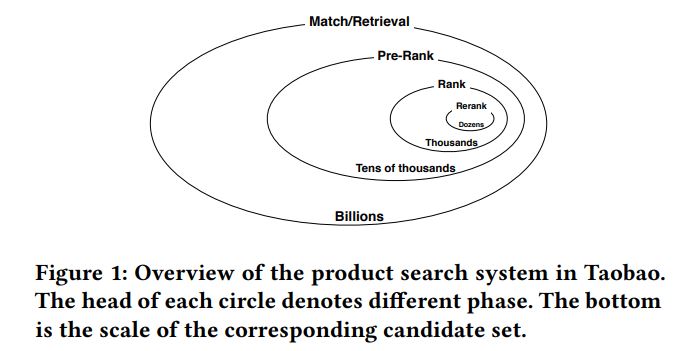
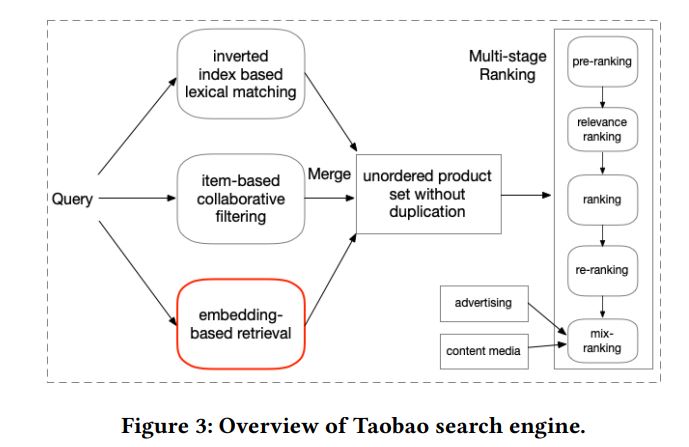
框架是搜索系统主流的结构,即匹配/检索,粗排,精排,重排。
2.RELATED WORK
2.1 Deep Matching in Search
fall into two categories: representation-based learning and interaction-based learning.
Other than semantic and relevance matching, more complex factors/trade-offs, e.g., user personalization [2, 3, 10] and retrieval efficiency [5], need to be considered when applying deep models to a large-scale online retrieval system.
2.2 Deep Retrieval in Industry Search
Representation-based models with an ANN (approximate near neighbor) algorithm have become the mainstream trend to efficiently deploy neural retrieval models in industry.
3 MODEL
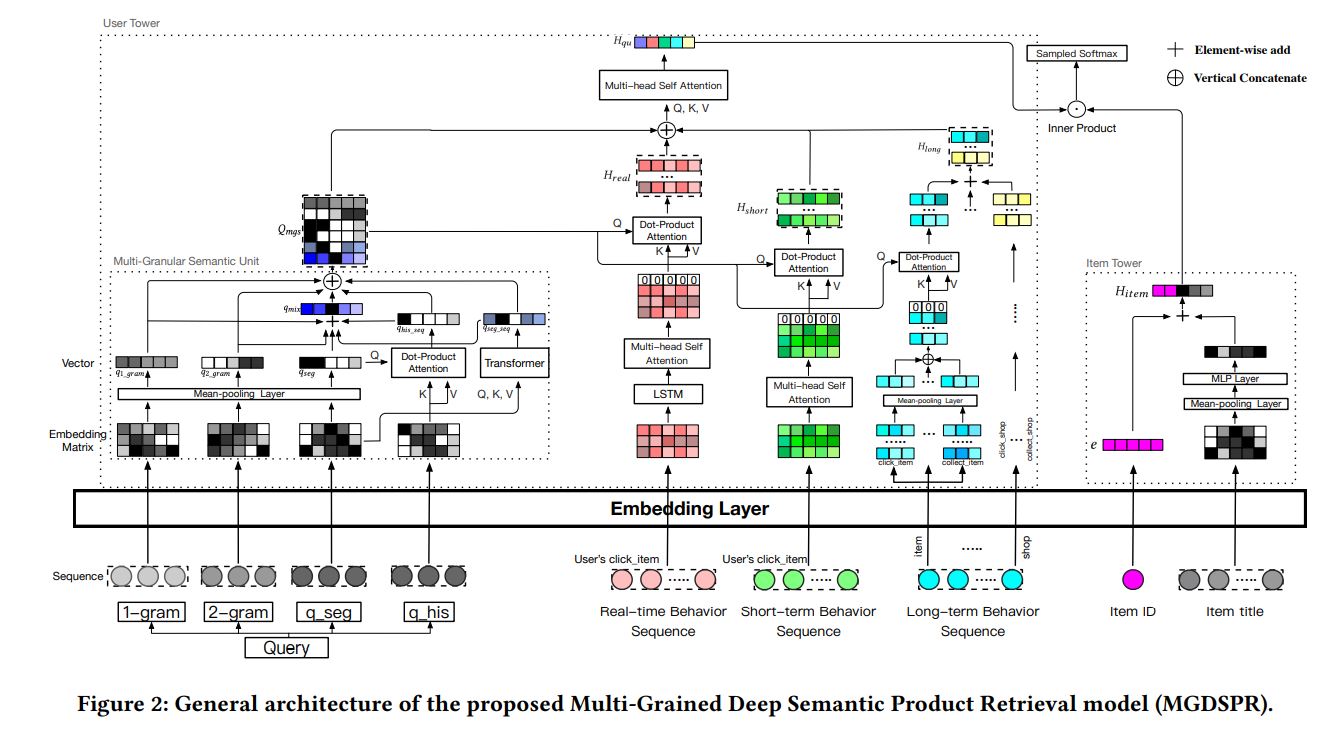
整体结构入下:
3.1 Problem Formulation
$\mathcal{U}=\{u_1,…,u_u,…u_N\}$表示$N$个用户,$\mathcal{Q}=\{q_1,…,q_u,…q_N\}$表示与用户对应的$N$个query,$\mathcal{I}=\{i_1,…,i_u,…i_M\}$表示$M$个商品。将用户$u$的历史行为根据时间分成3个部分:1.real-time,before
the current time step,$\mathcal{R}^u=\{i_1^u,…,i_t^u,…i_T^u\}$ 2.short-term, before $\mathcal{R}$ and within ten days,$\mathcal{S}^u=\{i_1^u,…,i_t^u,…i_T^u\}$ 3.long-term sequences,before $\mathcal{S}$ and within one month,$\mathcal{L}^u=\{i_1^u,…,i_t^u,…i_T^u\}$ ,$T$为时间长度。任务可以定义为:
其中$\mathcal{F}(\cdot),\phi(\cdot),\varphi(\cdot)$分别表示scoring function, query and behaviors encoder, and item encoder
3.2 User Tower
3.2.1 Multi-Granular Semantic Unit
挖掘query的语义,原始输入包含当前query和历史query
没有说明为什么这么设计,感觉就是工程试验的结论。有个疑问,直接用BERT等深度语言模型来挖掘query的语义不好吗?
query表示为$q_u=\{w_1^u,…,w_n^u\}$,例如{红色,连衣裙},$w_u=\{c_1^u,…,c_m^u\}$,例如{红,色},history query表示为$q_{his}=\{q_1^u,…,q_k^u\} $,例如{绿色,半身裙,黄色,长裙},其中$w_n \in \mathbb{R}^{1\times d},c_m \in \mathbb{R}^{1\times d},q_k \in \mathbb{R}^{1\times d}$
其中𝑇𝑟𝑚,𝑚𝑒𝑎𝑛_𝑝𝑜𝑜𝑙𝑖𝑛𝑔, and 𝑐𝑜𝑛𝑐𝑎𝑡 denote the Transformer ,average, and vertical concatenation operation, respectively
3.2.2 User Behaviors Attention
其中$W_f$是embedding matrix,$x_i^{f}$是one-hot vector, $\mathcal{F}$是side information (e.g., leaf category, first-level category, brand and,shop)
real-time sequences
User’s click_item
short-term sequences
User’s click_item
long-term sequence
$\mathcal{L}^u$由四个部分构成,分别为$\mathcal{L}^{u}_{item},\mathcal{L}^{u}_{shop},\mathcal{L}^{u}_{leaf},\mathcal{L}^{u}_{brand}$,每个部分包含3个动作,分别为click,buy,collect。
3.2.3 Fusion of Semantics and Personalization
3.3 Item Tower
For the item tower, we experimentally use item ID and title to obtain the item representation 𝐻𝑖𝑡𝑒𝑚.Given the representation of item 𝑖’s ID, $e_i \in \mathbb{R}^{1\times d}$ , and its title segmentation result $T_i=\{w_1^{i},…,w_N^{i}\}$
where $W_t$ is the transformation matrix. We empirically find that applying LSTM [12] or Transformer [27] to capture the context of the title is not as effective as simple mean-pooling since the title is stacked by keywords and lacks grammatical structure.
3.4 Loss Function
adapt the softmax cross-entropy loss as the training objective
where $\mathcal{F},I,i^+,q_u$denote the inner product, the full item pool, the item tower’s representation $H_{item}$, and the user tower’s representation $H_{qu}$, respectively.
3.4.1 Smoothing Noisy Training Data
the softmax function with the temperature parameter $\tau$ is defined as follows
If 𝜏->0, the fitted distribution is close to one hot distribution,If 𝜏->∞, the fitted distribution is close to a uniform distribution
3.4.2 Generating Relevance-improving Hard Negative Samples
We first select the negative items of $i^-$ that have the top-𝑁 inner product scores with $q_u $ to form the hard sample set $I_{hard}$
其中$\alpha\in \mathbb{R}^{N\times1}$is sampled from the uniform distribution 𝑈 (𝑎, 𝑏) (0 ≤ 𝑎 < 𝑏 ≤ 1).
Embedding based Product Retrieval in Taobao Search

