Felix Flexible Text Editing Through Tagging and Insertion
google继lasertagger之后的又一篇text edit paper
In contrast to conventional sequence-to-sequence (seq2seq) models, FELIX is efficient in low-resource settings and fast at inference time, while being capable of modeling flexible input-output transformations. We achieve this by decomposing the text-editing task into two sub-tasks: tagging to decide on the subset of input tokens and their order in the output text and insertion to in-fill the missing tokens in the output not present in the input.
1 Introduction
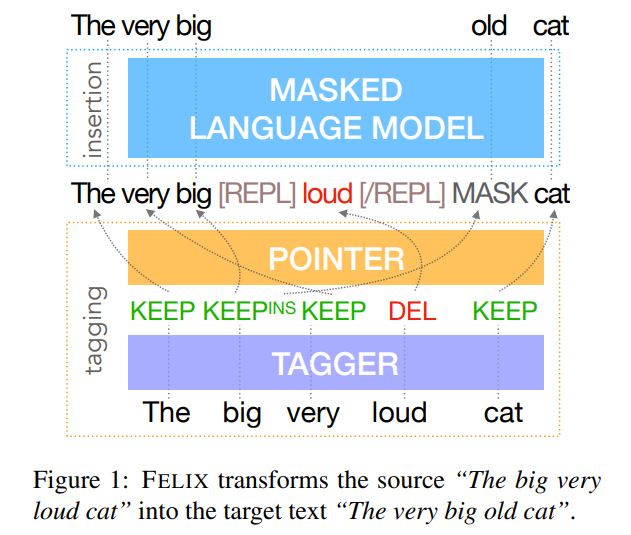
In particular, we have designed FELIX with the following requirements in mind: Sample efficiency, Fast inference time, Flexible text editing
2 Model description
FELIX decomposes the conditional probability of generating an output sequence $y$ from an input
$x$ as follows:
2.1 Tagging Model
trained to optimize both the tagging and pointing loss:
Tagging :
tag sequence $\textbf{y}^t$由3种tag组成:$KEEP$,$DELETE$,$INSERT (INS)$
Tags are predicted by applying a single feedforward layer $f$ to the output of the encoder $\textbf{h}^L$ (the source sentence is first encoded using a 12-layer BERT-base model). $\textbf{y}^t_i=argmax(f(\textbf{h}^L_i))$
Pointing:
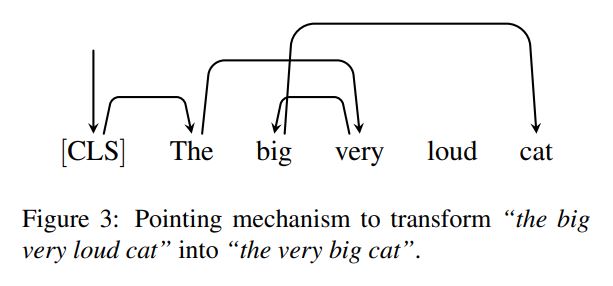
Given a sequence $\textbf{x}$ and the predicted tags $\textbf{y}^t$ , the re-ordering model generates a permutation $\pi$ so that from $\pi$and $\textbf{y}^t$ we can reconstruct the insertion model input $\textbf{y}^m$. Thus we have:
Our implementation is based on a pointer network. The output of this model is a series of predicted pointers (source token → next target token)
The input to the Pointer layer at position $i$:
其中$e(\textbf{y}_i^t)$is the embedding of the predicted tag,$e(\textbf{p}_i)$ is the positional embedding
The pointer network attends over all hidden states, as such:
其中$\textbf{h}_i^{L+1}$ as $Q $, $\textbf{h}_{\pi(i)}^{L+1}$ as $K$
When realizing the pointers, we use a constrained beam search
2.2 Insertion Model

To represent masked token spans we consider two options: masking and infilling. In the former case the tagging model predicts how many tokens need to be inserted by specializing the $INSERT$ tag into $INS_k$, where $k$ translates the span into $ k$ $MASK$ tokens. For the infilling case the tagging model predicts a generic $INS$ tag.
Note that we preserve the deleted span in the input to the insertion model by enclosing it between $[REPL]$ and $[/REPL]$ tags.
our insertion model is also based on a 12-layer BERT-base and we can directly take advantage of the BERT-style pretrained checkpoints.
参考
Felix Flexible Text Editing Through Tagging and Insertion
1.Evaluation of Text Generation A Survey
2.text edit
3.LASERTAGGER
4.文本生成评价指标
5.attention seq2seq

