Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting
原文:https://arxiv.org/abs/1907.00235
作者利用transformer做时间序列预测,发现了两个问题,然后提出了改进。一个问题是locality-agnostics,the point-wise dot product self-attention in canonical Transformer architecture is insensitive to local context。另外一个问题是memory bottleneck :space complexity of canonical Transformer grows quadratically with sequence length L, making directly modeling long time series infeasible.为了解决这两个问题,作者提出了convolutional self-attention和LogSparse Transformer。
3.背景
问题定义
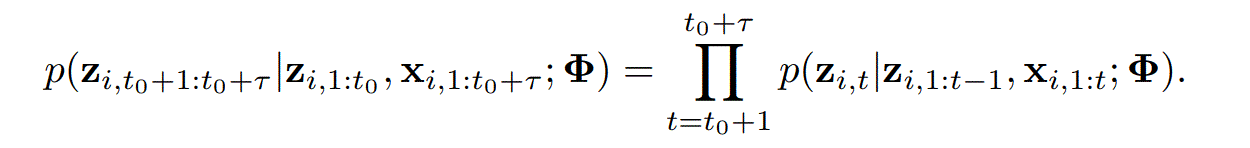
其中$\Phi$是参数,$\textbf{X}$是辅助输入,就是除了观测值以外的输入,$\textbf{Z}_{i,t}$表示序列$i$在时刻$t$的值
为了简化式子,定义了
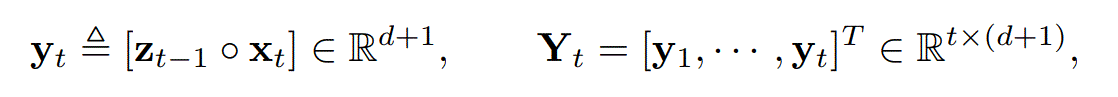
目标就变成了$\textbf{z}_t \sim f(\textbf{Y}_t)$
Transformer
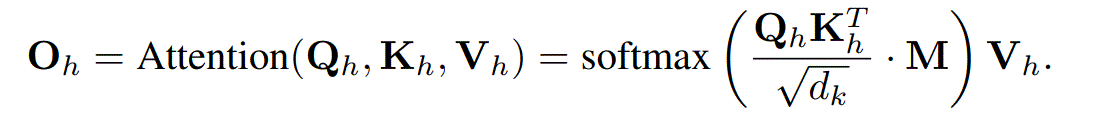
$h$表示某个头,$M$表示mask matrix
4.方法论
4.1 Enhancing the locality of Transformer
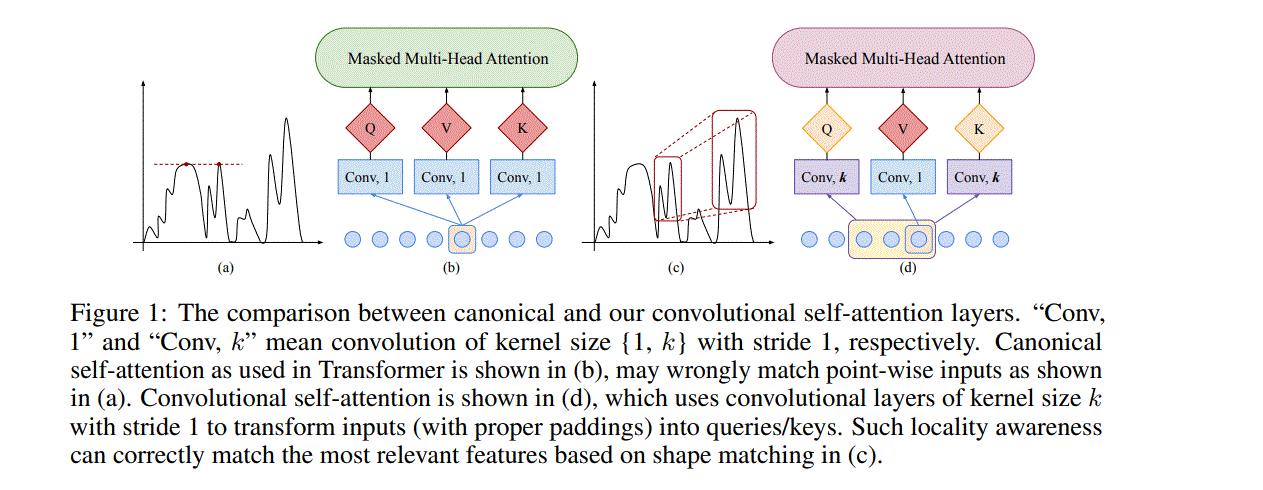
改进思想如上图所示,原版的transformer,利用了point-wise之间的相似度,万一存在异常点,就会造成偏差。改进方向就是将点和点之间的相似度变为local context based,也就是先利用卷积得到local的表示,然后基于local做Q和K的相似度。当卷积核的尺寸为1就退化为原版的transformer。
4.2 Breaking the memory bottleneck of Transformer
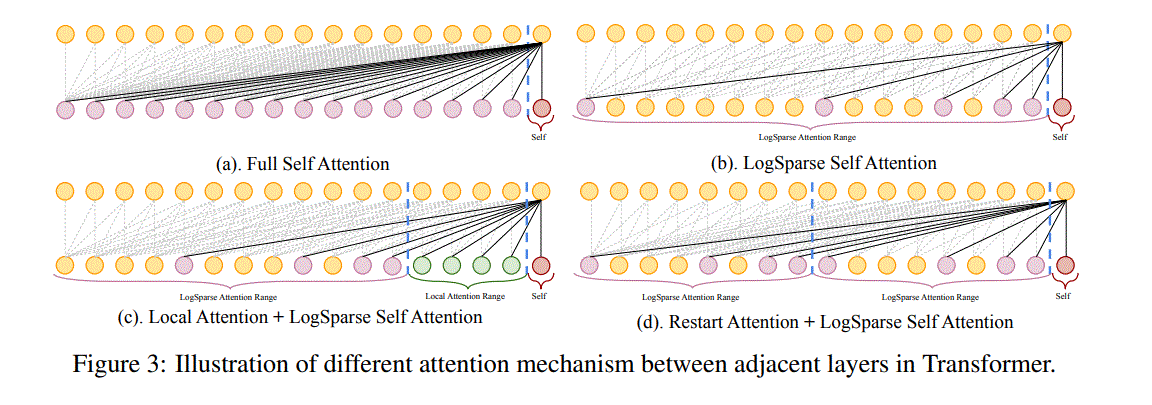
原来的transformer需要$O(L^2)$的空间复杂度,每层每个cell为$O(L)$,每层所有cell为$O(L^2)$,然后堆叠$h$层,$h$为常数,所以为$O(L^2)$,如图(a)。作者提出了LogSparse Transformer,如图(b),空间复杂度为$O(L(logL)^2)$。首先每层每一个cell需要$logL$,每层所有cell就是$LlogL$,然后堆叠$logL$层,最后为$O(L(logL)^2)$。
对于LogSparse Transformer,筛选规则为:
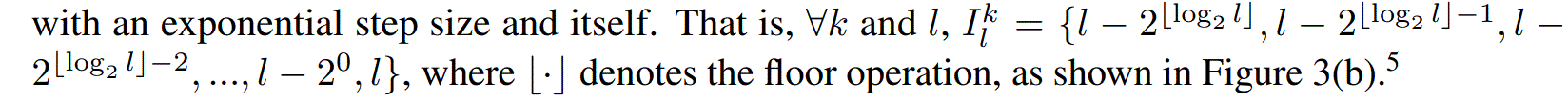
图(c)和图(d)是对(b)的改进。
5.实验
评级指标:p-quantile loss $R_p$ with $p\in(0,1)$
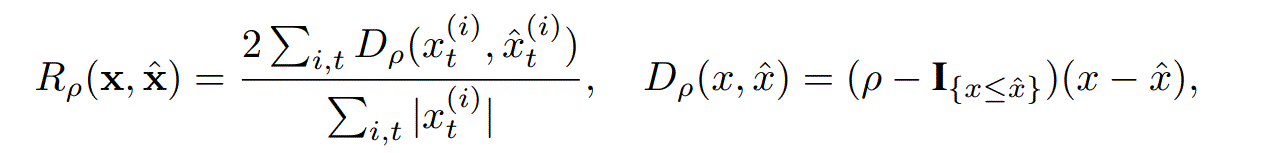
参考
Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting

