shuffle
https://www.cnblogs.com/arachis/p/Spark_Shuffle.html
https://zhuanlan.zhihu.com/p/70331869
https://www.educba.com/spark-shuffle/
https://lmrzero.blog.csdn.net/article/details/106015264?spm=1001.2014.3001.5502
https://blog.csdn.net/zp17834994071/article/details/107887292
https://zhuanlan.zhihu.com/p/431015932
0 shuffle是什么,什么时候shuffle
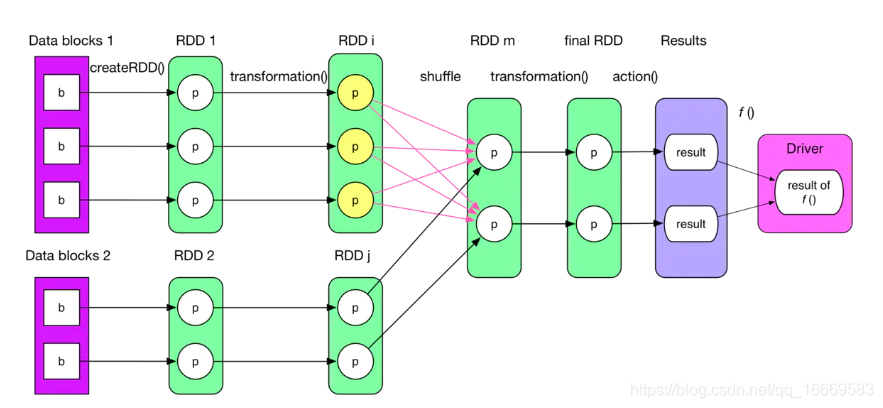
what:多个partition的数据流向一个partition
when:宽依赖会有shuffle
shuffle分为两个阶段:shuffle read , shuffle write
map端-》shuffle read-》 shuffle write-》reduce端
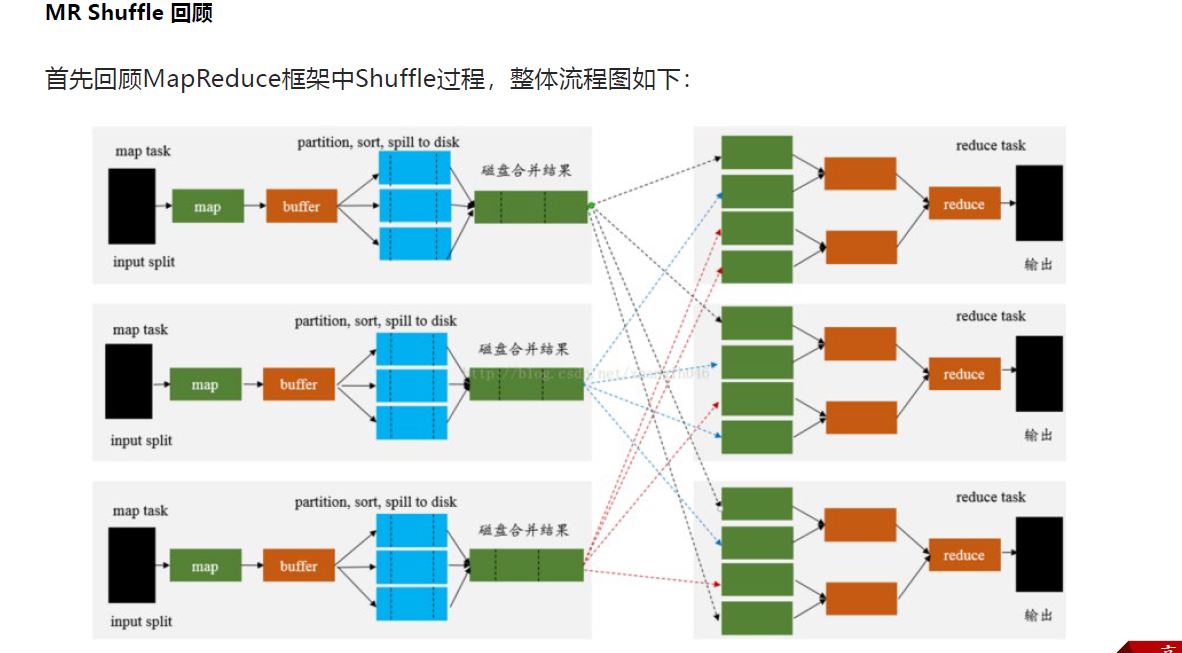
1 mapreduce shuffle
2 spark shuffle
1 简介
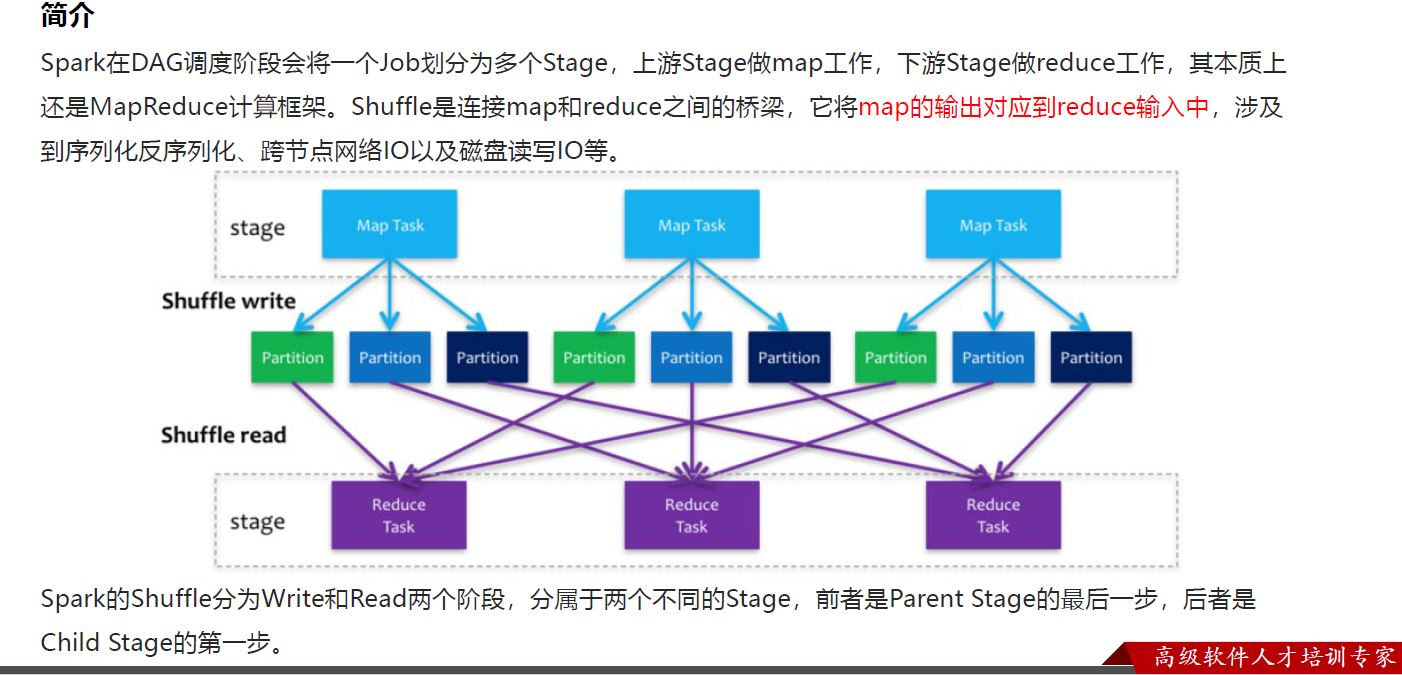
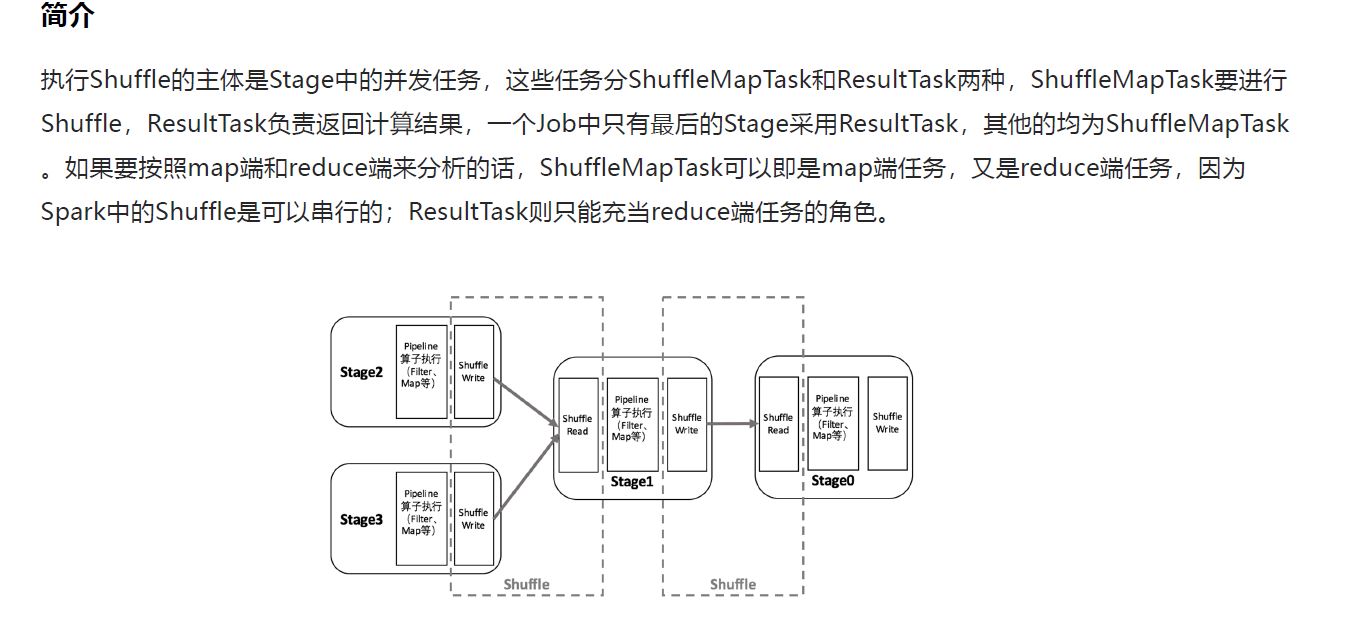
2 分类
https://www.51cto.com/article/703950.html#
过去hash shuffle ,现在sort shuffle
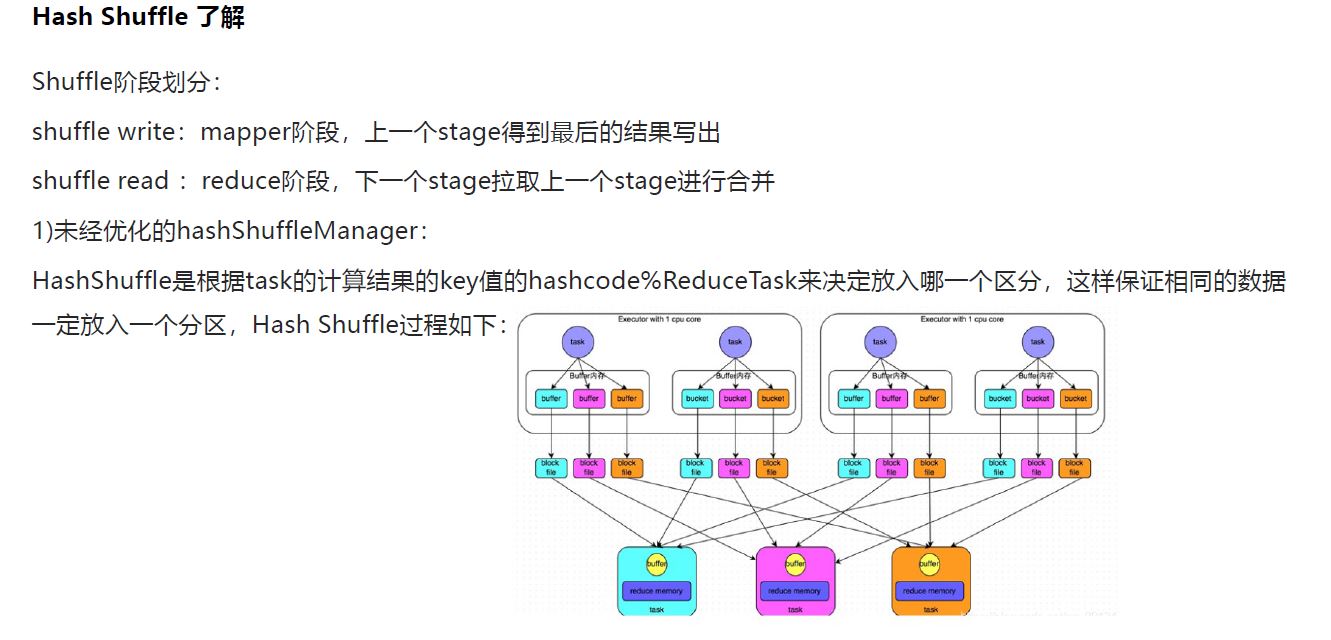
1.Hash Shuffle
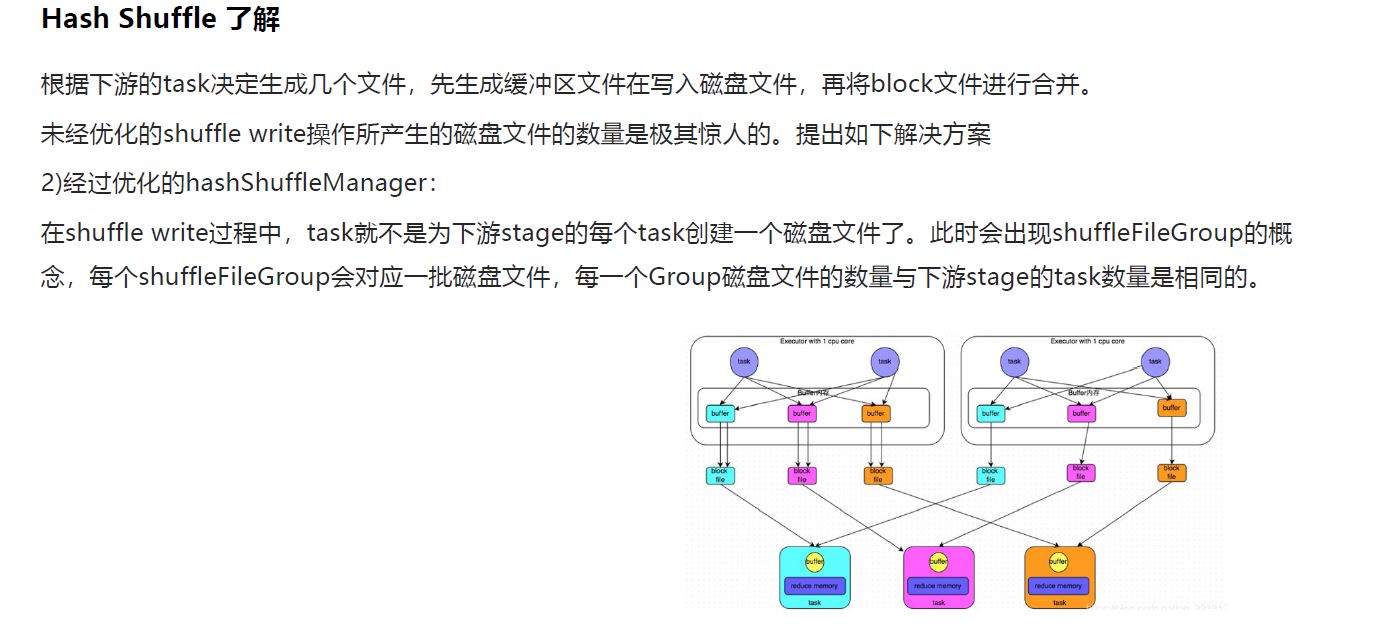

2.Sort Shuffle
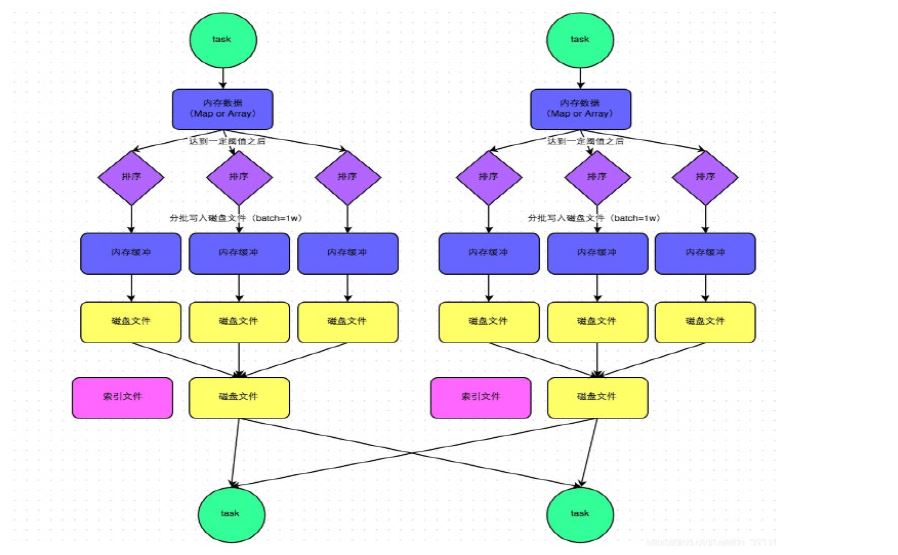
1 普通机制的SortShuffleManager

2 bypass
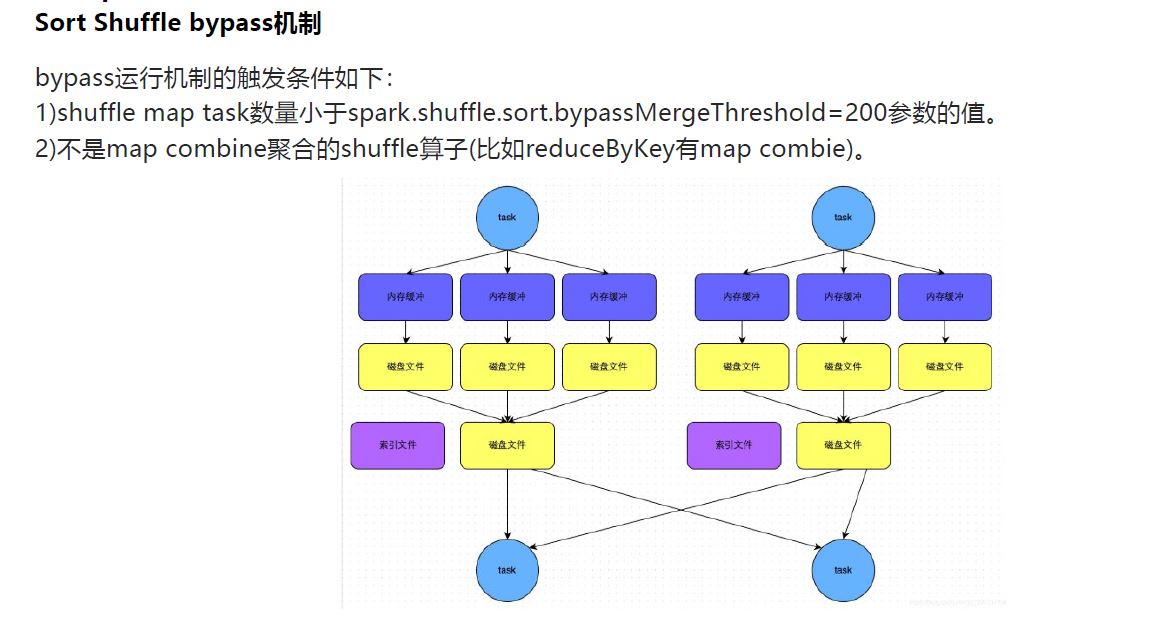
此时task会为每个reduce端的task都创建一个临时磁盘文件,并将数据按key进行hash,然后根据key的hash值,将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的HashShuffleManager是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的HashShuffleManager来说,shuffle read的性能会更好。
3 总结
bypass与普通SortShuffleManager运行机制的不同在于:
第一,磁盘写机制不同;
第二,不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
3 对比
https://www.zhihu.com/question/27643595
4 优化
因此在我们的开发过程中,能避免则尽可能避免使用会进行shuffle的算子,尽量使用非shuffle算子
1 shuffle算子:
https://blog.csdn.net/py_tamir/article/details/95457813
reduceByKey、join、distinct、repartition
2 非shuffle算子
map,flatMap
1.spark oom(out of memory)问题
2.spark资源参数调优
3.Use reduceByKey instead of groupByKey
4.持久化
5.Spark 数据倾斜
6.spark优化

