RDD,DataFrame,Dataset
https://blog.knoldus.com/spark-rdd-vs-dataframes/
https://blog.csdn.net/hellozhxy/article/details/82660610
https://www.cnblogs.com/lestatzhang/p/10611320.html#Spark_16
https://www.jianshu.com/p/77811ae29fdd
https://zhuanlan.zhihu.com/p/379578271
https://spark.apache.org/docs/3.2.0/sql-programming-guide.html#content
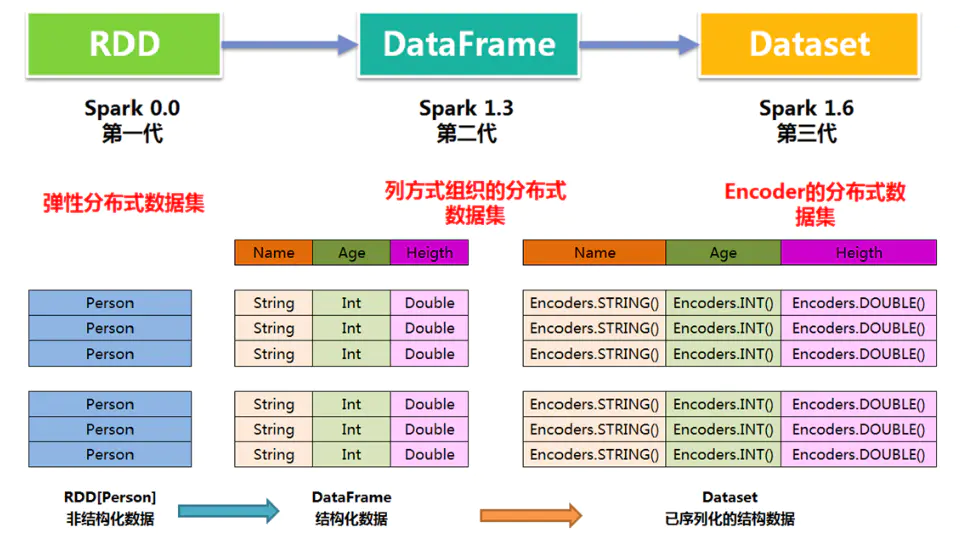
1 DataFrame 和 RDDs 应该如何选择?
DataFrame 和 RDDs 最主要的区别在于一个面向的是结构化数据,一个面向的是非结构化数据
- 如果你的数据是结构化的 (如 RDBMS 中的数据) 或者半结构化的 (如日志),出于性能上的考虑,应优先使用 DataFrame。
- 如果你的数据是非结构化的 (比如流媒体或者字符流),则使用 RDDs,
2 为什么出现Dataset?
1.相比DataFrame,Dataset提供了编译时类型检查,对于分布式程序来讲,提交一次作业太费劲了(要编译、打包、上传、运行),到提交到集群运行时才发现错误,实在是想骂人,这也是引入Dataset的一个重要原因。
2.RDD转换DataFrame后不可逆,但RDD转换Dataset是可逆的(这也是Dataset产生的原因)
注意:
The Dataset API is available in Scala and Java. Python does not have the support for the Dataset API. But due to Python’s dynamic nature, many of the benefits of the Dataset API are already available (i.e. you can access the field of a row by name naturally row.columnName).
RDD,DataFrame,Dataset

