数据划分,rdd分区
https://www.jianshu.com/p/3aa52ee3a802
https://blog.csdn.net/hjw199089/article/details/77938688
https://blog.csdn.net/mys_35088/article/details/80864092
https://blog.csdn.net/dmy1115143060/article/details/82620715
https://blog.csdn.net/xxd1992/article/details/85254666
https://blog.csdn.net/m0_46657040/article/details/108737350
https://blog.csdn.net/heiren_a/article/details/111954523
https://blog.csdn.net/u011564172/article/details/53611109
https://blog.csdn.net/qq_22473611/article/details/107822168
https://www.jianshu.com/p/3aa52ee3a802
1 application,job,stage,task,record
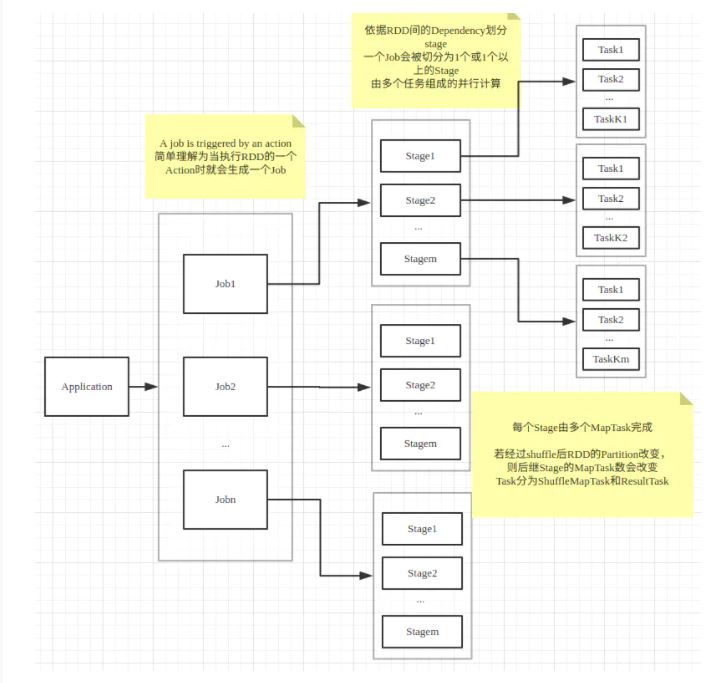
0 application
任务
1 Job
一个action 一个job
2 Stage
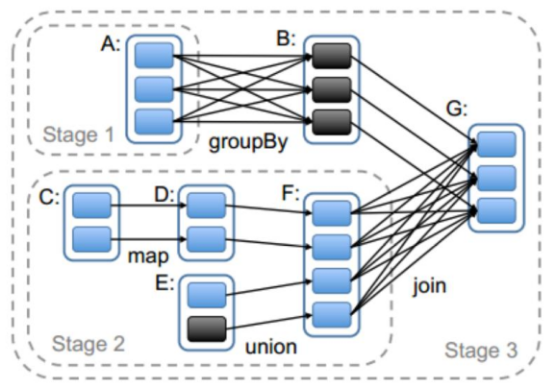
一个job根据rdd的依赖关系构建dag,根据dag划分stage,一个job包含一个或者多个stage
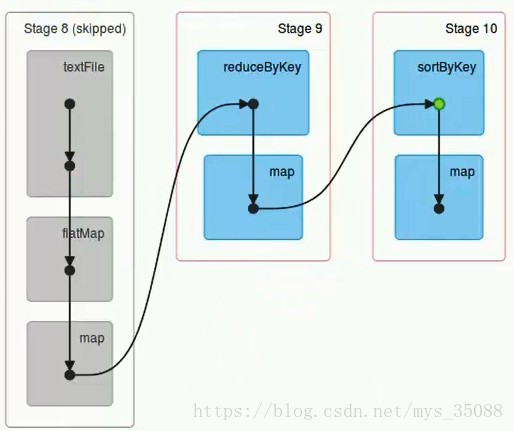
3 Task
stage根据rdd的分区数决定task数量
4 record
一个task 对应很多record,也就是多少行数据
例子
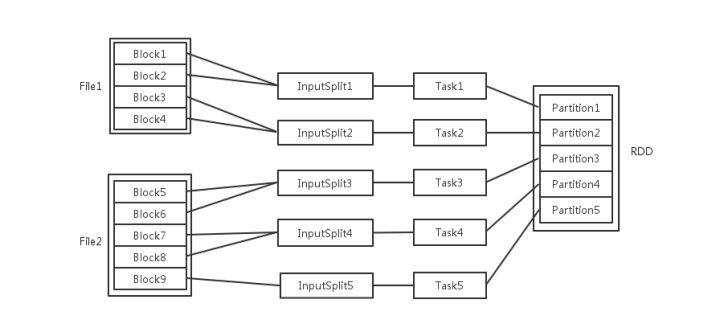
这里应该是 rdd的分区数决定task数量,task数量决定inputsplit数量,然后决定block的组合
https://juejin.cn/post/6844903848536965134
2 rdd分区
为什么分区?
分区的主要作用是用来实现并行计算,提高效率
分区方式
Spark包含两种数据分区方式:HashPartitioner(哈希分区)和RangePartitioner(范围分区)
分区数设置
1.spark容错机制
2.pyspark
3.Sparksql运行流程
4.Sparkcore运行流程
5.sparksql对比hive sql
6.Spark vs MapReduce
7.Spark on Hive & Hive on Spark
8.RDD依赖关系

