函数
1 系统函数
https://www.studytime.xin/article/hive-knowledge-function.html
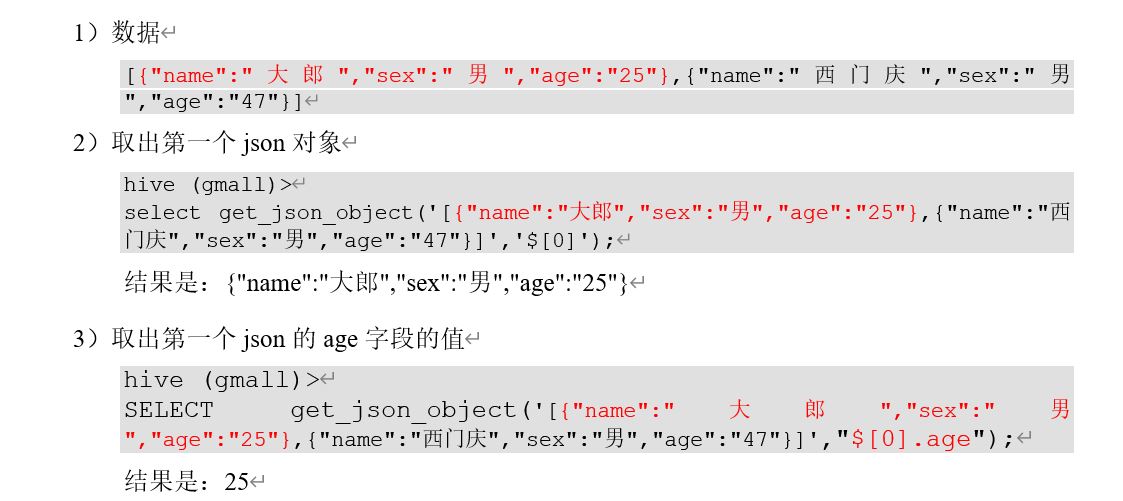
1 get_json_object
https://blog.csdn.net/weixin_43412569/article/details/105290637
2 nvl
空值判断转换函数
https://blog.csdn.net/a850661962/article/details/101209028
3 coalesce
https://blog.csdn.net/yilulvxing/article/details/86595725
1 | select coalesce(success_cnt,period,1) from tableA |
当success_cnt不为null,那么无论period是否为null,都将返回success_cnt的真实值(因为success_cnt是第一个参数),当success_cnt为null,而period不为null的时候,返回period的真实值。只有当success_cnt和period均为null的时候,将返回1。
4 collect_list和collect_set
https://blog.csdn.net/weixin_30230059/article/details/113324945
https://blog.csdn.net/qq_44104303/article/details/117551807
它们都是将分组中的某列转为一个数组返回,不同的是collect_list不去重而collect_set去重。
5 named_struct
https://blog.csdn.net/weixin_43597208/article/details/117554838
做字段拼接
区别于struct,struct 是集合数据类型,一般用于建表,named_struct是字段拼接函数,一般用于查询
6 array_contains()
1 | array_contains(array,值) |
判断array中是否包含某个值,包含返回true,不包含返回false
7 cast
https://www.jianshu.com/p/999176fa2730
显式的将一个类型的数据转换成另一个数据类型
1 | Cast(字段名 as 转换的类型 ) |
2 用户自定义函数
UDF(User-Defined-Function):单入单出
UDTF(User-Defined Table-Generating Functions):单入多出
UDAF(User Defined Aggregation Function):多入单出
https://blog.csdn.net/qq_40579464/article/details/105903405
1.编写代码
jar不能随意编写,需要和hive对齐接口,可以借助工具import org.apache.hadoop.hive.ql.exec.UDF;
1 | 1 public class classname extends UDF |
https://blog.csdn.net/eyeofeagle/article/details/83904147
2.打包
3.导入hive
复制到hdfs上
Hive安装目录的lib目录下
4.创建关联
add jar hdfs://localhost:9000/user/root/hiveudf.jar
create temporary function my_lower as ‘com.example.hive.udf.LowerCase’;
5.使用
hql udf的使用和普通内置函数一样,比如有udf1
1 | select udf1(col1) from table1 |

