finetune
1 使用哪些层参与下游任务
使用哪些层参与下游任务
选择的层model1+下游任务model2
对于深度模型的不同层,捕获的知识是不同的,比如说词性标注,句法分析,长期依赖,语义角色,协同引用。对于RNN based的模型,研究表明多层的LSTM编码器的不同层对于不同任务的表现不一样。对于transformer based 的模型,基本的句法理解在网络的浅层出现,然而高级的语义理解在深层出现。
用$\textbf{H}^{l}(1<=l<=L)$表示PTM的第$l$层的representation,$g(\cdot)$为特定的任务模型。有以下几种方法选择representation:
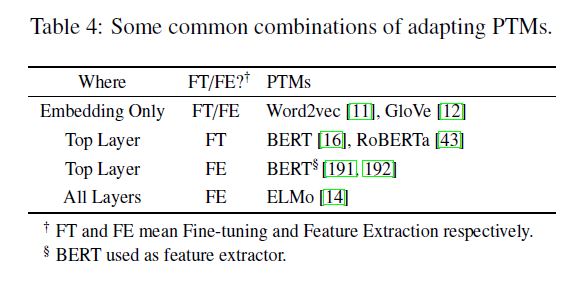
a) Embedding Only
choose only the pre-trained static embeddings,即$g(\textbf{H}^{1})$
b) Top Layer
选择顶层的representation,然后接入特定的任务模型,即$g(\textbf{H}^{L})$
c) All Layers
输入全部层的representation,让模型自动选择最合适的层次,然后接入特定的任务模型,比如ELMo,式子如下
其中$\alpha$ is the softmax-normalized weight for layer $l$ and $\gamma$ is a scalar to scale the vectors output by pre-trained model
2 参数是否固定
总共有两种常用的模型迁移方式:feature extraction (where the pre-trained parameters are frozen), and fine-tuning (where the pre-trained parameters are unfrozen and fine-tuned).
3 Fine-Tuning Strategies
Two-stage fine-tuning
第一阶段为中间任务,第二阶段为目标任务
Multi-task fine-tuning
multi-task learning and pre-training are complementary technologies.
Fine-tuning with extra adaptation modules
The main drawback of fine-tuning is its parameter ineffciency: every downstream task has its own fine-tuned parameters. Therefore, a better solution is to inject some fine-tunable adaptation modules into PTMs while the original parameters are fixed.
Others
self-ensemble ,self-distillation,gradual unfreezing,sequential unfreezing

