ChineseBERT Chinese Pretraining Enhanced by Glyph and Pinyin Information
考虑字形和拼音的中文PTM
1 模型结构
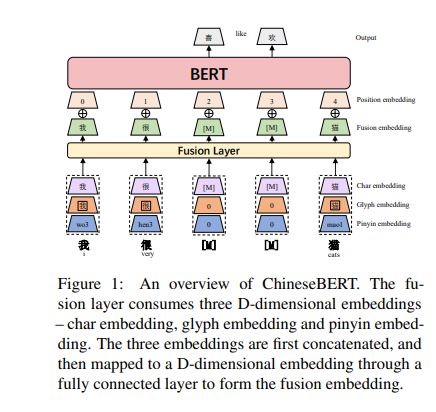
变动在bert的输入
原来Char embedding+Position embedding+segment embedding-> 现在 Fusion embedding+Position embedding (omit the segment embedding)
Char embedding +Glyph ( 字形 ) embedding +Pinyin (拼音)embedding -》Fusion embedding
2 预训练任务
Whole Word Masking (WWM) and Char Masking (CM)
3 使用
1 | >>> from datasets.bert_dataset import BertDataset |
参考
ChineseBERT Chinese Pretraining Enhanced by Glyph and Pinyin Information

