优先队列
哈希表
1 原理
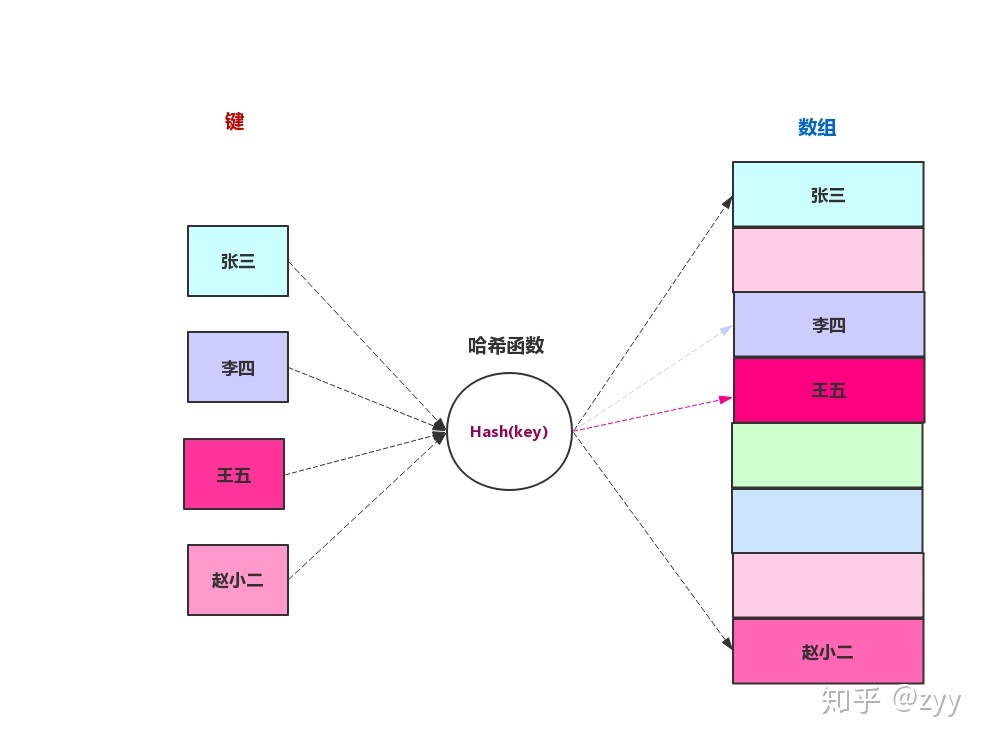
2 哈希冲突
https://blog.51cto.com/u_15077556/3984082
https://www.jianshu.com/p/585f8882bbfb
3 效率
插入和查找的时间复杂度都是为O(1)
参考
数据结构汇总
https://blog.csdn.net/m0_37568814/article/details/81288756
https://zhuanlan.zhihu.com/p/138523723
1 分类
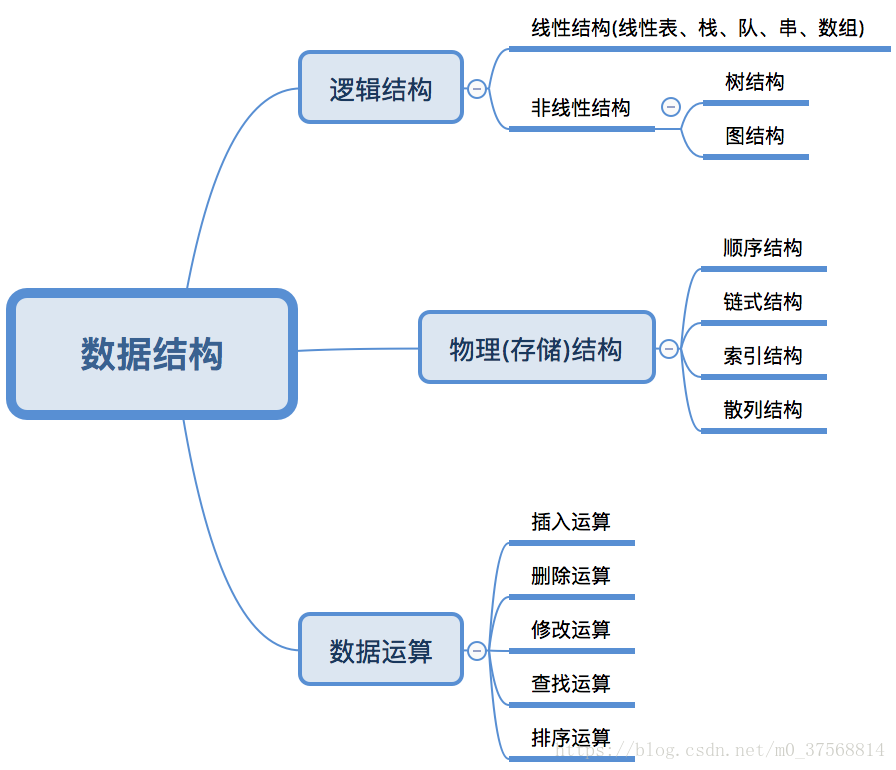
数据结构包括:逻辑结构,存储结构,数据运算
数据的逻辑结构主要分为线性结构和非线性结构。
- 线性结构:数据结构的元素之间存在一对一线性关系,所有结点都最多只有一个直接前趋结点和一个直接后继结点。常见的有数组、队列、链表、栈。
- 非线性结构:各个结点之间具有多个对应关系,一个结点可能有多个直接前趋结点和多个直接后继结点。常见的有多维数组、广义表、树结构和图结构等。
数据的存储结构,表示数据元素之间的逻辑关系,一种数据结构的逻辑结构根据需要可以表示成多种存储结构,常用的存储结构有:
- 顺序存储:存储顺序是连续的,在内存中用一组地址连续的存储单元依次存储线性表的各个数据元素。
- 链式存储:在内存中的存储元素不一定是连续的,用任意地址的存储单元存储元素,元素节点存放数据元素以及通过指针指向相邻元素的地址信息。
- 索引存储:除建立存储结点信息外,还建立附加的索引表来标识节点的地址。索引表由若干索引项组成。
- 散列存储:又称Hash存储,由节点的关键码值决定节点的存储地址。
2 常用的数据结构
- 数组(Array)
- 队列(Queue)
- 链表(Linked List)
- 栈(Stack)
- 树(Tree)
- 散列表(Hash)
- 堆(Heap)
- 图(Graph)
单调栈
分类:
单调栈也分为单调递增栈和单调递减栈
- 单调递增栈:单调递增栈就是从栈底到栈顶数据是从大到小
- 单调递减栈:单调递减栈就是从栈底到栈顶数据是从小到大
举例:单调递增栈
现在有一组数10,3,7,4,12。从左到右依次入栈,则如果栈为空或入栈元素值小于栈顶元素值,则入栈;否则,如果入栈则会破坏栈的单调性,则需要把比入栈元素小的元素全部出栈。
10入栈时,栈为空,直接入栈,栈内元素为10。
3入栈时,栈顶元素10比3大,则入栈,栈内元素为10,3。
7入栈时,栈顶元素3比7小,则栈顶元素出栈,此时栈顶元素为10,比7大,则7入栈,栈内元素为10,7。
4入栈时,栈顶元素7比4大,则入栈,栈内元素为10,7,4。
12入栈时,栈顶元素4比12小,4出栈,此时栈顶元素为7,仍比12小,栈顶元素7继续出栈,此时栈顶元素为10,仍比12小,10出栈,此时栈为空,12入栈,栈内元素为12。
伪代码
1 | stack<int> st; |
应用:
主要用于$O(n)$ 解决NGE问题(Next Greater Element)
- 比当前元素更大的下一个元素
- 比当前元素更大的前一个元素
- 比当前元素更小的下一个元素
- 比当前元素更小的前一个元素
参考
字典树
一.核心思想
Trie tree,即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较。Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。字典树的查询时间复杂度是O (L),L是待查字符串的长度。如果是普通的线性表结构,那么查询效率为O(NL),N为待查数据集的大小。
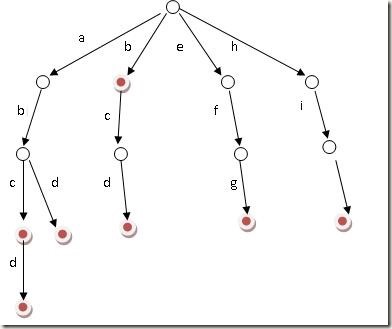
假设有b,abc,abd,bcd,abcd,efg,hii 这6个单词,那我们创建字典树如下:
二.应用
目的:利用汉语拼音缩写还原中文汉字
准备:数据集(包含中文汉字以及对应汉语缩写)
思想:1.基于汉语拼音缩写检索出数据集中对应的所有中文汉字 2.基于中文汉字出现频次排序,将top1作为汉语拼音的还原结果
代码
1 | import pandas as pd |