双指针
指针$i$,指针$j$,序列长度为$n$
1 $O(n^2)$
$i$总共遍历$n$,$j$总共遍历$n^2$
1 $O(n )$
$i$总共遍历$n$,$j$总共遍历$n$
指针$i$,指针$j$,序列长度为$n$
1 $O(n^2)$
$i$总共遍历$n$,$j$总共遍历$n^2$
1 $O(n )$
$i$总共遍历$n$,$j$总共遍历$n$
核心思想:取一个数作为基准,比这个数小的放在左边,大的放在右边,然后左边重复,右边重复。
基准元素,一般来说选取有几种方法
实现方式:一般递归+双指针
伪代码
1 | 1:首先取序列第一个元素为基准元素pivot=R[low]。i=low,j=high。 |
时间复杂度(0nlogn)
参考:
https://www.jianshu.com/p/a753d5c733ec
1 | def dfs(当前节点,子节点) |
1 | #### root 当前节点 path子节点 depth 深度 |
1 | ###grid全部格点 cur_i,cur_j 当前节点的位置,用+1-1可以确定子节点 |
root进队,root出队,root的子节点【a,b,c】进队,a出队,a的子节点进队,b出队,b的子节点进队。。。
访问顺序(出队顺序):root a b c 。。。
1 | class Solution: |
1 | class Solution: |
时间复杂度都为O(n),n为全部节点
回溯是算法思想,dfs和bfs是搜索解空间的手段
https://www.jianshu.com/p/e81a16a6f771
https://blog.csdn.net/weixin_41894030/article/details/95317440
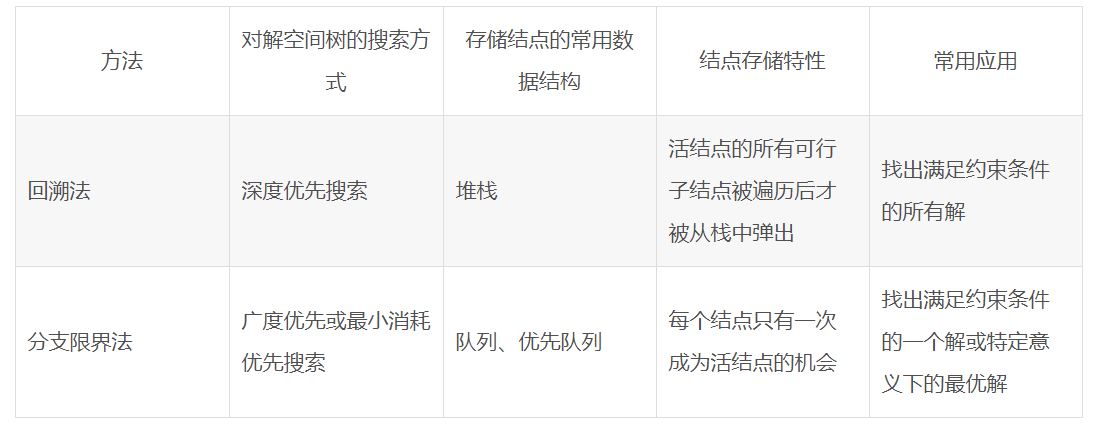
类别归类:蛮力,分治,动态规划,贪心,回溯,分支限界。
实现方式有两种,一般为基于迭代和基于递归。
没有什么好说,就是遍历或者枚举。
分而治之,将大问题拆解成相互独立且相似的子问题。
步骤:1、先分 2 求解 3 .合并
实现方式:一般递归实现
和暴力相比,dp利用了子问题间的依赖关系,减少了一些计算
适用条件:1.满足最优子结构性质,即最优解所包含的子问题的解也是最优的
构造递推式:
0.确定维度,一般一维或者二维
1.注意含义
2.选择分隔点
a. 一般和前一步或者两步有关,比如最大子序和,$dp[i]=max(s[i],s[i]+dp[i-1])$
b. 但有时候需要遍历全部分割点,比如单词拆分,$dp[i]=dp[j] \ \& \& \ check(s[j..i−1])$,
c. 有时候动态选择分隔点,比如丑数,$ dp[i]=min(dp[p2]2,dp[p3]3,dp[p5]*5) $,其中$p2,p3,p5$动态变化
3.注意+, -
一定是用已有的递推没有的
举例比如62. 不同路径,$dp[i][j] = dp[i-1][j] + dp[i][j-1]$;
1 | class Solution: |
比如5. 最长回文子串,$dp[i][j]=dp[i+1][j-1] \ and \ s[i]==s[j]$
s = “babad”
n=5
(i,j)
(0,1) (1,2) (2,3) (3,4) (0,2) (1,3) (2,4) (0,3)
1 | class Solution: |
解的追踪:有时候需要借助备忘录搜索解,时间复杂度不超过计算备忘录
实现方式
递归实现:效率不高的原因在于子问题重复计算了,比起暴力哪个快?应该还是这个
迭代+备忘录:不一定全部都要存储,需要的存着了就可以了,每次子问题计算一次(空间换时间)
一般采用迭代+备忘录
状态压缩动态规划
https://jimmy-shen.medium.com/bitmask-state-compression-dp-39e7ba56978b
https://segmentfault.com/a/1190000038223084
https://blog.csdn.net/wxgaws/article/details/114693162
Usually, the state of DP can use limited variables to represent such a dp[i] , dp[i] [j] ,dp[i] [j] [k].
However, sometimes, the states of a DP problem may contain multiple statuses. In this case, we can think about using the state compression approaches to represent the DP state.
说白了就是在状态很多的时候对状态降维
目的:可以优化空间复杂度,不知道可以不可以优化时间复杂度
短视,局部最优(少考虑很多,计算量就下去了)
需要证明
一般用于可以用树型结构建模的问题
回溯法能系统地搜索一个问题的所有解,和暴力的区别在于回溯可以剪枝,以此减少计算量
实现方式:利用DFS搜索解空间,一般递归实现
https://zhuanlan.zhihu.com/p/93530380
https://zhuanlan.zhihu.com/p/112926891
类似回溯,区别如下
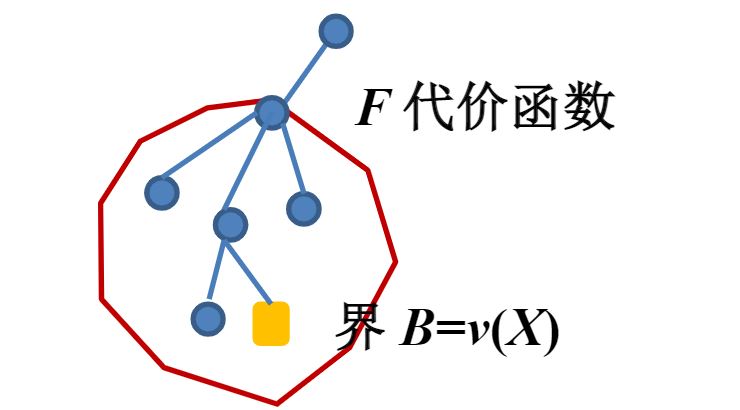
代价函数
以极大值问题为例,以当前结点为根的子树能够得到的可行解的最大值
界
以极大值问题为例,当前已经得到的可行解的最大值
减枝
代价函数和界可以用于减枝,以极大值问题为例,界大于等于某结点代价函数,该结点就不需要继续搜索了
https://blog.csdn.net/zm1_1zm/article/details/69224626
https://blog.csdn.net/wxgaws/article/details/114693162
https://segmentfault.com/a/1190000038223084
https://jimmy-shen.medium.com/bitmask-state-compression-dp-39e7ba56978b
