class Solution: def levelOrder(self, root: 'Node') -> List[List[int]]: if root==None: return [] ans = [] q = [root] while q: # length = len(q) # arr = [] # for _ in range(length): node = q.pop(0) # arr.append(node.val) for chd in node.children: q.append(chd) # if arr: ans.append(node.val) return ans
class Solution: def levelOrder(self, root: 'Node') -> List[List[int]]: ans = [] ##结果 q = [root] ##队列 while q: length = len(q) arr = [] #出队 for _ in range(length): node = q.pop(0) if not node: continue arr.append(node.val) for chd in node.children: q.append(chd) if arr: ans.append(arr) return ans
import pandas as pd import pickle import os import joblib
class TrieNode(object): def __init__(self): """ Initialize your data structure here. """ self.data = {}###字母字符 self.data1={}###中文 self.is_word = False###标识是否汉字
class Trie(object):
def __init__(self): self.root = TrieNode()
def insert(self, word,word1): """ Inserts a word into the trie. :type word: str :rtype: void """ node = self.root for letter in word: child = node.data.get(letter) if not child: node.data[letter] = TrieNode() node = node.data[letter] node.is_word = True if word1 not in node.data1: node.data1[word1]=1 else: node.data1[word1]+=1
def search(self, word): """ Returns if the word is in the trie. :type word: str :rtype: bool """ node = self.root for letter in word: node = node.data.get(letter) if not node: return False return node.is_word
def starts_with(self, prefix): """ Returns if there is any word in the trie that starts with the given prefix. :type prefix: str :rtype: bool """ node = self.root for letter in prefix: node = node.data.get(letter) if not node: return False return True
def get_start(self, prefix): """ Returns words started with prefix :param prefix: :return: words (list) """ def _get_key(pre, pre_node): words_list = [] if pre_node.is_word: words_list.append([pre,pre_node.data1]) for x in pre_node.data.keys(): words_list.extend(_get_key(pre + str(x), pre_node.data.get(x))) return words_list
words = [] if not self.starts_with(prefix): return words # if self.search(prefix): # words.append(prefix) # return words node = self.root for letter in prefix: node = node.data.get(letter) return _get_key(prefix, node)
def find_result(self,string): result =self.get_start(string) result = sort_by_value(result[0][1]) result.reverse() return result[0] def sort_by_value(d): return sorted(d.items(), key=lambda k: k[1]) # k[1] 取到字典的值。
def build_tree(data,save_path):
trie = Trie() for element in data.values: trie.insert(element[0], element[1]) joblib.dump(trie, save_path) return
class Solution: def uniquePaths(self, m: int, n: int) -> int: dp = [[1]*n] + [[1]+[0] * (n-1) for _ in range(m-1)] #print(dp) for i in range(1, m): for j in range(1, n): dp[i][j] = dp[i-1][j] + dp[i][j-1] return dp[-1][-1]
比如5. 最长回文子串,$dp[i][j]=dp[i+1][j-1] \ and \ s[i]==s[j]$
class Solution: def longestPalindrome(self, s: str) -> str: n = len(s) if n < 2: return s max_len = 1 begin = 0 # dp[i][j] 表示 s[i..j] 是否是回文串 dp = [[False] * n for _ in range(n)] for i in range(n): dp[i][i] = True # 递推开始 # 先枚举子串长度 for L in range(2, n + 1): # 枚举左边界,左边界的上限设置可以宽松一些 for i in range(n): # 由 L 和 i 可以确定右边界,即 j - i + 1 = L 得 j = L + i - 1 # 如果右边界越界,就可以退出当前循环 if j >= n: break if s[i] != s[j]: dp[i][j] = False else: if j - i < 3: dp[i][j] = True else: dp[i][j] = dp[i + 1][j - 1] # 只要 dp[i][L] == true 成立,就表示子串 s[i..L] 是回文,此时记录回文长度和起始位置 if dp[i][j] and j - i + 1 > max_len: max_len = j - i + 1 begin = i return s[begin:begin + max_len]
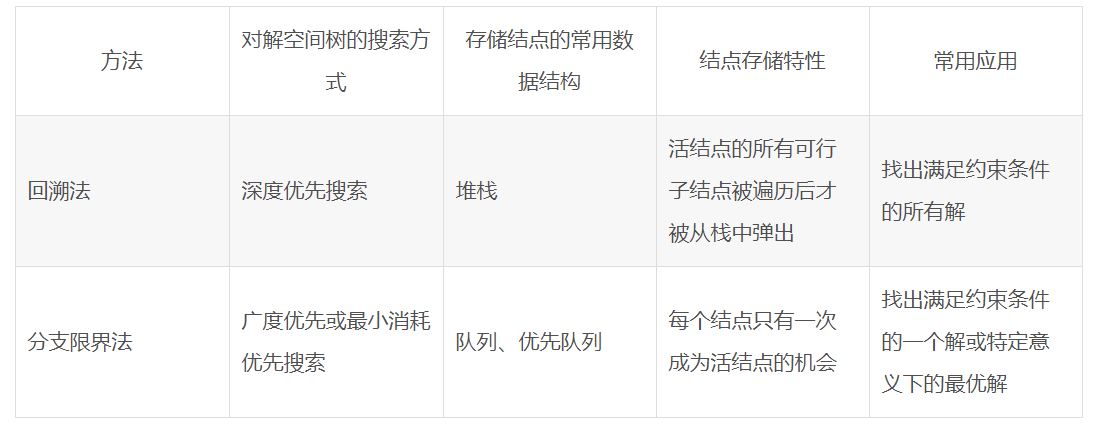
Usually, the state of DP can use limited variables to represent such a dp[i] , dp[i] [j] ,dp[i] [j] [k].
However, sometimes, the states of a DP problem may contain multiple statuses. In this case, we can think about using the state compression approaches to represent the DP state.