kafka常见命令
启动命令
1 | /opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties |
关闭命令
1 | /opt/module/kafka/bin/kafka-server-stop.sh stop |
topic
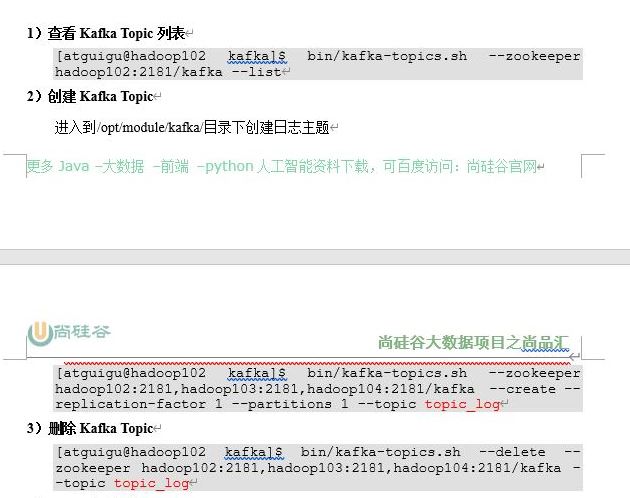

生产

消费

查看消费情况
指定offset
启动命令
1 | /opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties |
关闭命令
1 | /opt/module/kafka/bin/kafka-server-stop.sh stop |
topic
生产
消费
查看消费情况
指定offset
https://blog.csdn.net/weixin_46303867/article/details/115256466
https://blog.csdn.net/szxiaohe/article/details/103639127
经验公式:Kafka机器数量= 2 (峰值生产速度 副本数 / 100)+ 1
1)峰值生产速度
峰值生产速度可以压测得到。
2)副本数
副本数默认是1个,在企业里面2-3个都有,2个居多。
副本多可以提高可靠性,但是会降低网络传输效率。
例子:
先拿到峰值生产速度,再根据设定的副本数,就能预估出需要部署Kafka的数量。
比如我们的峰值生产速度是50M/s。副本数为2。
Kafka机器数量 = 2 (50 2 / 100)+ 1 = 3台
(1)创建一个只有1个分区的topic
(2)测试这个topic的producer吞吐量和consumer吞吐量。
(3)假设他们的值分别是Tp和Tc,单位可以是MB/s。
(4)然后假设总的目标吞吐量是Tt,那么分区数 = Tt / min(Tp,Tc)
例如:producer吞吐量 = 20m/s;consumer吞吐量 = 50m/s,期望吞吐量100m/s;分区数 = 100 / 20 = 5分区
https://blog.csdn.net/weixin_42641909/article/details/89294698
分区数一般设置为:3-10个
https://www.lilinchao.com/archives/1548.html
https://developer.51cto.com/article/658581.html
过去
Apache Kafka的一个关键依赖是Apache Zookeeper,它是一个分布式配置和同步服务。 Zookeeper是Kafka代理和消费者之间的协调接口。 Kafka服务器通过Zookeeper集群共享信息。 Kafka在Zookeeper中存储基本元数据,例如关于主题,代理,消费者偏移(队列读取器)等的信息。
由于所有关键信息存储在Zookeeper中,并且它通常在其整体上复制此数据,因此Kafka代理/ Zookeeper的故障不会影响Kafka集群的状态。 Kafka将恢复状态,一旦Zookeeper重新启动。 这为Kafka带来了零停机时间。 Kafka代理之间的领导者选举也通过使用Zookeeper在领导者失败的情况下完成。
未来
Kafka 2.8.0,移除了对Zookeeper的依赖,通过KRaft进行自己的集群管理