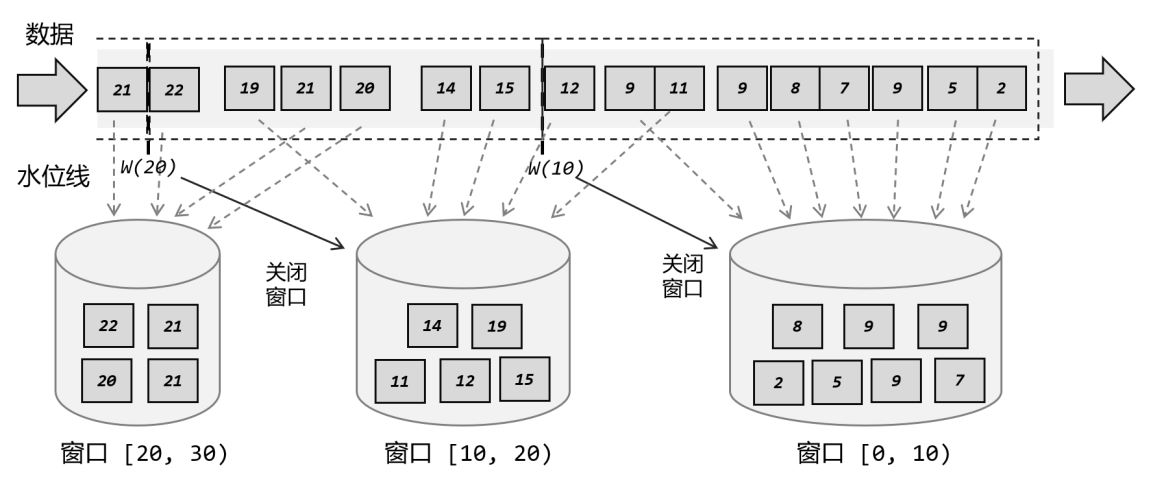
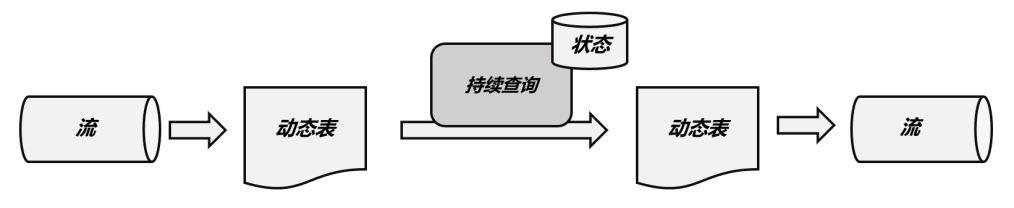
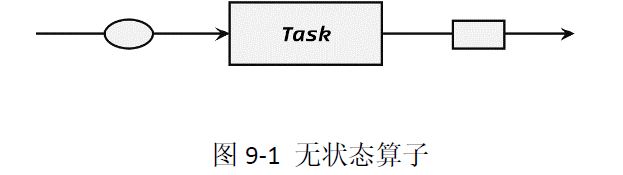
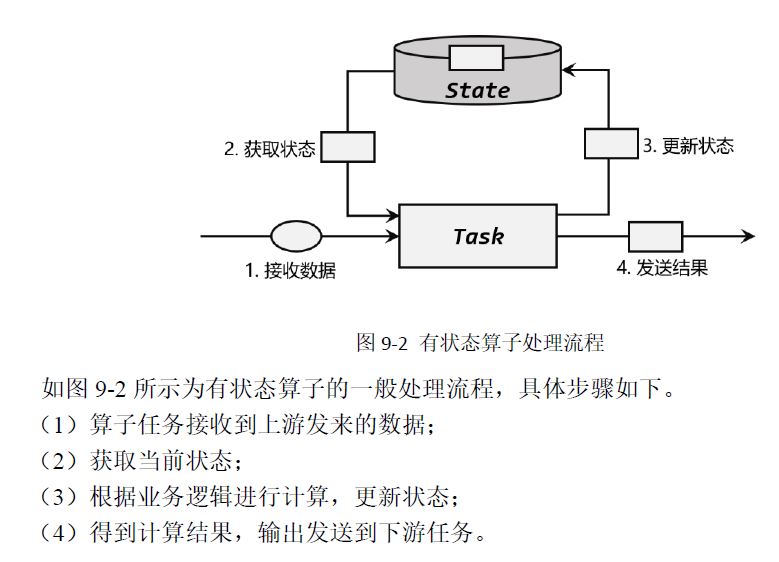
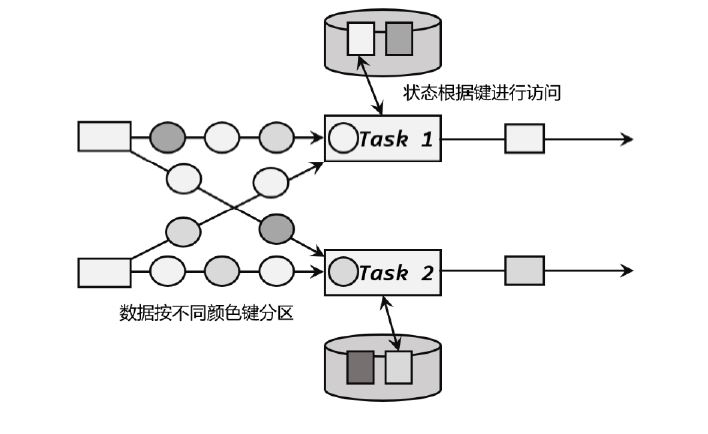
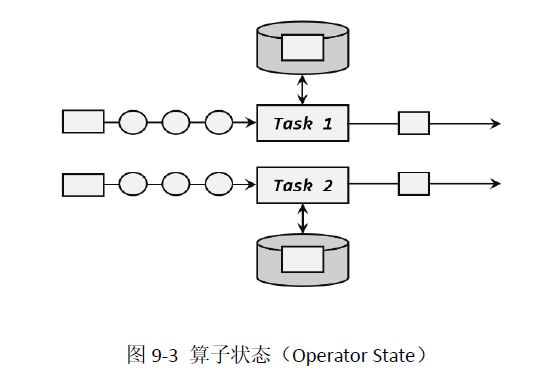
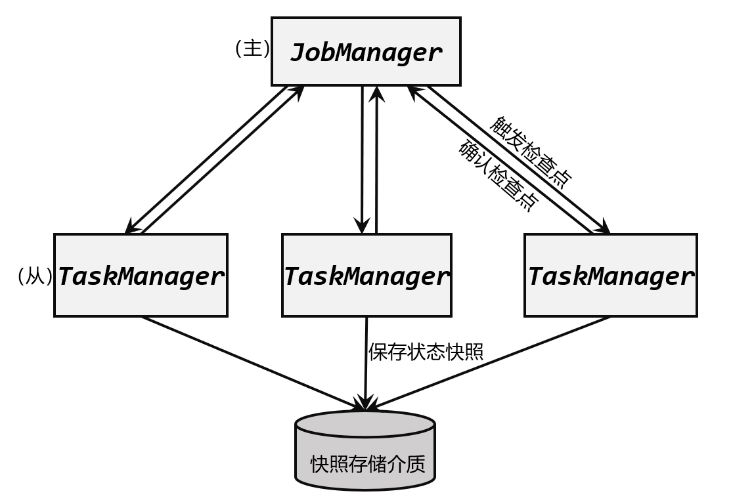
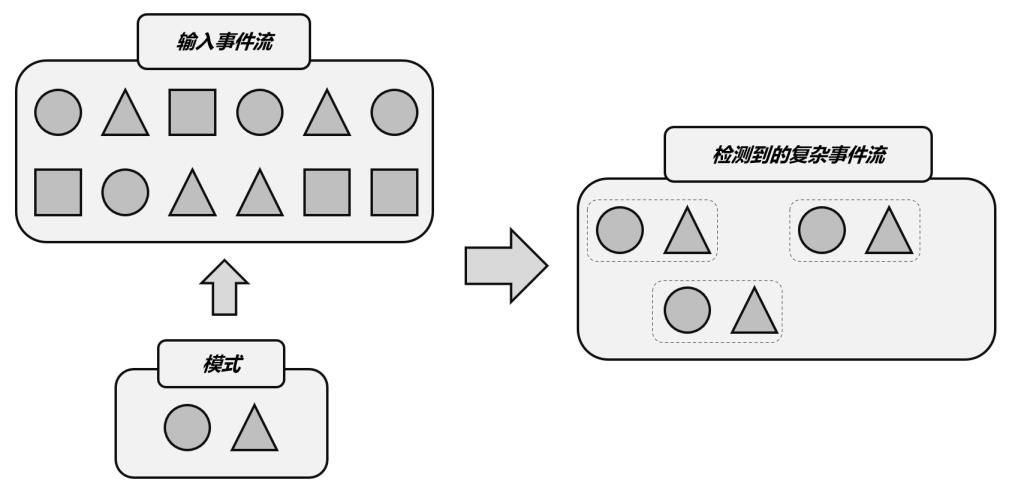
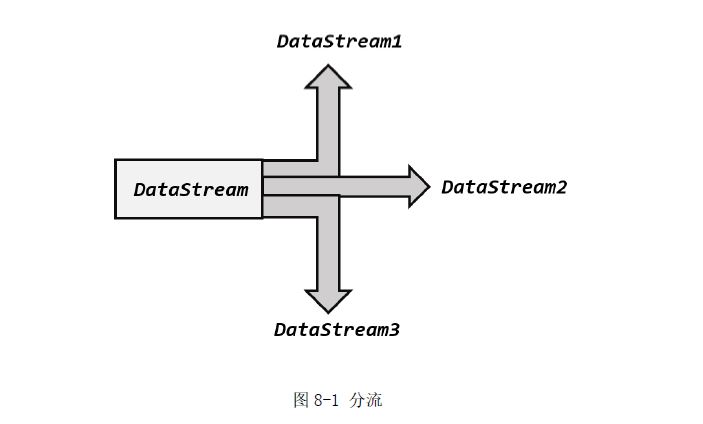
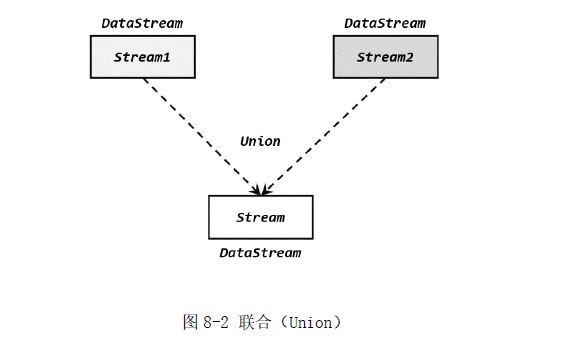
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 5000L),
new Event("Bob", "./cart", 2000L),
new Event("Mary", "./cart", 3000L),
new Event("ss", "./fav", 4000L),
new Event("Mary", "./fav", 10000L)
);
stream.keyBy(e -> e.user)
// .maxBy("timestamp")
.maxBy("timestamp") // 指定字段名称
.print("maxBy:");
stream.keyBy(e -> e.user)
// .("timestamp")
.max("timestamp") // 指定字段名称
.print("max:");
max:> Event{user='Mary', url='./home', timestamp=1970-01-01 08:00:05.0}
maxBy:> Event{user='Mary', url='./home', timestamp=1970-01-01 08:00:05.0}
max:> Event{user='Bob', url='./cart', timestamp=1970-01-01 08:00:02.0}
maxBy:> Event{user='Bob', url='./cart', timestamp=1970-01-01 08:00:02.0}
max:> Event{user='Mary', url='./home', timestamp=1970-01-01 08:00:05.0}
max:> Event{user='ss', url='./fav', timestamp=1970-01-01 08:00:04.0}
maxBy:> Event{user='Mary', url='./home', timestamp=1970-01-01 08:00:05.0}
max:> Event{user='Mary', url='./home', timestamp=1970-01-01 08:00:10.0}
maxBy:> Event{user='ss', url='./fav', timestamp=1970-01-01 08:00:04.0}
maxBy:> Event{user='Mary', url='./fav', timestamp=1970-01-01 08:00:10.0}
max部分替换,maxby全部替换
|