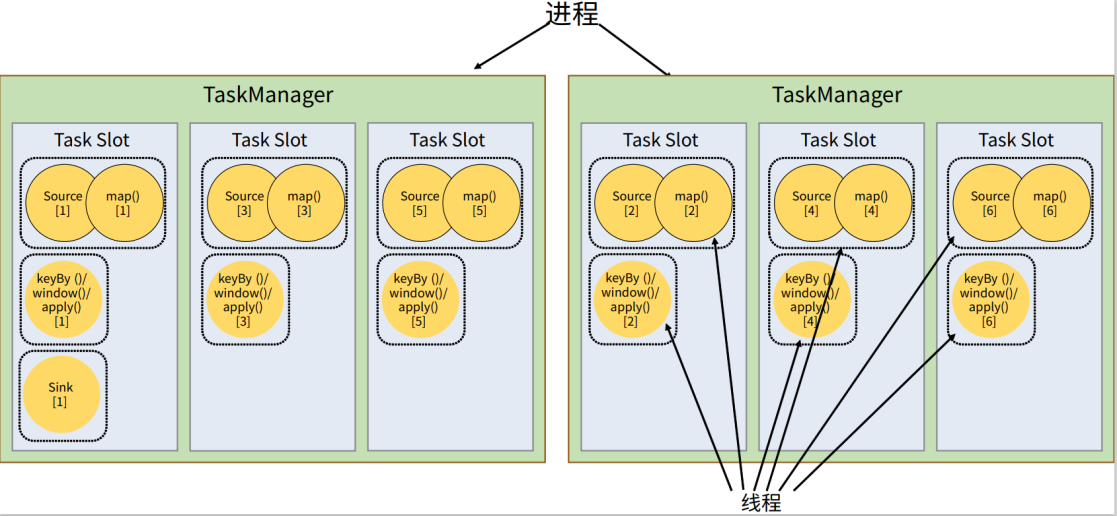
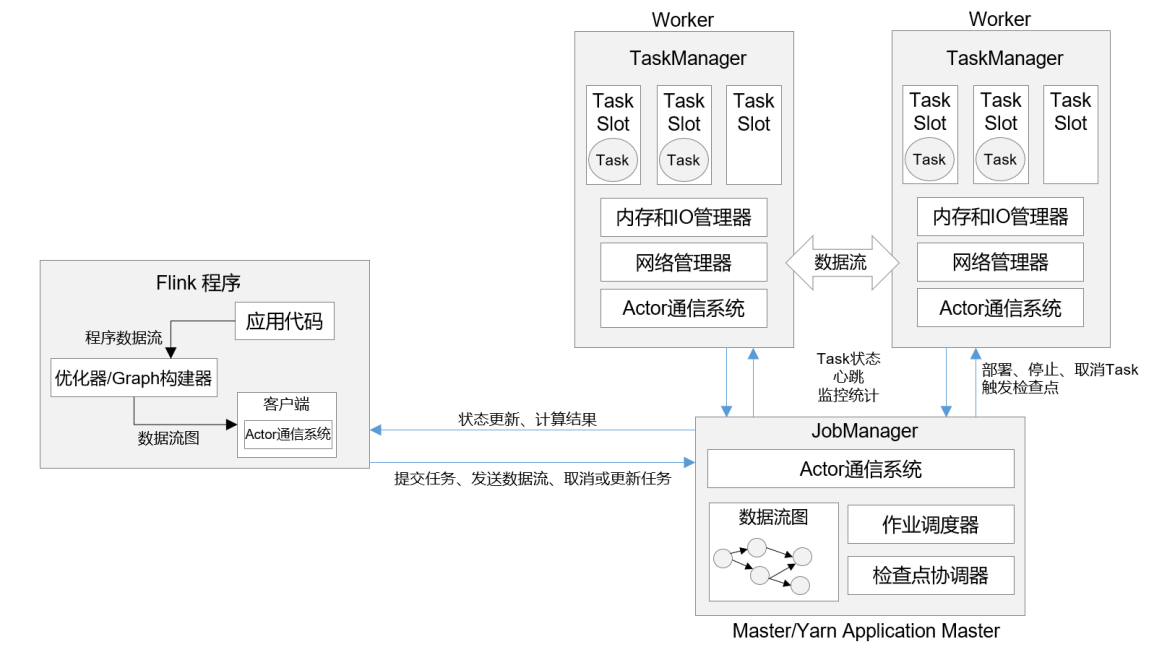
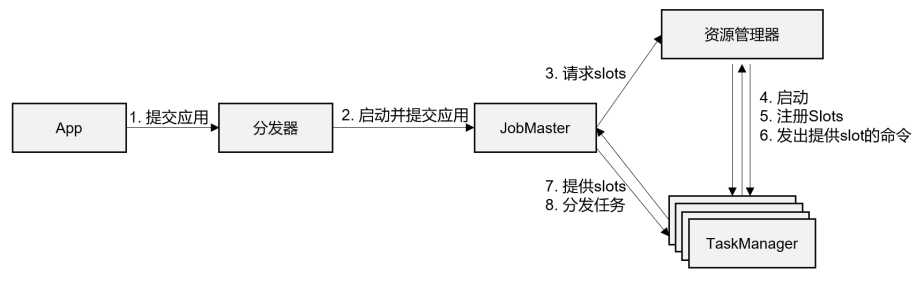
任务生成和分配
main代码 -》 数据流图(dataflow graph,logical streamgraph) -》 作业图(jobgraph)-》执行图(executiongraph)-> 物理图(physical graph)
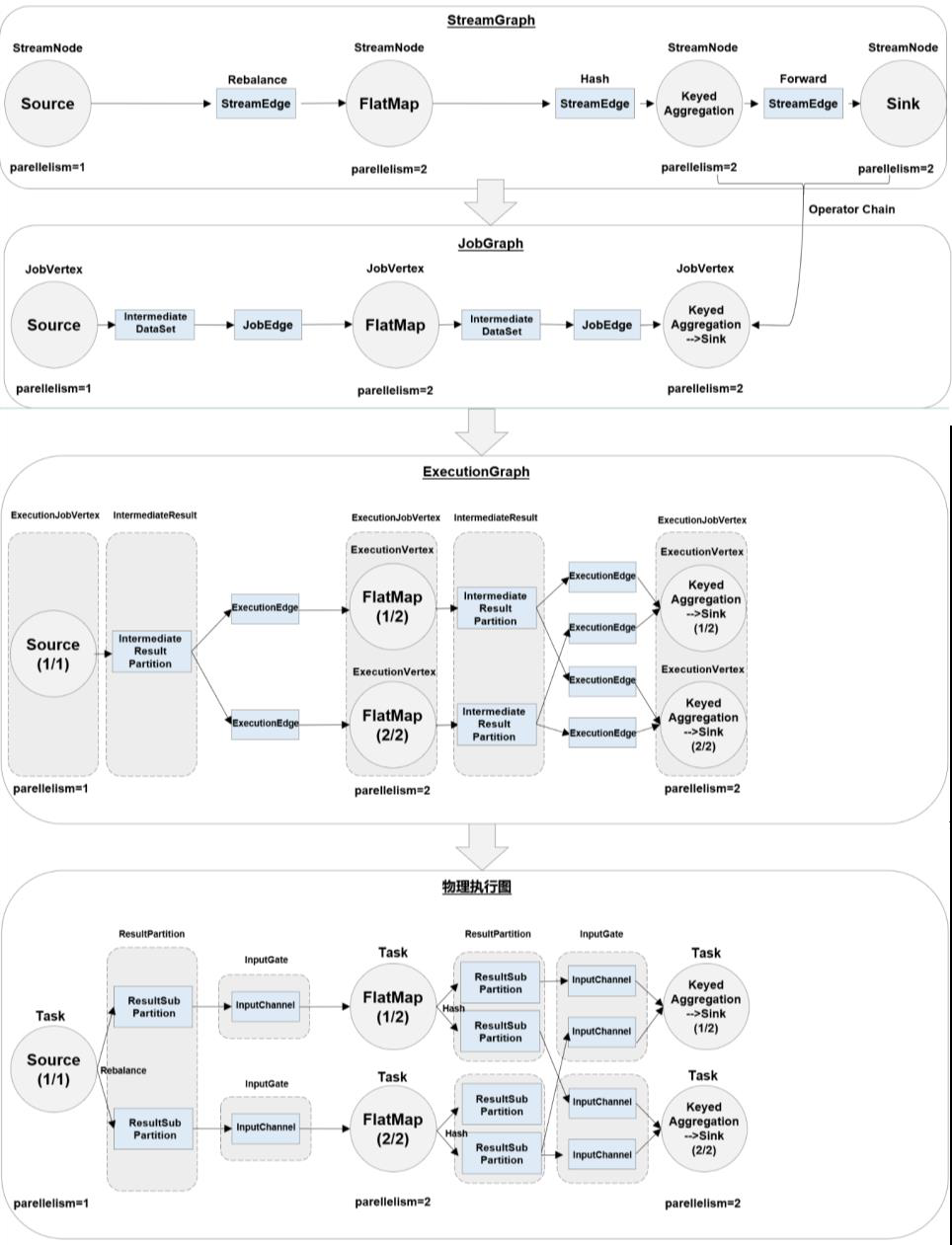

main代码 -》 数据流图(dataflow graph,logical streamgraph) -》 作业图(jobgraph)-》执行图(executiongraph)-> 物理图(physical graph)
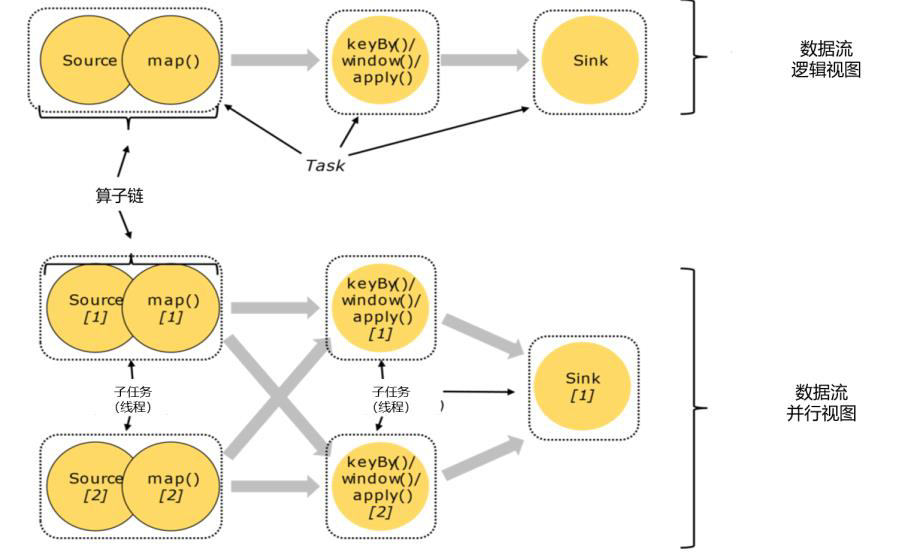
多个算子合并
合并条件:1 并行度相同的算子 2 一对一 one to one
好处:1. 减少线程之间的切换和缓存区的数据交换 2 减少时延 3 提高吞吐量
在分布式架构中,当某个节点出现故障,其他节点基本不受影响。这时只需要重启应用,恢复之前某个时间点的状态继续处理就可以了。这一切看似简单,可是在实时流处理中,我们不仅需要保证故障后能够重启继续运行,还要保证结果的正确性、故障恢复的速度、对处理性能的影响,这就需要在架构上做出更加精巧的设计。
在Flink中,有一套完整的容错机制( fault tolerance)来保证故障后的恢复,其中最重要的就是检查点( checkpoint)。在第九章中,我们已经介绍过检查点的基本概念和用途,接下来我 们就深入探讨一下检查点的原理和 Flink的容错机制。
https://blog.csdn.net/lmalds/article/details/52704170
https://blog.csdn.net/lightupworld/article/details/116697831
在实际应用中,一般会采用事件时间语义
水位线可以看作在数据流中加入一个时钟标记,记录当前的事件时间;这个标记可以直接广播到下游,当下游任务收到这个标记,就可以更新自己的时钟了。

1 有序流的水位线
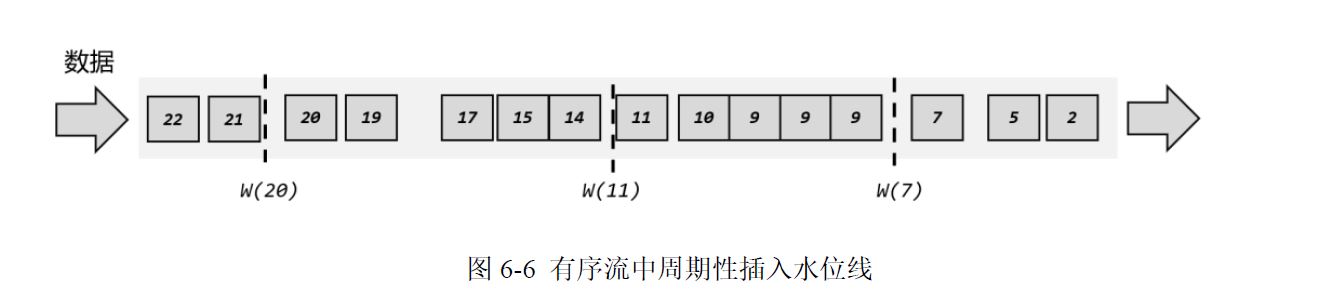
方框是事件时间,虚线是水位线,箭头表示数据到达的顺序,比如事件时间为2的数据第一个到,事件时间为5的数据第二个到
2 乱序流的水位线

比水位线小的数据在后面出现,也就是说本应该在水位线之前出现的数据晚到了,就是迟到数据,迟到数据是丢弃的,比如w(9)后面的8,9

1 原则
我们知道,完美的水位线是“绝对正确”的,也就是一个水位线一旦出现,就表示这个时间之前的数据已经全部到齐、之后再也不会出现了。而完美的东西总是可望不可即,我们只能尽量去保证水位线的正确。
“等” 或者说“延迟”
为了均衡实时性(少等,会引入大量迟到数据)和准确性(减少迟到数据,多等)
2 怎么写
1 assignTimestampsAndWatermarks
1 | Datastream <event> withTimestampsAndWatermarks = stream.assignTimestampsAndWatermarks(WatermarkStrategy) |
WatermarkStrategy
内置
1 | WatermarkStrategy.forMonotonousTimestamps |
自定义
先实现接口WatermarkGenerator,然后改写一些东西
2 自定义数据源中发送水位线
注意:自定义数据源也可以用assignTimestampsAndWatermarks,这里是指在自定义数据源中实现自己的水位线发送,不用assignTimestampsAndWatermarks
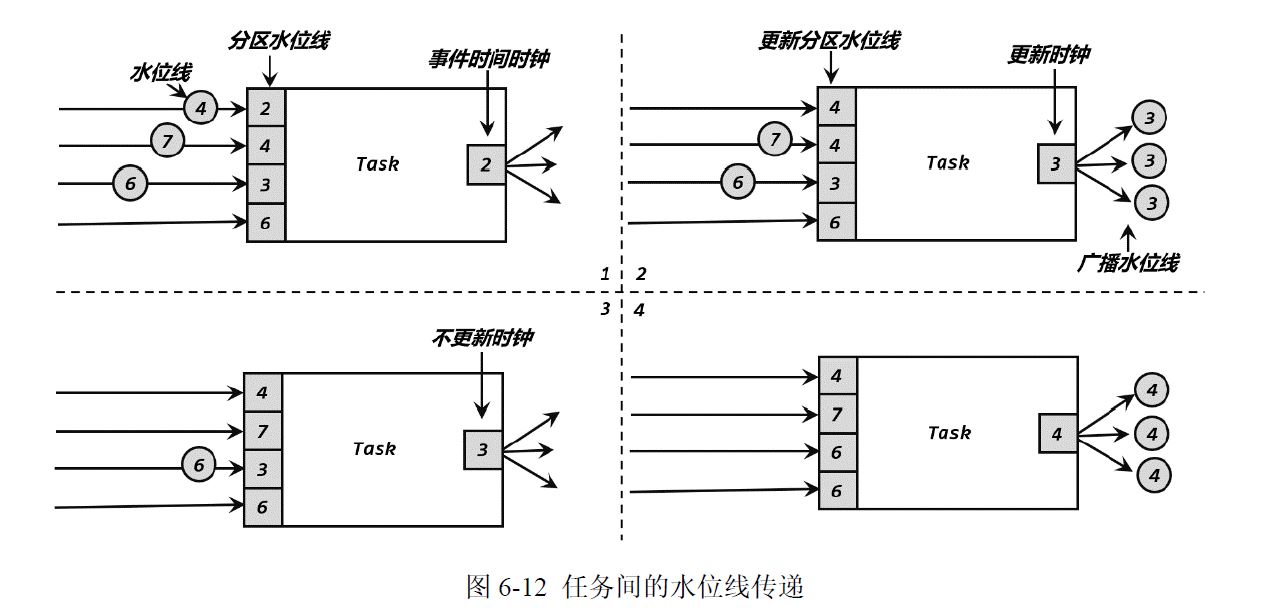
上游并行度为4,下游并行度为3
策略:木桶原理,取得是最小的
为什么木桶原则,以准为第一要义,举个例子图2,如果不是3,是4,那么3不就迟到了吗
https://blog.csdn.net/lomodays207/article/details/109642581
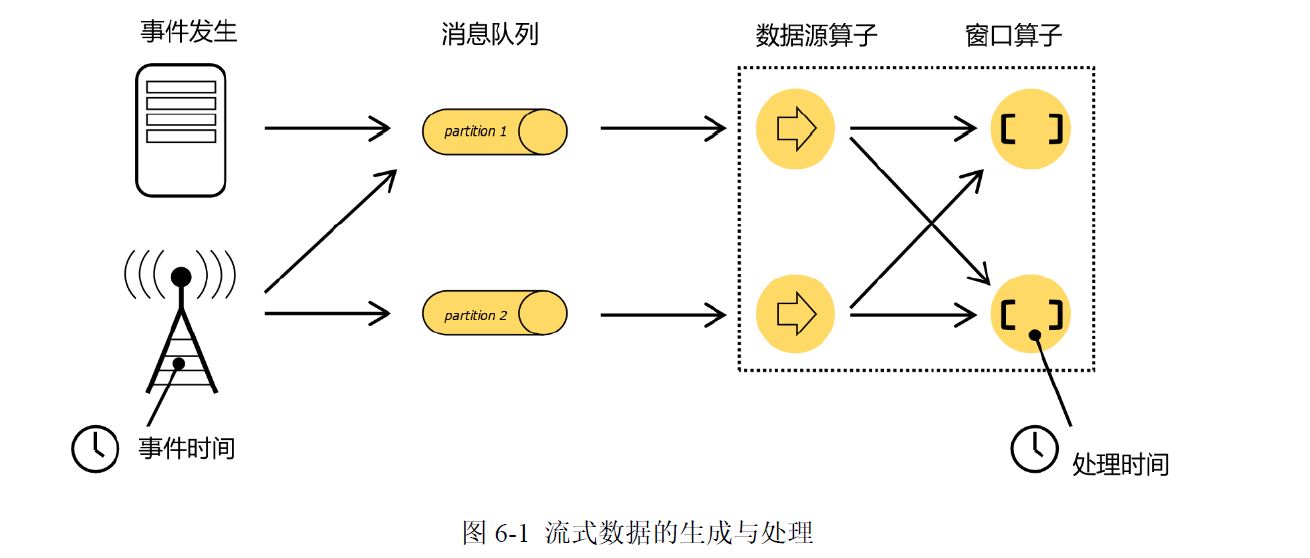
在Flink中,由于处理时间比较简单,早期版本默认的时间语义是处理时间;而考虑到事件时间在实际应用中更为广泛,从 1.12版本 开始 Flink已经将 事件时间作为了默认的时间语义。
处理时间的概念非常简单,就是指执行处理操作的机器的系统时间。
事件时间,是指每个事件在对应的设备上发生的时间,也就是数据生成的时间。
它是指数据进入 Flink数据流的时间,也就是 Source算子读入数据的时间。
https://flink.apache.org/zh/flink-architecture.html
任何类型的数据都可以形成一种事件流。信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。
数据可以被作为无界或者有界流来处理。
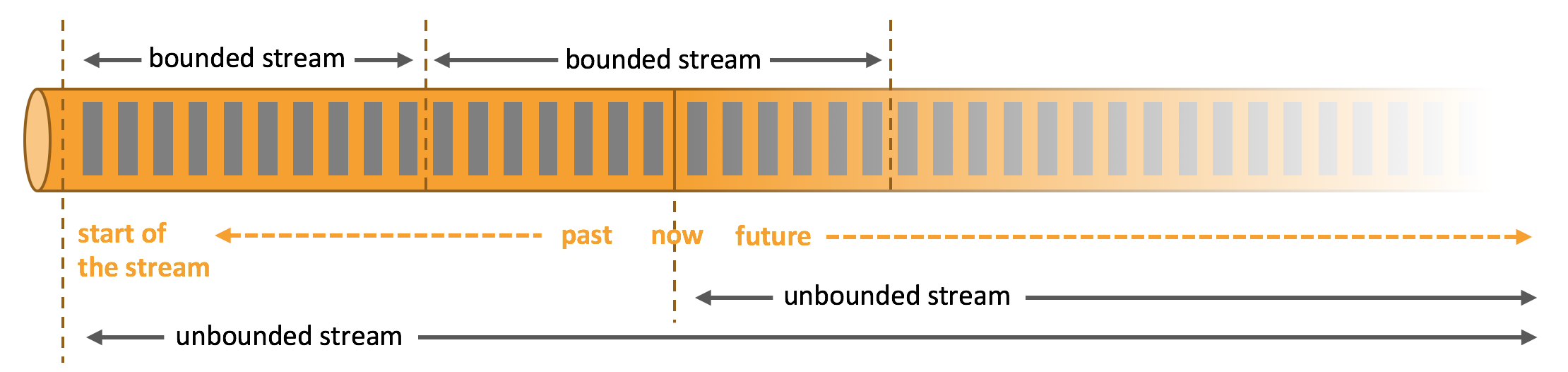
Apache Flink 擅长处理无界和有界数据集精确的时间控制和状态化使得 Flink 的运行时(runtime)能够运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
Flink的部署方式是灵活的,跟Spark一样,支持Local,Standalone,Yarn,Mesos,Kubernetes
代码中好像不能指定部署方式,和spark不同
https://blog.csdn.net/qq_33689414/article/details/90671685
最简单的启动方式,其实是不搭建集群,直接本地启动。本地部署非常简单,直接解压安装包就可以使用,不用进行任何配置;一般用来做一些简单的测试。
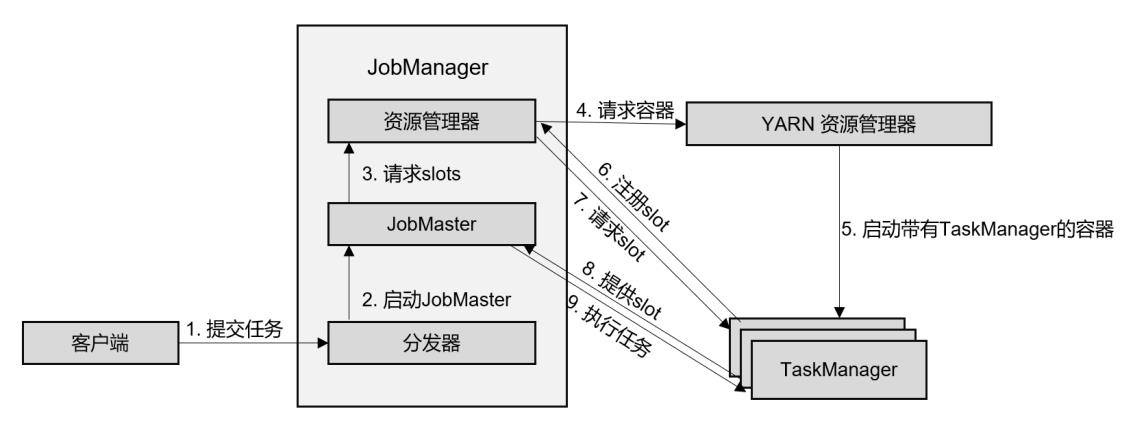
会话模式,应用模式
区别在于jobmaster的启动时间点,会话预先启动,应用在作业提交启动
1 会话 session
在会话模式下,我们需要先启动一个YARN session,这个会话会创建一个 Flink集群。
2 单作业 per-job
flink不会预先启动,在提交作业,才启动新的jobmanager
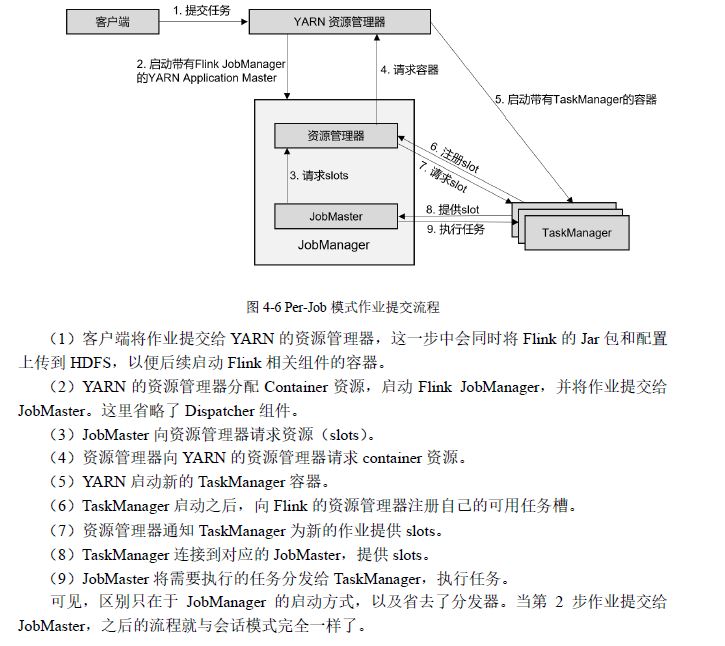
3 应用application
与单作业很相似
区别在于提交给yarn资源管理器的不是具体作业,而是整个应用(包含了多个作业)
数据模型
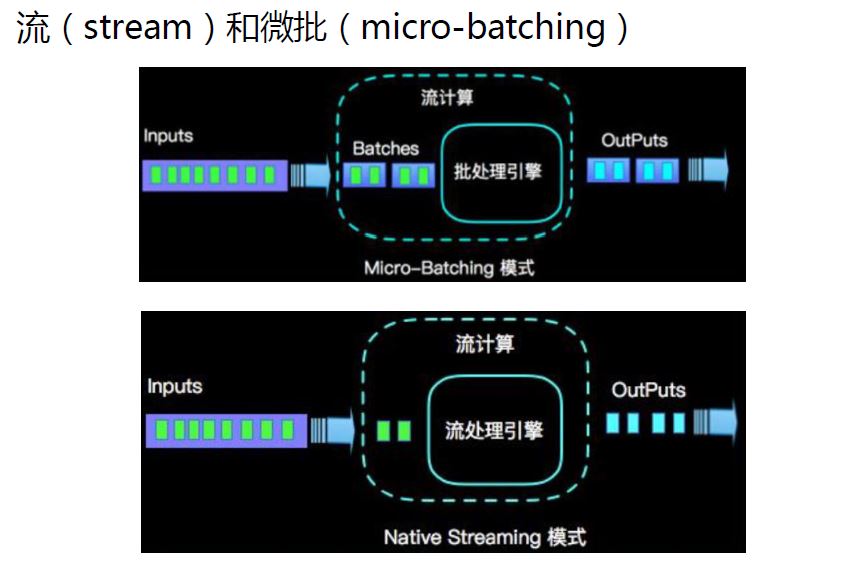
1 spark 采用 RDD 模型, spark streaming 的 DStream 实际上也就是一组 组小批
数据 RDD 的集合
2 flink 基本数据模型是数据流,以及事件( Event )序列
运行时架构
1 spark 是批计算,将 DAG 划分为不同的 stage ,一个完成后才可以计算下一个
2 flink 是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节
点进行处理