https://blog.csdn.net/lmalds/article/details/52704170
https://blog.csdn.net/lightupworld/article/details/116697831
1 介绍
在实际应用中,一般会采用事件时间语义
水位线可以看作在数据流中加入一个时钟标记,记录当前的事件时间;这个标记可以直接广播到下游,当下游任务收到这个标记,就可以更新自己的时钟了。

2 分类
1 有序流的水位线
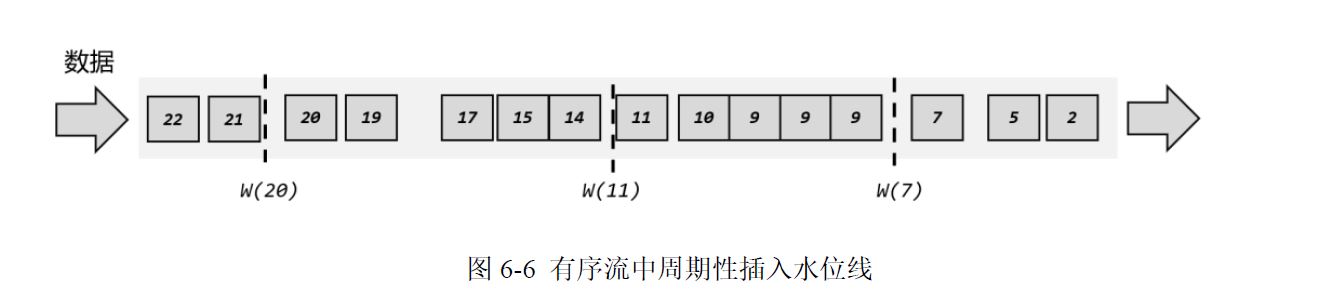
方框是事件时间,虚线是水位线,箭头表示数据到达的顺序,比如事件时间为2的数据第一个到,事件时间为5的数据第二个到
2 乱序流的水位线

比水位线小的数据在后面出现,也就是说本应该在水位线之前出现的数据晚到了,就是迟到数据,迟到数据是丢弃的,比如w(9)后面的8,9

3 如何生成水位线
1 原则
我们知道,完美的水位线是“绝对正确”的,也就是一个水位线一旦出现,就表示这个时间之前的数据已经全部到齐、之后再也不会出现了。而完美的东西总是可望不可即,我们只能尽量去保证水位线的正确。
“等” 或者说“延迟”
为了均衡实时性(少等,会引入大量迟到数据)和准确性(减少迟到数据,多等)
2 怎么写
https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/dev/datastream/event-time/generating_watermarks/
1 assignTimestampsAndWatermarks
1
| Datastream <event> withTimestampsAndWatermarks = stream.assignTimestampsAndWatermarks(WatermarkStrategy)
|
WatermarkStrategy
内置
1
2
| WatermarkStrategy.forMonotonousTimestamps
WatermarkStrategy.forBoundedOutOfOrderness
|
自定义
先实现接口WatermarkGenerator,然后改写一些东西
2 自定义数据源中发送水位线
注意:自定义数据源也可以用assignTimestampsAndWatermarks,这里是指在自定义数据源中实现自己的水位线发送,不用assignTimestampsAndWatermarks
4 水位线传递
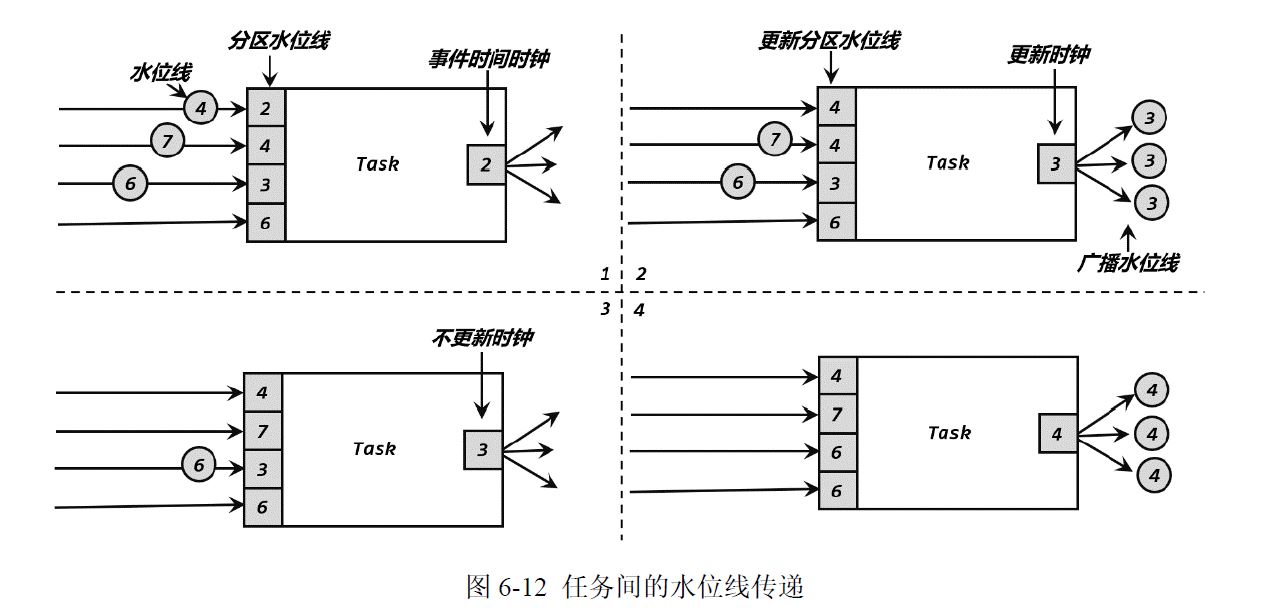
上游并行度为4,下游并行度为3
策略:木桶原理,取得是最小的
为什么木桶原则,以准为第一要义,举个例子图2,如果不是3,是4,那么3不就迟到了吗