flume
1.作用
日志采集
Flume是流式日志采集工具,FLume提供对数据进行简单处理并且写到各种数据接收方(可定制)的能力,Flume提供从本地文件(spooling directory source)、实时日志(taildir、exec)、REST消息、Thift、Avro、Syslog、Kafka等数据源上收集数据的能力。
2.Flume架构
https://jiandansuifeng.blog.csdn.net/article/details/118926483
https://www.jianshu.com/p/9a5c682b0551
三大核心组件:
- Source:数据源
- Channel:临时存储数据的管道
- Sink: 目的地
3.拦截器(interceptor)
https://blog.51cto.com/u_15241496/2869403
拦截器是简单的插件式组件,设置在source和channel之间。source接收到的事件event,在写入channel之前,拦截器都可以进行转换或者删除这些事件。每个拦截器只处理同一个source接收到的事件。可以自定义拦截器。
1 jar包
2 将打包的jar放到XXX/flume/lib
3 配置文件
/opt/module/flume/conf
vim file-flume-kafka.conf
1 | a1.sources.r1.interceptors = i1 |
4.为什么要集成Flume和Kafka
https://blog.csdn.net/qq_37466640/article/details/103425555
5.例子
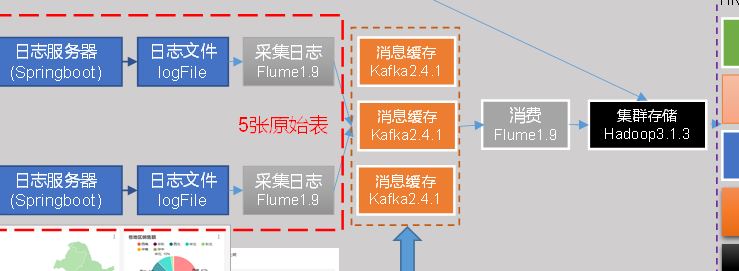
4.1 采集日志
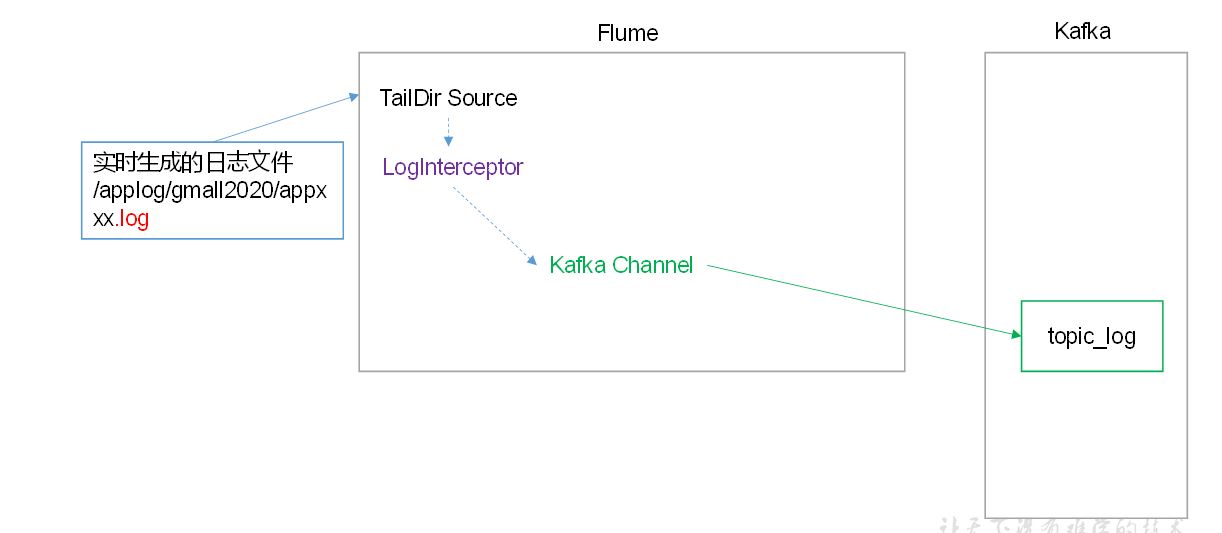
1)Source
(1)Taildir Source相比Exec Source、Spooling Directory Source的优势
TailDir Source:断点续传、多目录。Flume1.6以前需要自己自定义Source记录每次读取文件位置,实现断点续传。不会丢数据,但是有可能会导致数据重复。
Exec Source可以实时搜集数据,但是在Flume不运行或者Shell命令出错的情况下,数据将会丢失。
Spooling Directory Source监控目录,支持断点续传。
(2)batchSize大小如何设置?
答:Event 1K左右时,500-1000合适(默认为100)
2)Channel
采用Kafka Channel,省去了Sink,提高了效率。KafkaChannel数据存储在Kafka里面,所以数据是存储在磁盘中。
注意在Flume1.7以前,Kafka Channel很少有人使用,因为发现parseAsFlumeEvent这个配置起不了作用。也就是无论parseAsFlumeEvent配置为true还是false,都会转为Flume Event。这样的话,造成的结果是,会始终都把Flume的headers中的信息混合着内容一起写入Kafka的消息中,这显然不是我所需要的,我只是需要把内容写入即可。
3)Sink
省去了Sink,提高了效率
4)Interceptor
ETLInterceptor
4.2 消费数据
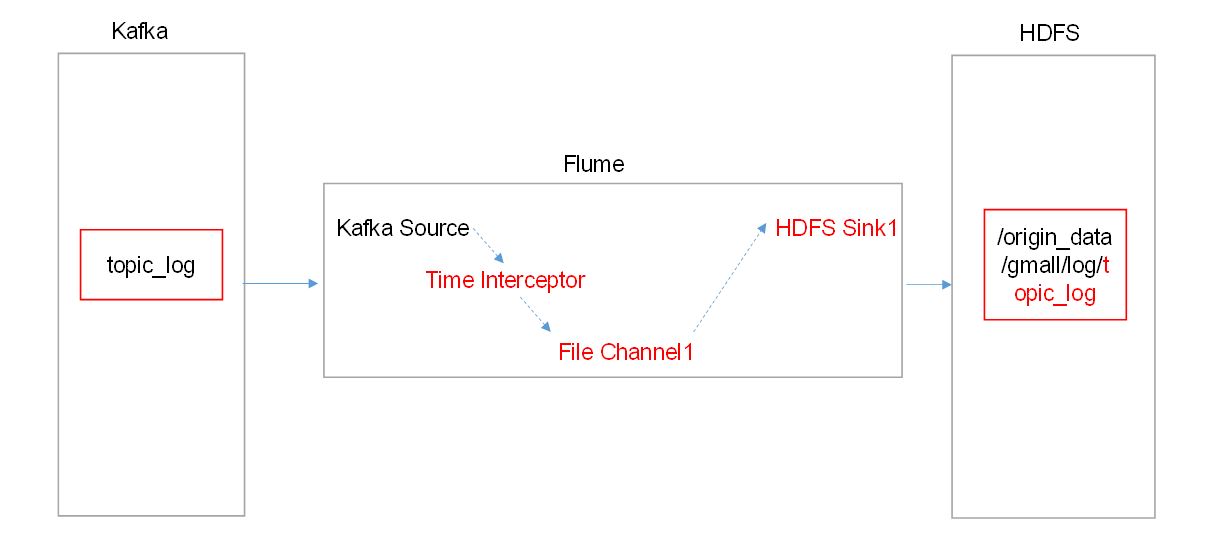
1)Source
2)Channel
MemoryChannel传输数据速度更快,但因为数据保存在JVM的堆内存中,Agent进程挂掉会导致数据丢失,适用于对数据质量要求不高的需求。FileChannel传输速度相对于Memory慢,但数据安全保障高,Agent进程挂掉也可以从失败中恢复数据。
金融类公司、对钱要求非常准确的公司通常会选择FileChannel
传输的是普通日志信息(京东内部一天丢100万-200万条,这是非常正常的),通常选择MemoryChannel。
3)Sink
HDFS Sink
4)Interceptor
TimeStampInterceptor
flume时间拦截器
获取日志中的实际时间