Azkaban
https://blog.csdn.net/wtzhm/article/details/89220508
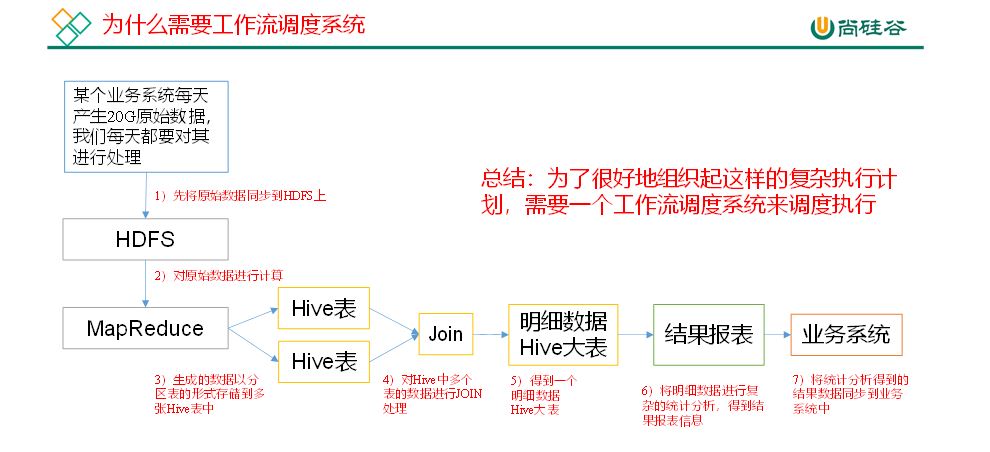
1 为什么需要工作流调度系统
1)一个完整的数据分析系统通常都是由大量任务单元组成:Shell脚本程序,Java程序,MapReduce程序、Hive脚本等
2)各任务单元之间存在时间先后及前后依赖关系
3)为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行
2 常见工作流调度系统
1)简单的任务调度
直接使用Linux的Crontab来定义;
2)复杂的任务调度
开发调度平台或使用现成的开源调度系统,比如Ooize、Azkaban、 Airflow、DolphinScheduler等。
3)Azkaban
Azkaban is a batch workflow job scheduler created at LinkedIn to run Hadoop jobs. Azkaban resolves the ordering through job dependencies and provides an easy to use web user interface to maintain and track your workflows.
Azkaban是一个开源的任务调度系统,用于负责任务的调度运行(如数据仓库调度),用以替代linux中的crontab。
和Oozie对比
总体来说,Ooize相比Azkaban是一个重量级的任务调度系统,功能全面,但配置使用也更复杂。如果可以不在意某些功能的缺失,轻量级调度器Azkaban是很不错的候选对象。
3 使用

1 使用流程
1.数据准备
2.编写Azkaban工作流程配置文件
a.编写azkaban.project
b.编写gmall.flow文件
2 多Executor模式下注意事项
方案一:指定特定的Executor(hadoop102)去执行任务。
a.在MySQL中azkaban数据库executors表中,查询hadoop102上的Executor的id。
b.在执行工作流程时加入useExecutor属性
方案二:在Executor所在所有节点部署任务所需脚本和应用。
推荐使用方案二