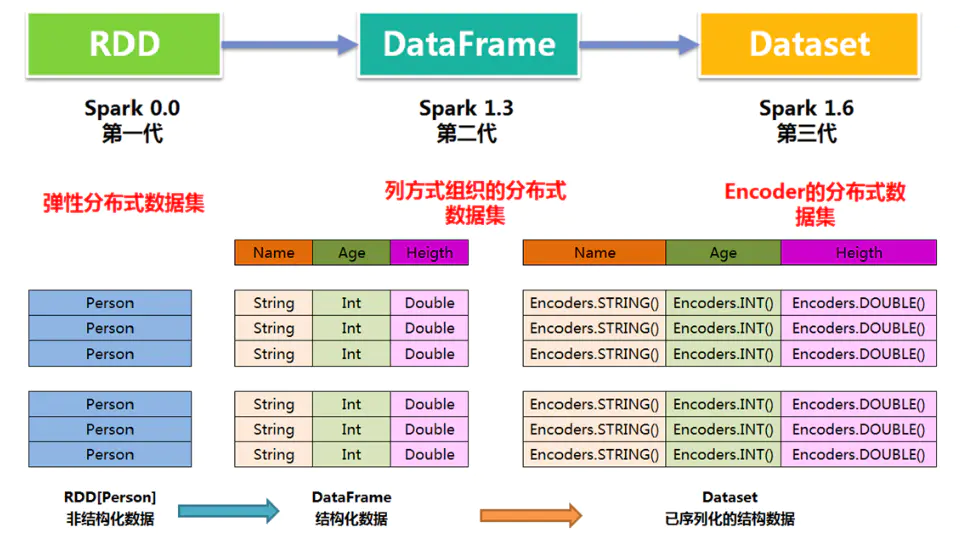
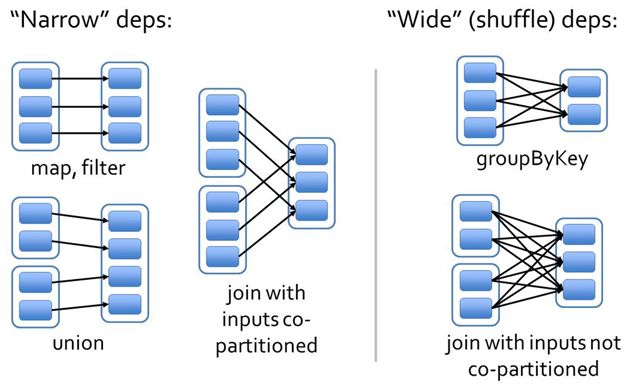
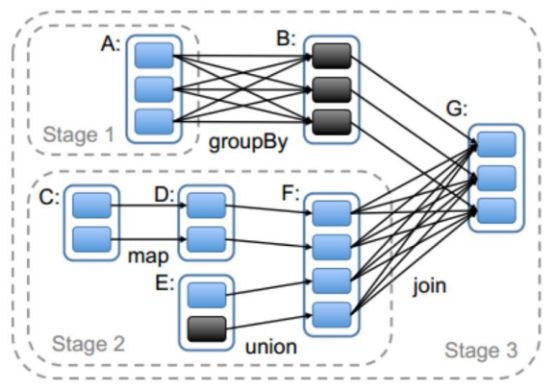
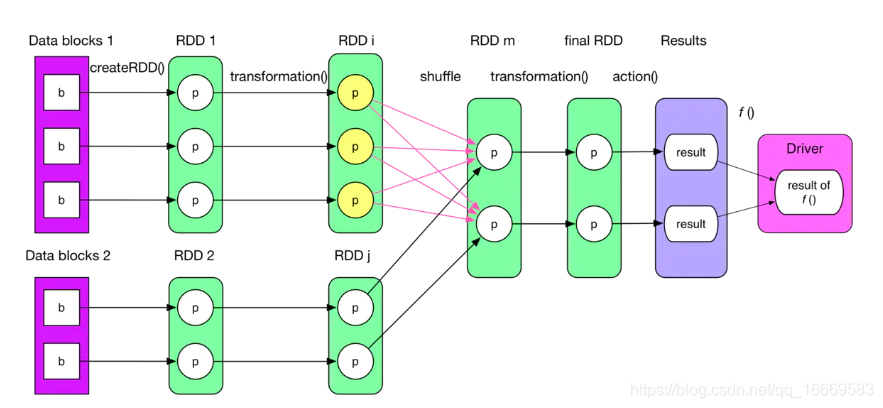
https://blog.csdn.net/qq_37163925/article/details/106260434
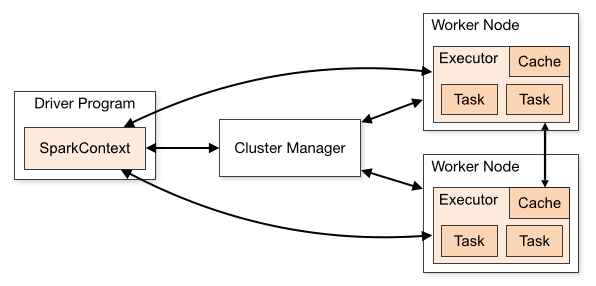
https://spark.apache.org/docs/latest/cluster-overview.html
https://book.itheima.net/course/1269935677353533441/1270998166728089602/1270999667882074115
通过设置mater来选择部署方式。这是Spark程序需要连接的集群管理器所在的URL地址。如果这个属性在提交应用程序的时候没设置,程序将会通过System.getenv(“MASTER”)来获取MASTER环境变量;但是如果MASTER环境变量没有设定,那么程序将会把master的值设定为local[*]
local为单机
standalone是Spark自身实现资源调度
yarn为使用hadoop yarn来实现资源调度
1 local
本地模式就是以一个独立的进程,通过其内部的多个线程来模拟整个Spark运行时环境
local【N】:N为线程数量,通常N为cpu的core的数量
local【*】:cpu的core数量
跑local可以不依赖hadoop
https://blog.csdn.net/wangmuming/article/details/37695619
https://blog.csdn.net/bettesu/article/details/68512570
2 Standalone
https://sfzsjx.github.io/2019/08/26/spark-standalone-%E8%BF%90%E8%A1%8C%E5%8E%9F%E7%90%86
2.1 client
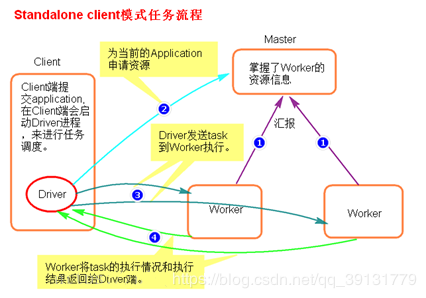
执行流程
- client 模式提交任务后,会在客户端启动Driver进程。
- Driver 会向Master申请启动Application启动资源。
- 资源申请成功后,Driver端会将task发送到worker端执行。
- worker端执行成功后将执行结果返回给Driver端
2.2 cluster
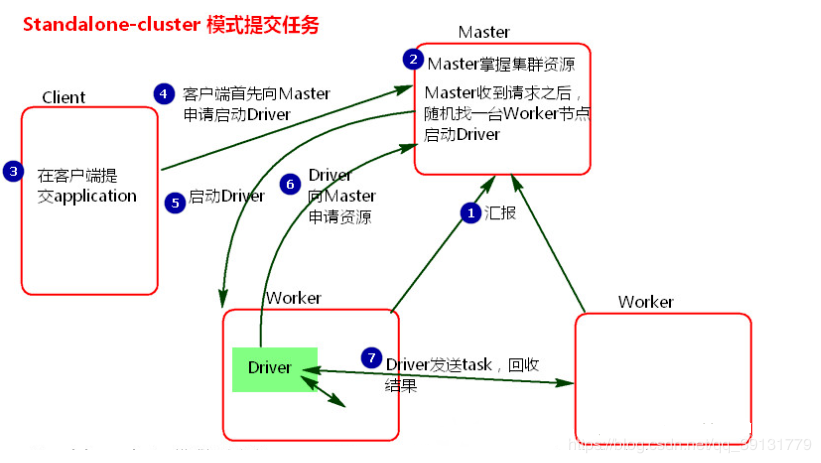
执行流程:
- 客户端使用命令spark-submit –deploy-mode cluster 后会启动spark-submit进程
- 此进程为Driver向Master 申请资源。
- Master会随机在一台Worker节点来启动Driver进程。
- Driver启动成功后,spark-submit关闭,然后Driver向Master申请资源。
- Master接收到请求后,会在资源充足的Worker节点上启动Executor进程。
- Driver分发Task到Executor中执行。
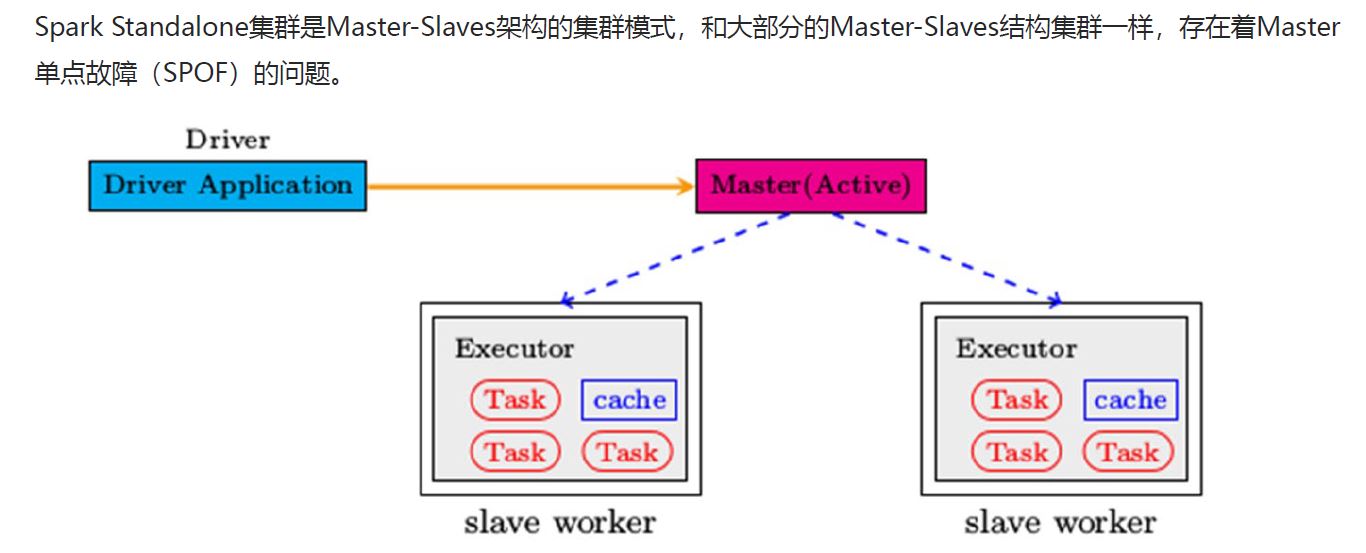
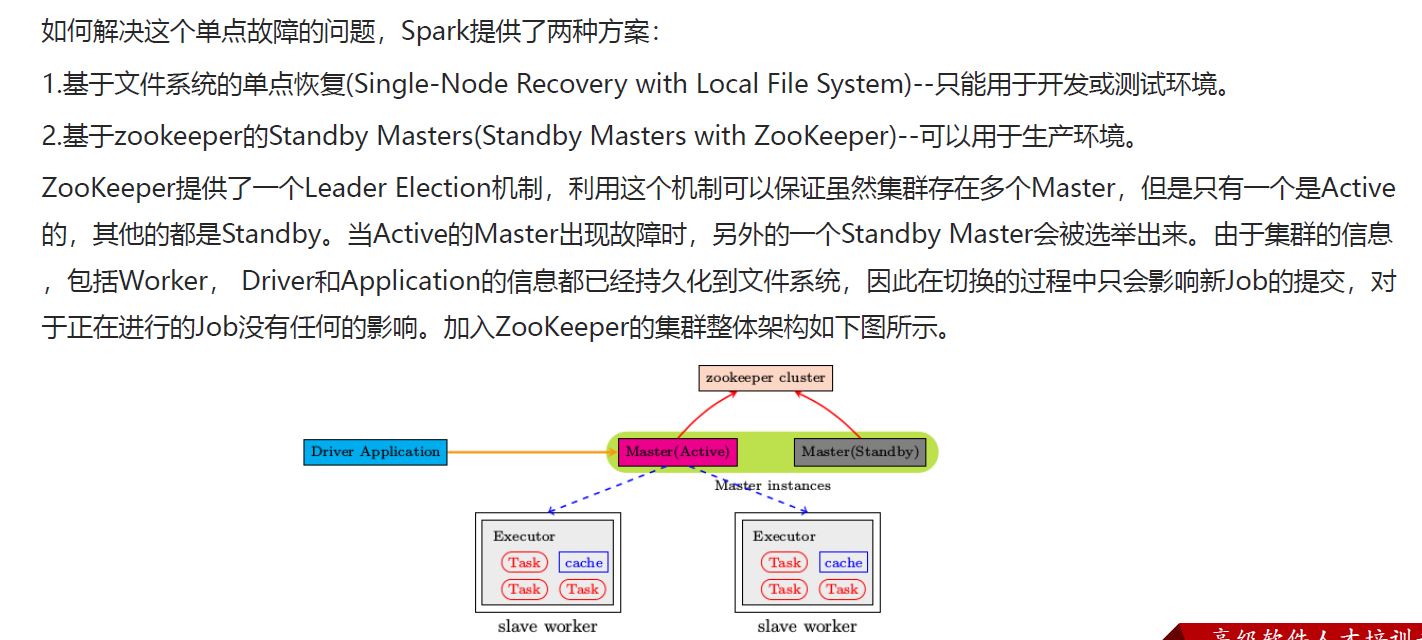
2.3 高可用HA
3 Mesos
a general cluster manager that can also run Hadoop MapReduce and service applications. (Deprecated)
4 YARN
为什么要YARN?
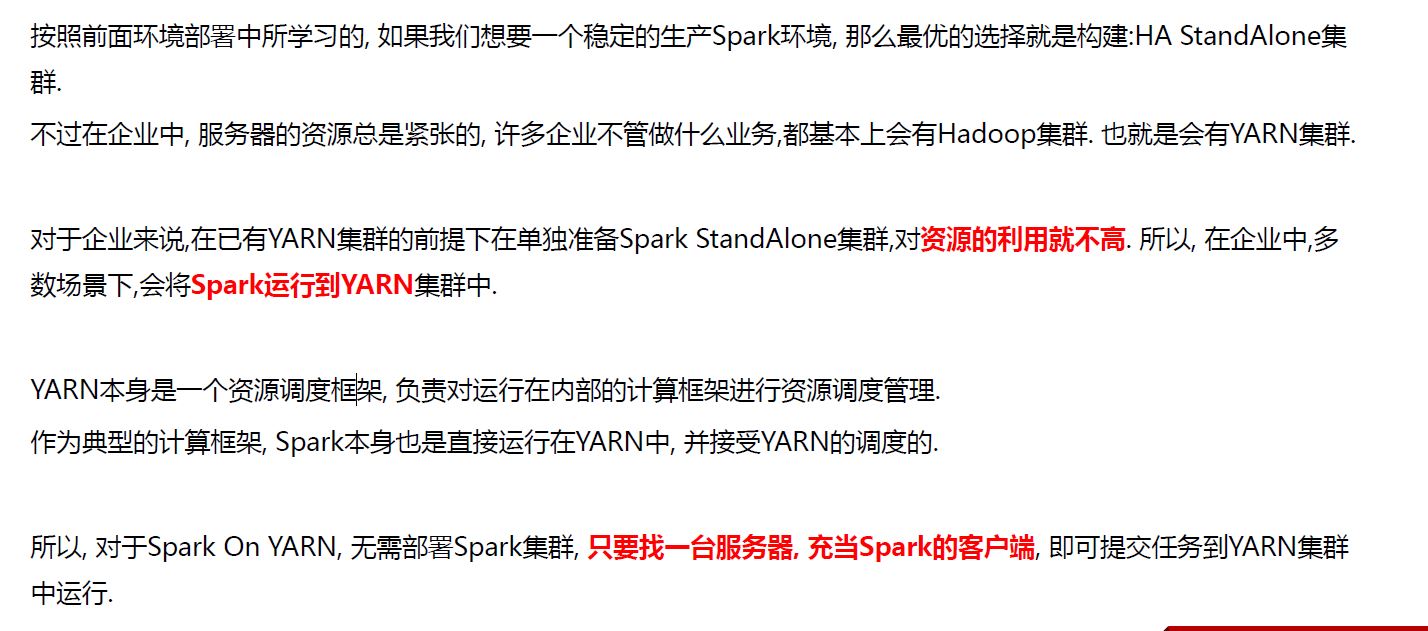
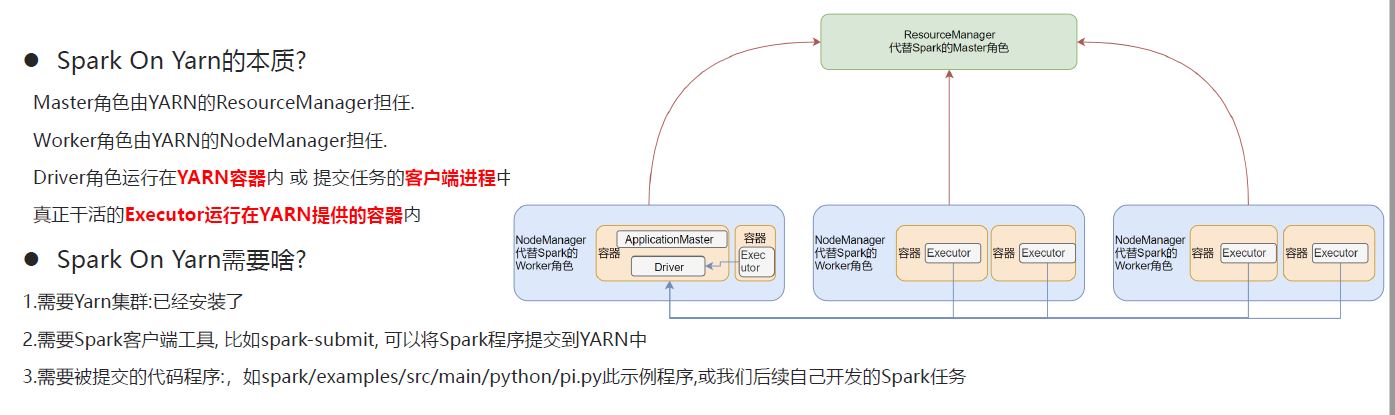
Spark On YARN是有两种运行模式的,一种是Cluster模式一种是Client模式.这两种模式的区别就是Driver运行的位置.
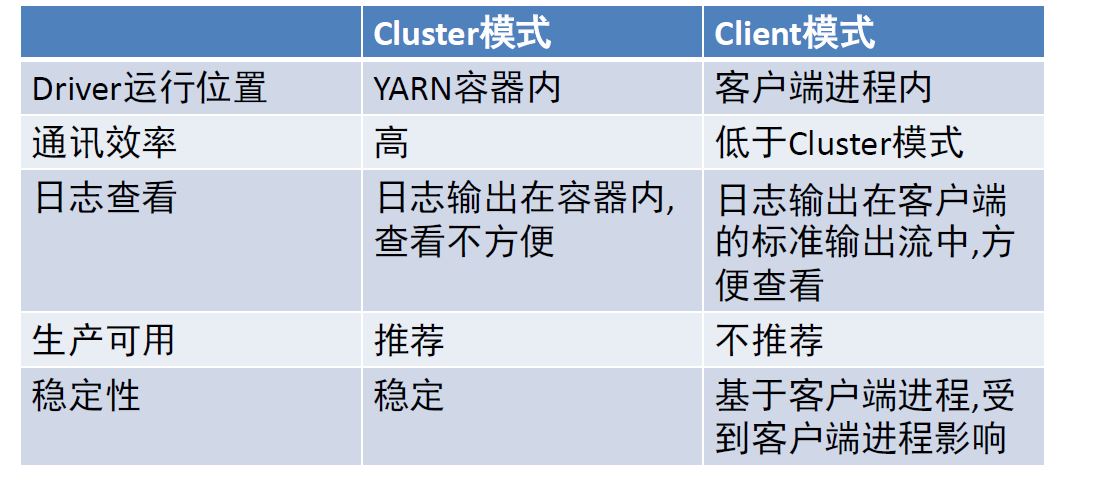
Cluster模式即:Driver运行在YARN容器内部, 和ApplicationMaster在同一个容器内
Client模式即:Driver运行在客户端进程中, 比如Driver运行在spark-submit程序的进程中
4.1 cluster
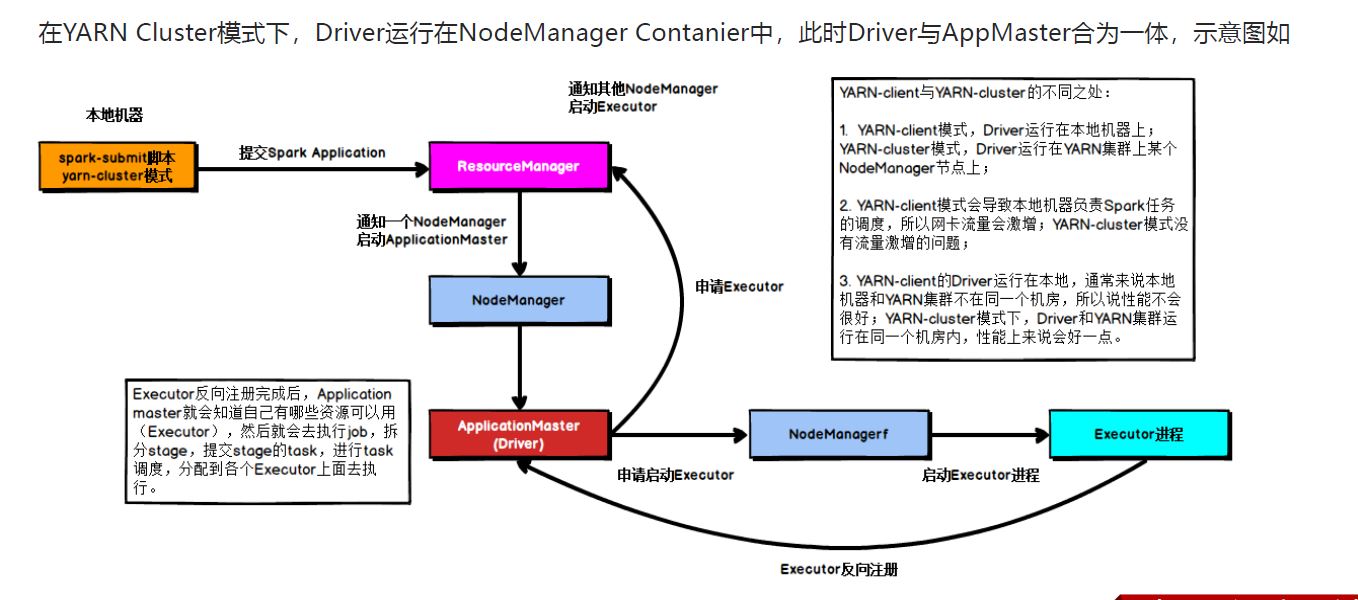
具体流程步骤如下:
1)、任务提交后会和ResourceManager通讯申请启动ApplicationMaster;
2)、随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver;
3)、Driver启动后向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后在合适的NodeManager上启动Executor进程;
4)、Executor进程启动后会向Driver反向注册;
5)、Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行;
4.2 client
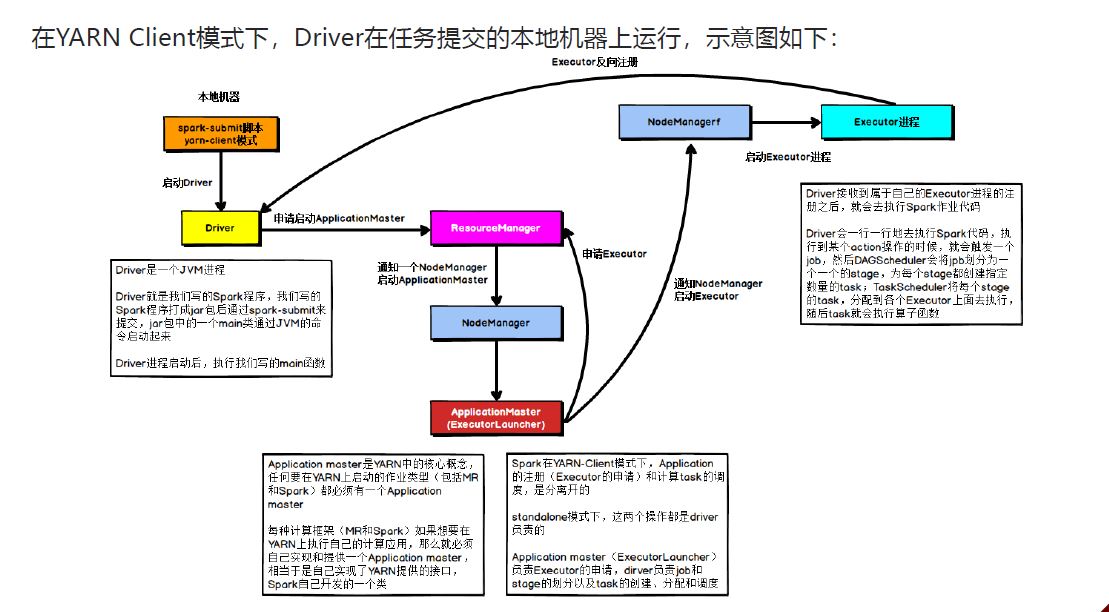
具体流程步骤如下:
1)、Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster;
2)、随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存;
3)、ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程;
4)、Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数;
5)、之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分Stage,每个Stage生成对应的TaskSet,之后将Task分发到各个Executor上执行。
5 Kubernetes
an open-source system for automating deployment, scaling, and management of containerized applications.