流批选择
之前版本
1 | //流 |
现在版本
通过执行模式 execution mode选择
1 流处理 streaming 默认
2 批处理 batch
3 自动 automatic
(1) 通过命令行
1 | flink run -Dexecution.runtime-mode=BATCH/../.. |
(2)代码
1 | env.setRuntimeMode(RuntimeExecutionMode.STREAMING); |
之前版本
1 | //流 |
现在版本
通过执行模式 execution mode选择
1 流处理 streaming 默认
2 批处理 batch
3 自动 automatic
(1) 通过命令行
1 | flink run -Dexecution.runtime-mode=BATCH/../.. |
(2)代码
1 | env.setRuntimeMode(RuntimeExecutionMode.STREAMING); |
1 | CREATE TABLE IF NOT EXISTS `runoob_tbl`( |
https://www.w3school.com.cn/sql/sql_datatypes.asp
array
https://www.educba.com/array-in-sql/
AUTO INCREMENT
1 | CREATE TABLE Persons |
开始值是 1,每条新记录递增 1
main代码 -》 数据流图(dataflow graph,logical streamgraph) -》 作业图(jobgraph)-》执行图(executiongraph)-> 物理图(physical graph)
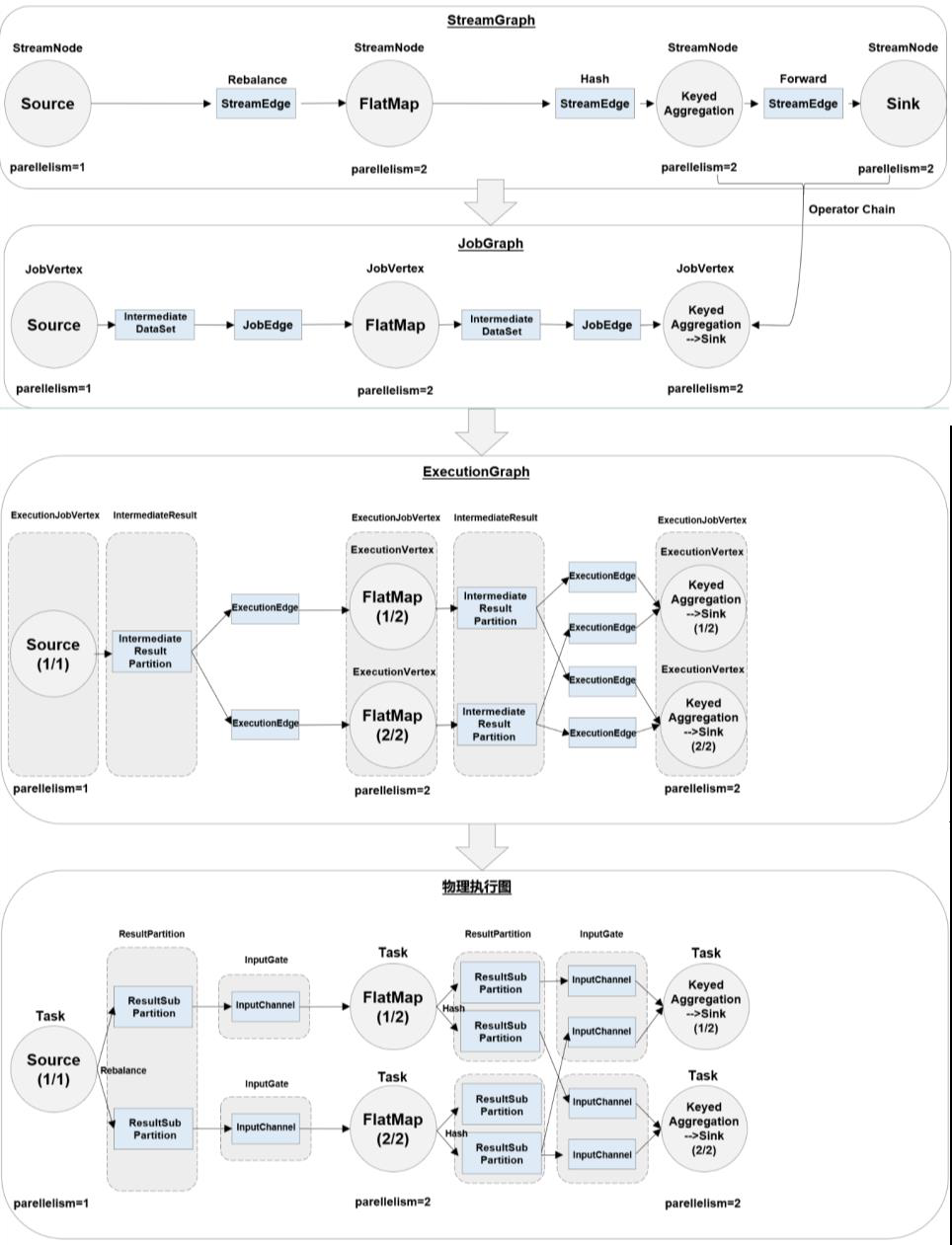

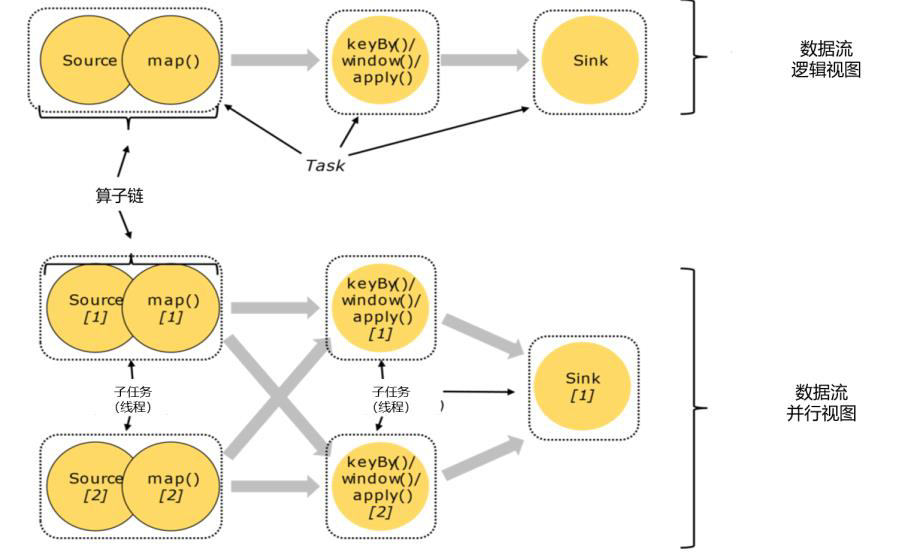
多个算子合并
合并条件:1 并行度相同的算子 2 一对一 one to one
好处:1. 减少线程之间的切换和缓存区的数据交换 2 减少时延 3 提高吞吐量
function分类:普通的,rich
怎么写function:
1 | package com.atguigu.chapter05; |
max maxby 区别
1 | DataStreamSource<Event> stream = env.fromElements( |
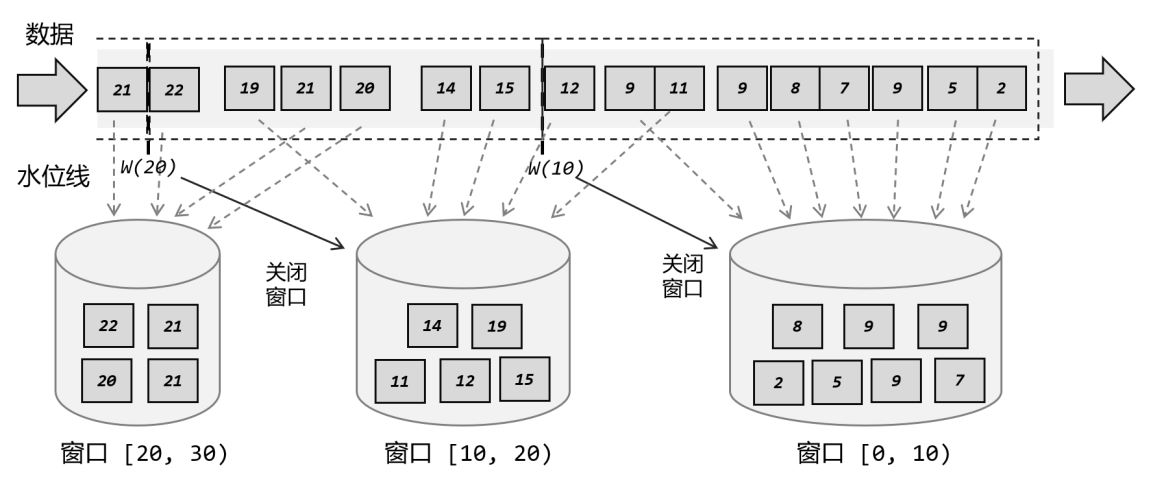
窗口[0-10)中有11,12,但是11,12并不在窗口[0-10)处理,而是在对应的窗口[10,20)处理
(1)时间窗口 Time Window
(2)计数窗口 Count Window
(1)滚动窗口 Tumbling Windows
(2)滑动窗口 Sliding Windows
(3)会话窗口 Session Windows
(4)全局窗口 Global Windows

窗口中 的迟到数据默认会被丢弃,这导致计算结果不够准确
1 设置水位线延迟时间
1 | assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2)) |
2 允许窗口处理迟到数据
1 | .allowedLateness(Time.minutes(1)) |
3 将迟到数据放入侧输出流
收集关窗之后的迟到数据,然后手动处理
1 | .sideOutputLateData(outputTag) |
https://shopify.engineering/optimizing-apache-flink-applications-tips
https://cloud.tencent.com/developer/article/1897249
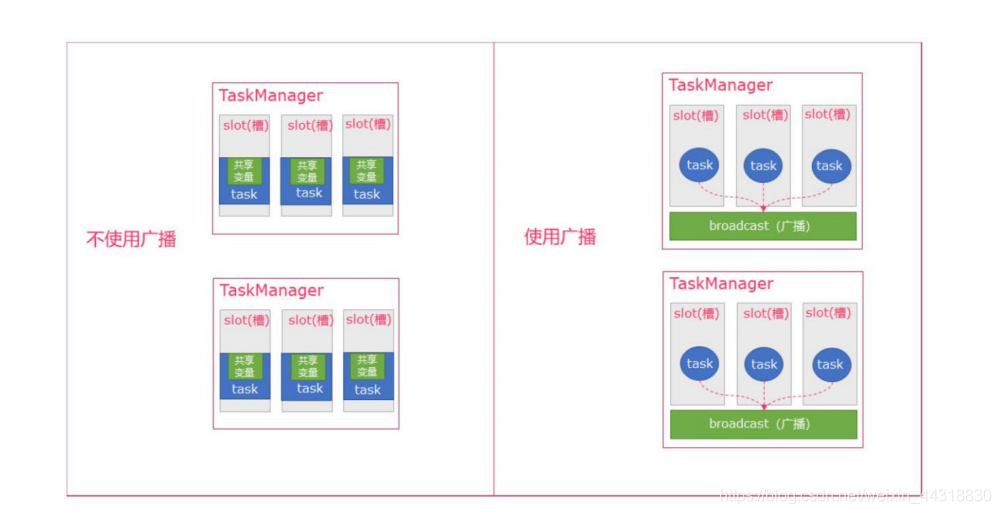
https://blog.csdn.net/weixin_44318830/article/details/107678101
广播是一种操作
如果不使用广播,每一个 Task 都会拷贝一份数据集,造成内存资源浪费 ; 广播后,每个节点存一份,不同的Task 都可以在节点上获取到
1 广播变量
https://blog.csdn.net/yang_shibiao/article/details/118662134
2 广播流
BroadcastStream
3 广播状态
BroadcastState