kafka常见命令
启动命令
1 | /opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties |
关闭命令
1 | /opt/module/kafka/bin/kafka-server-stop.sh stop |
topic
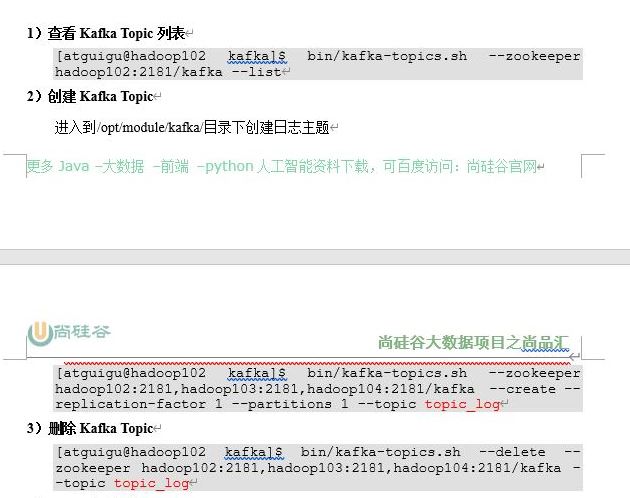

生产

消费

查看消费情况
指定offset
启动命令
1 | /opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties |
关闭命令
1 | /opt/module/kafka/bin/kafka-server-stop.sh stop |
topic
生产
消费
查看消费情况
指定offset
https://blog.csdn.net/yu0_zhang0/article/details/81776459
https://www.jianshu.com/p/28b825367ba1
https://www.jianshu.com/p/d53f528daca7
Hive索引的目标是提高对表的某些列进行查询查找的速度。
索引所能提供的查询速度的提高是以存储索引的磁盘空间为代价的。
Hive 3.0开始将 移除index的功能,取而代之的是Hive 2.3版本开始的物化视图,自动重写的物化视图替代了index的功能。
https://blog.csdn.net/u011447164/article/details/105790713
区别于普通视图
1 | create materialized view view2 |
https://blog.csdn.net/yhb315279058/article/details/51035631
https://www.cnblogs.com/yanshw/p/11988347.html
增加 Driver 内存
1 | --driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M). |
1 读入数据太大
解决思路是增加 Driver 内存
1 | from pyspark import SparkContext |
2 数据回传太大,也就是聚合到driver的数据太大
解决思路是分区输出,具体做法是 foreach
1 | rdd = sc.parallelize(range(100)) |
通用的解决办法就是增加 Executor 内存 但这并不一定是最好的办法
1 map 过程产生大量对象
解决思路是减少每个 task 的大小,从而减少每个 task 的输出
具体做法是在 会产生大量对象的 map 操作前 添加 repartition(重新分区) 方法,分区成更小的块传入 map
1 | rdd.flatMap(lambda x: ['%d'%x*50 for _ in range(100000000)]).count() # 100 * 100000000 个对象,内存溢出 |
2 shuffle导致
shuffle内存溢出的情况可以说都是shuffle后发生数据倾斜,单个文件过大导致
参考数据倾斜解决方案
https://blog.csdn.net/JasonDing1354/article/details/46882585
https://blog.csdn.net/dengxing1234/article/details/73613484
容错指的是一个系统在部分模块出现故障时还能否持续的对外提供服务
https://www.jianshu.com/p/d518e9f5d5f9
1 好处
a. 提高代码可读性
结构清晰
b. 优化执行速度
子查询结果存在内存中,不需要重复计算
2 用法
1 | with table_name as(子查询语句) 其他sql; |
1 | with temp as ( |
与基本表不同,它是一个虚表。在数据库中,存放的只是视图的定义,而不存放视图包含的数据项,这些项目仍然存放在原来的基本表结构中。
视图是只读的,不能向视图中插入或加载或改变数据
作用:
1 便捷
通过引入视图机制,用户可以将注意力集中在其关心的数据上(而非全部数据),这样就大大提高了用户效率与用户满意度,而且如果这些数据来源于多个基本表结构,或者数据不仅来自于基本表结构,还有一部分数据来源于其他视图,并且搜索条件又比较复杂时,需要编写的查询语句就会比较烦琐,此时定义视图就可以使数据的查询语句变得简单可行。
2 安全
定义视图可以将表与表之间的复杂的操作连接和搜索条件对用户不可见,用户只需要简单地对一个视图进行查询即可,故增加了数据的安全性,但不能提高查询效率。
创建
1 | CREATE VIEW [IF NOT EXISTS] view_name [(column_name [COMMENT column_comment], ...) ] |
删除
1 | DROP VIEW view_name |
https://www.studytime.xin/article/hive-knowledge-function.html
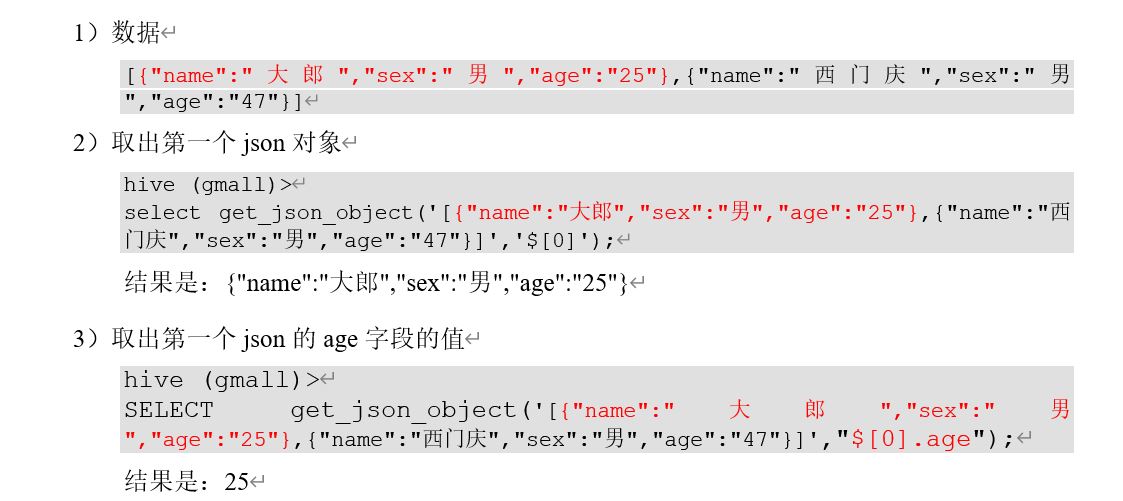
1 get_json_object
https://blog.csdn.net/weixin_43412569/article/details/105290637
2 nvl
空值判断转换函数
https://blog.csdn.net/a850661962/article/details/101209028
3 coalesce
https://blog.csdn.net/yilulvxing/article/details/86595725
1 | select coalesce(success_cnt,period,1) from tableA |
当success_cnt不为null,那么无论period是否为null,都将返回success_cnt的真实值(因为success_cnt是第一个参数),当success_cnt为null,而period不为null的时候,返回period的真实值。只有当success_cnt和period均为null的时候,将返回1。
4 collect_list和collect_set
https://blog.csdn.net/weixin_30230059/article/details/113324945
https://blog.csdn.net/qq_44104303/article/details/117551807
它们都是将分组中的某列转为一个数组返回,不同的是collect_list不去重而collect_set去重。
5 named_struct
https://blog.csdn.net/weixin_43597208/article/details/117554838
做字段拼接
区别于struct,struct 是集合数据类型,一般用于建表,named_struct是字段拼接函数,一般用于查询
6 array_contains()
1 | array_contains(array,值) |
判断array中是否包含某个值,包含返回true,不包含返回false
7 cast
https://www.jianshu.com/p/999176fa2730
显式的将一个类型的数据转换成另一个数据类型
1 | Cast(字段名 as 转换的类型 ) |
UDF(User-Defined-Function):单入单出
UDTF(User-Defined Table-Generating Functions):单入多出
UDAF(User Defined Aggregation Function):多入单出
https://blog.csdn.net/qq_40579464/article/details/105903405
1.编写代码
jar不能随意编写,需要和hive对齐接口,可以借助工具import org.apache.hadoop.hive.ql.exec.UDF;
1 | 1 public class classname extends UDF |
https://blog.csdn.net/eyeofeagle/article/details/83904147
2.打包
3.导入hive
复制到hdfs上
Hive安装目录的lib目录下
4.创建关联
add jar hdfs://localhost:9000/user/root/hiveudf.jar
create temporary function my_lower as ‘com.example.hive.udf.LowerCase’;
5.使用
hql udf的使用和普通内置函数一样,比如有udf1
1 | select udf1(col1) from table1 |
https://www.cnblogs.com/bjlhx/p/6946422.html
https://blog.csdn.net/m0_49092046/article/details/109251015
1 | load data [local] inpath ‘/opt/module/datas/student.txt’ [overwrite] | into table tabName [partition (partcol1=val1,…)]; |
(1)load data:表示加载数据
(2)local:表示从本地加载数据到 hive 表;否则从 HDFS 加载数据到 hive 表
(3)inpath:表示加载数据的路径
(4)overwrite:表示覆盖表中已有数据,否则表示追加
(5)into table:表示加载到哪张表
(6)tabName:表示具体的表
(7)partition:表示上传到指定分区
例子:
1 | load data inpath '/origin_data/gmall/log/topic_log/2020-06-14' into table ods_log partition(dt='2020-06-14') |
https://help.aliyun.com/document_detail/73775.html
insert into 和insert overwrite
1 | 1 |
https://www.jianshu.com/p/4f60f3c923fe
https://blog.csdn.net/Thomson617/article/details/86153924
1 | CREATE EXTERNAL TABLE dim_sku_info ( |
1 EXTERNAL
关键字可以让用户创建一个外部表,默认是内部表
2 字段的数据类型
https://blog.csdn.net/weixin_46941961/article/details/108551512
https://blog.csdn.net/weixin_43215250/article/details/90034169
集合数据类型:Array、Map和Struct
https://www.jianshu.com/p/5dbbaea8ff41
PARTITIONED BY (dt string)
0 分类
静态分区SP(static partition)
动态分区DP(dynamic partition)
静态分区与动态分区的主要区别在于静态分区是手动指定,而动态分区是通过数据来进行判断。
1 静态分区
1 | --建表 |
2 动态分区
注意分区字段dt数据来源于date_format(create_time,’yyyy-MM-dd’)
和静态分区比较,建表的时候没区别,加载数据有区别
1 | --建表 |
LOCATION ‘/warehouse/gmall/ods/ods_log’
指定数据在hdfs上的存储位置
https://www.imooc.com/article/12213
https://blog.csdn.net/S_Running_snail/article/details/84258162
指定数据切分格式
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’
https://blog.csdn.net/ZZQHELLO2018/article/details/106175887
指定存储方式
行式存储:TEXTFILE 、SEQUENCEFILE 列式存储: ORC、PARQUET
https://blog.csdn.net/yangguosb/article/details/83651073
TBLPROPERTIES是表的一些属性,HIVE内置了一部分属性,使用者也可以在创建表时进行自定义;
TBLPROPERTIES (“parquet.compression”=”lzo”);
https://blog.csdn.net/Zhangxichao100/article/details/55099118
1 insert
insert into table (姓名,性别,出生日期) values (‘王伟华’,’男’,’1983/6/15’)
insert into table (‘姓名’,’地址’,’电子邮件’)select name,address,email from Strdents
2 SELECT INTO
1 | SELECT column_name |
1 delete
删除数据某些数据
delete from table where name=’王伟华’
2 truncate
删除整个表的数据
truncate table addressList
1 update
update table set 年龄=18 where 姓名=’王伟华’
1 select
Hive MetaStore - It is a central repository that stores all the structure information of various tables and partitions in the warehouse. It also includes metadata of column and its type information, the serializers and deserializers which is used to read and write data and the corresponding HDFS files where the data is stored.
Embedded,Local,Remote
https://blog.csdn.net/epitomizelu/article/details/117091656
https://zhuanlan.zhihu.com/p/473378621
https://blog.csdn.net/qq_40990732/article/details/80914873