kafka常见问题
1 kafka启动后一段时间自动退出的解决方案
https://blog.csdn.net/weixin_46303867/article/details/115256466
2 ERROR Shutdown broker because all log dirs in … have failed
https://blog.csdn.net/szxiaohe/article/details/103639127
https://blog.csdn.net/weixin_46303867/article/details/115256466
https://blog.csdn.net/szxiaohe/article/details/103639127
经验公式:Kafka机器数量= 2 (峰值生产速度 副本数 / 100)+ 1
1)峰值生产速度
峰值生产速度可以压测得到。
2)副本数
副本数默认是1个,在企业里面2-3个都有,2个居多。
副本多可以提高可靠性,但是会降低网络传输效率。
例子:
先拿到峰值生产速度,再根据设定的副本数,就能预估出需要部署Kafka的数量。
比如我们的峰值生产速度是50M/s。副本数为2。
Kafka机器数量 = 2 (50 2 / 100)+ 1 = 3台
(1)创建一个只有1个分区的topic
(2)测试这个topic的producer吞吐量和consumer吞吐量。
(3)假设他们的值分别是Tp和Tc,单位可以是MB/s。
(4)然后假设总的目标吞吐量是Tt,那么分区数 = Tt / min(Tp,Tc)
例如:producer吞吐量 = 20m/s;consumer吞吐量 = 50m/s,期望吞吐量100m/s;分区数 = 100 / 20 = 5分区
https://blog.csdn.net/weixin_42641909/article/details/89294698
分区数一般设置为:3-10个
https://www.lilinchao.com/archives/1548.html
https://developer.51cto.com/article/658581.html
过去
Apache Kafka的一个关键依赖是Apache Zookeeper,它是一个分布式配置和同步服务。 Zookeeper是Kafka代理和消费者之间的协调接口。 Kafka服务器通过Zookeeper集群共享信息。 Kafka在Zookeeper中存储基本元数据,例如关于主题,代理,消费者偏移(队列读取器)等的信息。
由于所有关键信息存储在Zookeeper中,并且它通常在其整体上复制此数据,因此Kafka代理/ Zookeeper的故障不会影响Kafka集群的状态。 Kafka将恢复状态,一旦Zookeeper重新启动。 这为Kafka带来了零停机时间。 Kafka代理之间的领导者选举也通过使用Zookeeper在领导者失败的情况下完成。
未来
Kafka 2.8.0,移除了对Zookeeper的依赖,通过KRaft进行自己的集群管理
核心思路:分别指定driver和excutor的python版本,使其统一
方法一:修改环境变量
1./在环境变量文件 /etc/profile 中添加指定的pyspark,python的版本
1 | export PYSPARK_PYTHON=指定的python路径 |
保存后source一下 /etc/profile ,使之生效
2.代码内指定
1 | os.environ["PYSPARK_DRIVER_PYTHON"]="" ##driver |
方法二:spark-submit工具指定
在spark-submit时增加参数 --conf spark.pyspark.python和 --conf spark.pyspark.driver.python
1 | spark-submit \ |
说明spark没有连接到hive
groupByKey creates a lot of shuffling which hampers the performance, while reduceByKey does not shuffle the data as much
https://cloud.tencent.com/developer/article/1760389
https://blog.csdn.net/dudadudadd/article/details/114102341
https://yiqingqing.blog.csdn.net/article/details/121772325
https://blog.csdn.net/feizuiku0116/article/details/122839247
https://blog.csdn.net/CyAurora/article/details/119654676
https://www.cnblogs.com/Transkai/p/11347224.html
https://blog.csdn.net/CyAurora/article/details/119654676
https://blog.csdn.net/dudadudadd/article/details/114102341
懒执行
空间换时间
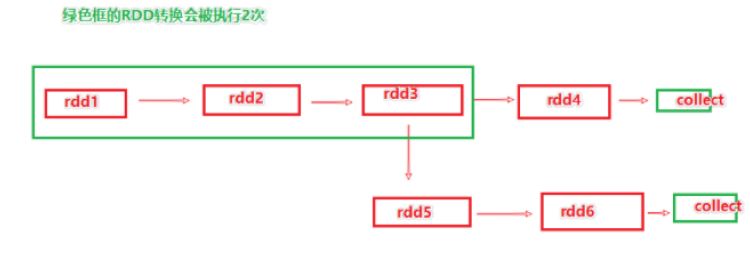
rdd3如果不消失,那么绿色链路就不用执行两次
持久化的目标就是将rdd3保存到内存或者磁盘
但是有丢失风险,比如硬盘损坏,内存被清理等,所以为了规避风险,会保留rdd的血缘(依赖)关系
如何保存:
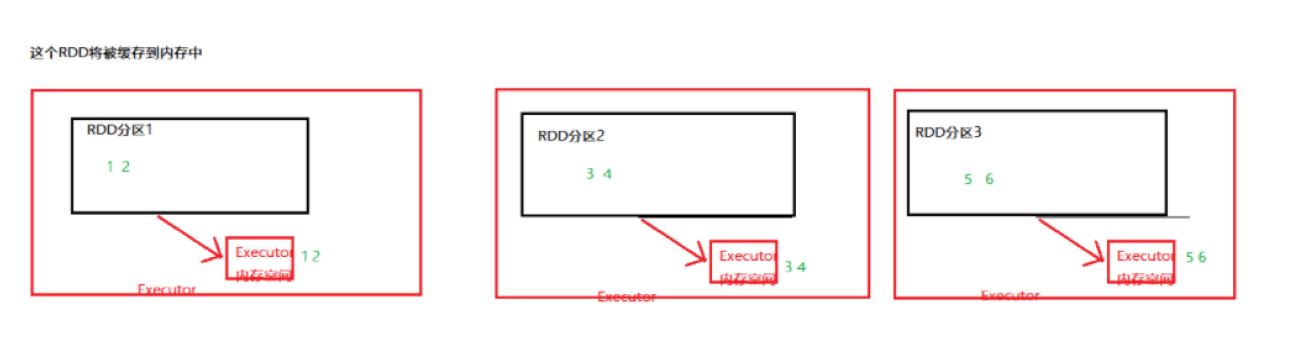
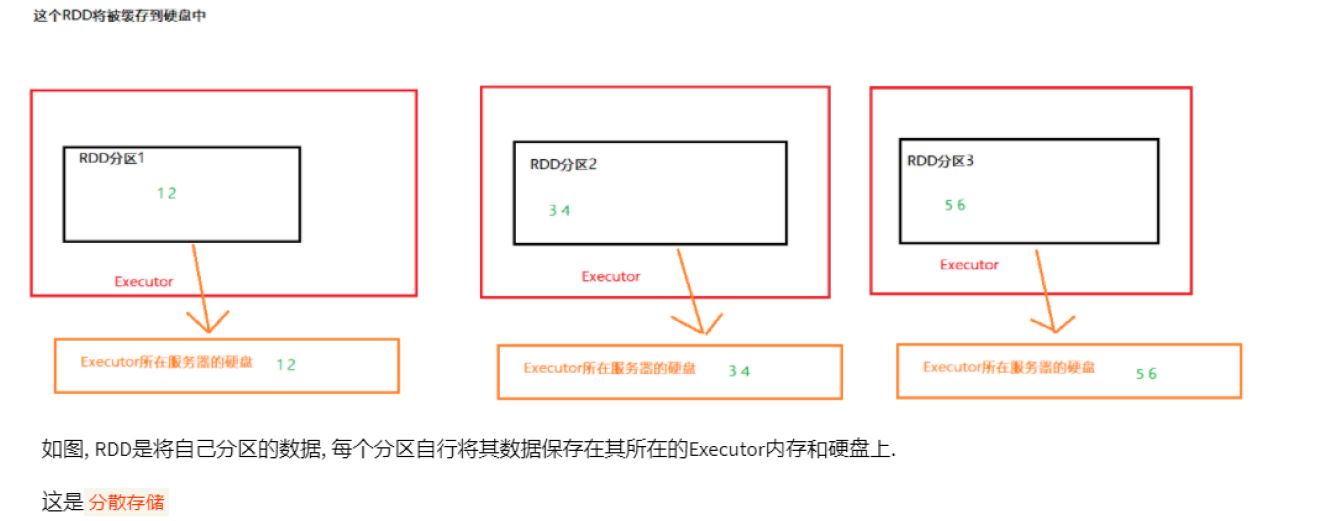

https://blog.csdn.net/donger__chen/article/details/86366339
底层调用persist,persist的特殊情况,persist(MEMORY_ONLY)
特殊的持久化
仅支持硬盘
设计上认为安全没有风险,所以不需要保留血缘关系
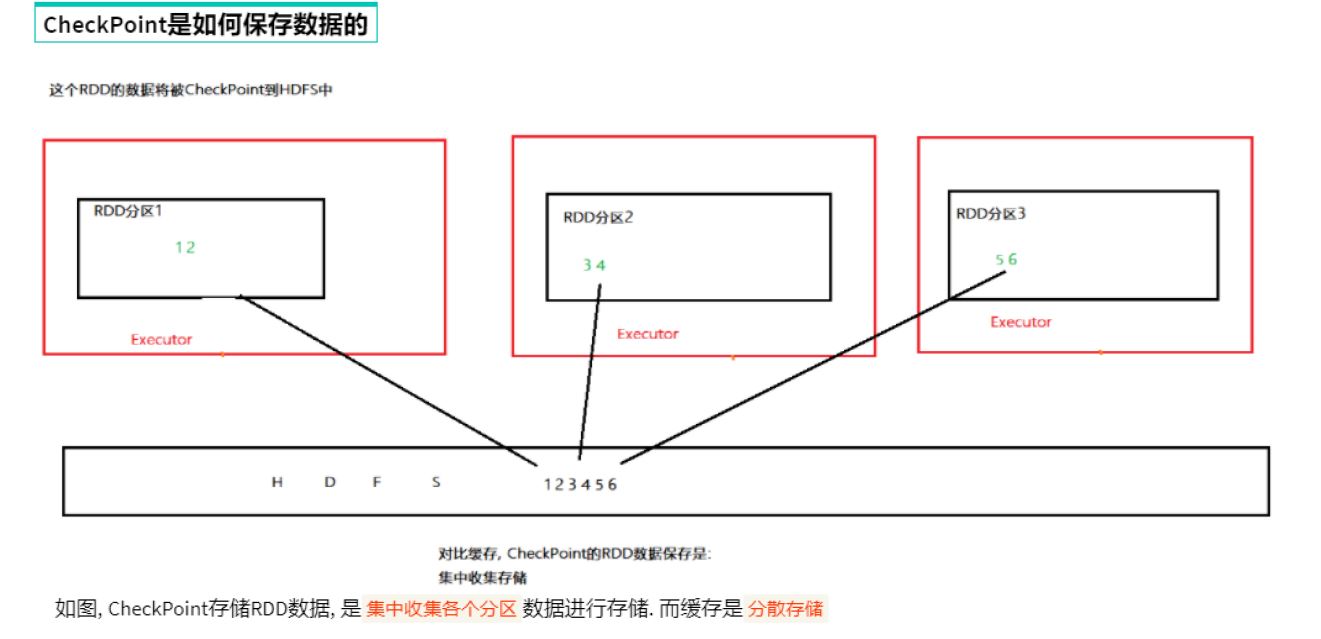
如何保存:


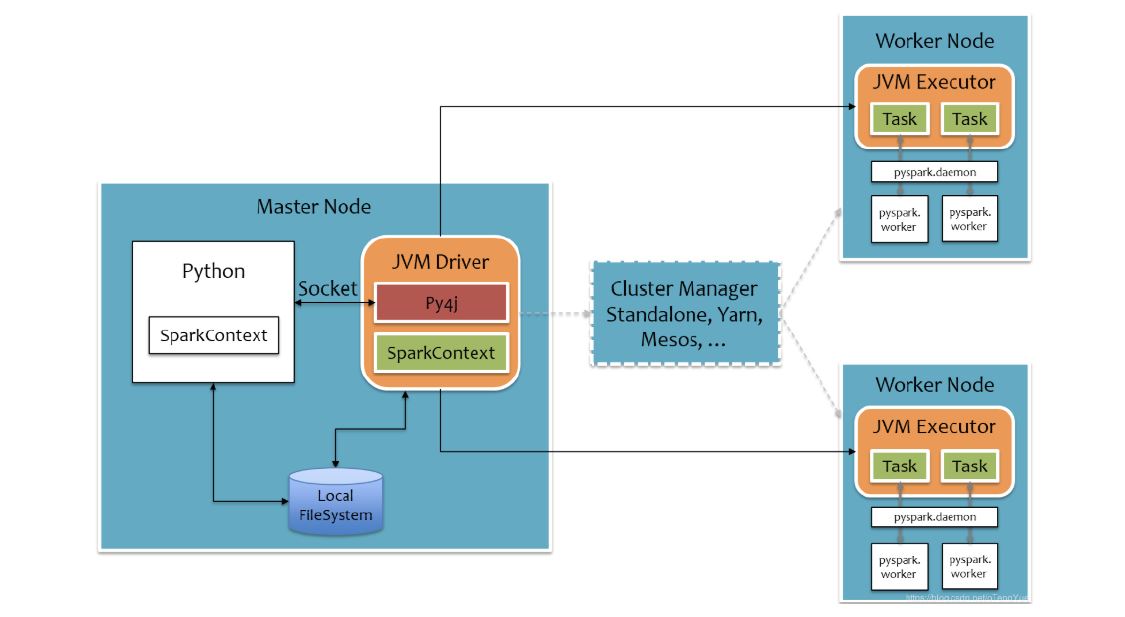
PySpark宗旨是在不破坏Spark已有的运行时架构,在Spark架构外层包装一层Python API,借助Py4j实现Python和Java的交互,进而实现通过Python编写Spark应用程序