https://blog.csdn.net/u010886217/article/details/82916401
spark-shell、spark-sql,thriftserver
https://blog.csdn.net/u010886217/article/details/82916401
spark-shell、spark-sql,thriftserver
核心思路:分别指定driver和excutor的python版本,使其统一
方法一:修改环境变量
1./在环境变量文件 /etc/profile 中添加指定的pyspark,python的版本
1 | export PYSPARK_PYTHON=指定的python路径 |
保存后source一下 /etc/profile ,使之生效
2.代码内指定
1 | os.environ["PYSPARK_DRIVER_PYTHON"]="" ##driver |
方法二:spark-submit工具指定
在spark-submit时增加参数 --conf spark.pyspark.python和 --conf spark.pyspark.driver.python
1 | spark-submit \ |
说明spark没有连接到hive
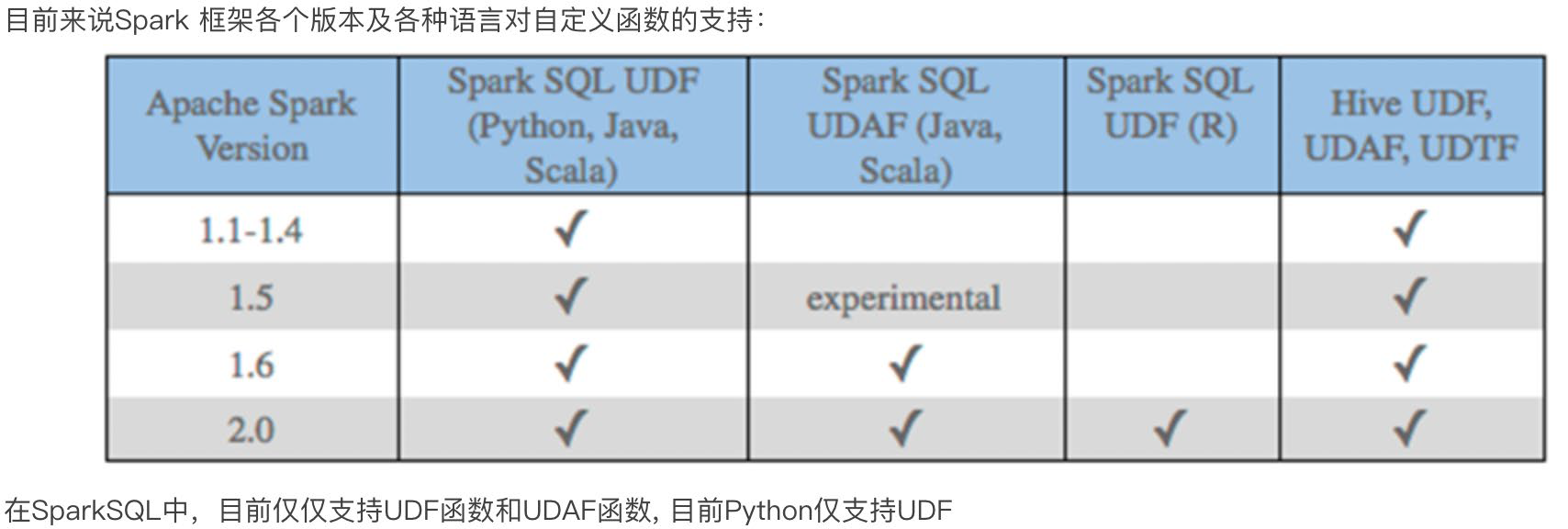
DataFrame支持两种风格进行编程,分别是:
DSL称之为:领域特定语言。
其实就是指DataFrame的特有API
DSL风格意思就是以调用API的方式来处理Data
比如:df.where().limit()
SQL语法风格
SQL风格就是使用SQL语句处理DataFrame的数据
比如:spark.sql(“SELECT * FROM xxx)

步骤:
https://blog.csdn.net/qq_43665254/article/details/112379113
https://blog.csdn.net/sunflower_sara/article/details/104044412
1、定义函数
2、注册函数
3、使用函数
1 | from pyspark.sql.functions import col, lit |
算子就是分布式集合对象的api
rdd算子分为两类:1.transformation 2.action
https://blog.csdn.net/weixin_45271668/article/details/106441457
https://blog.csdn.net/Android_xue/article/details/79780463
https://chowdera.com/2022/02/202202091419262471.html
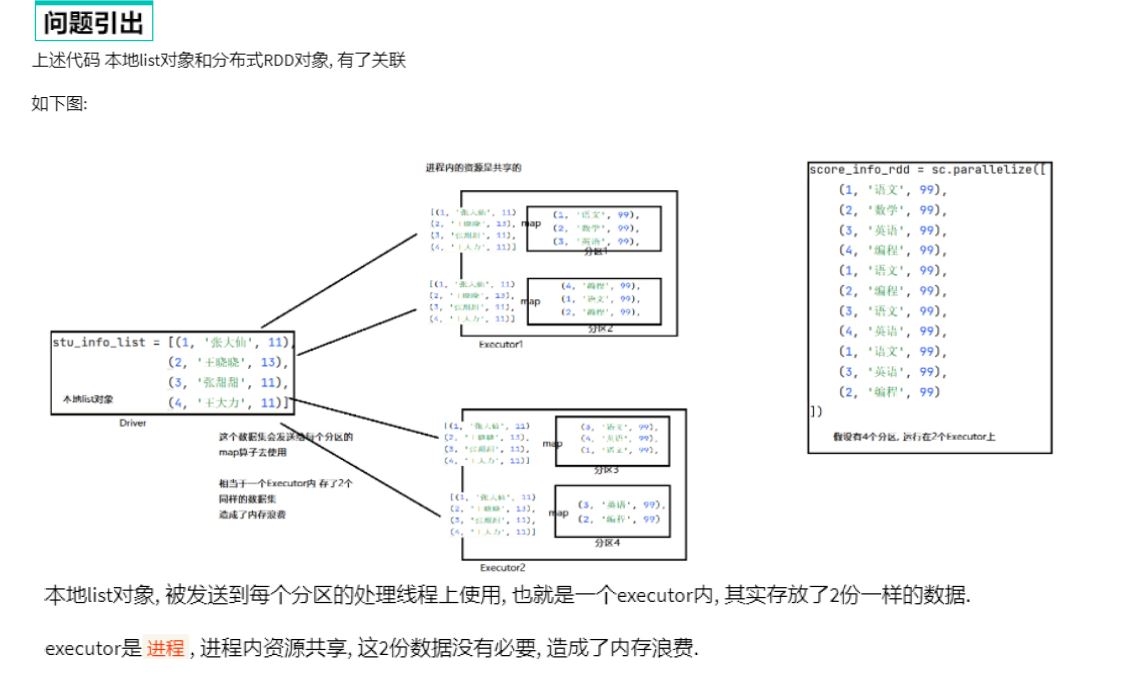
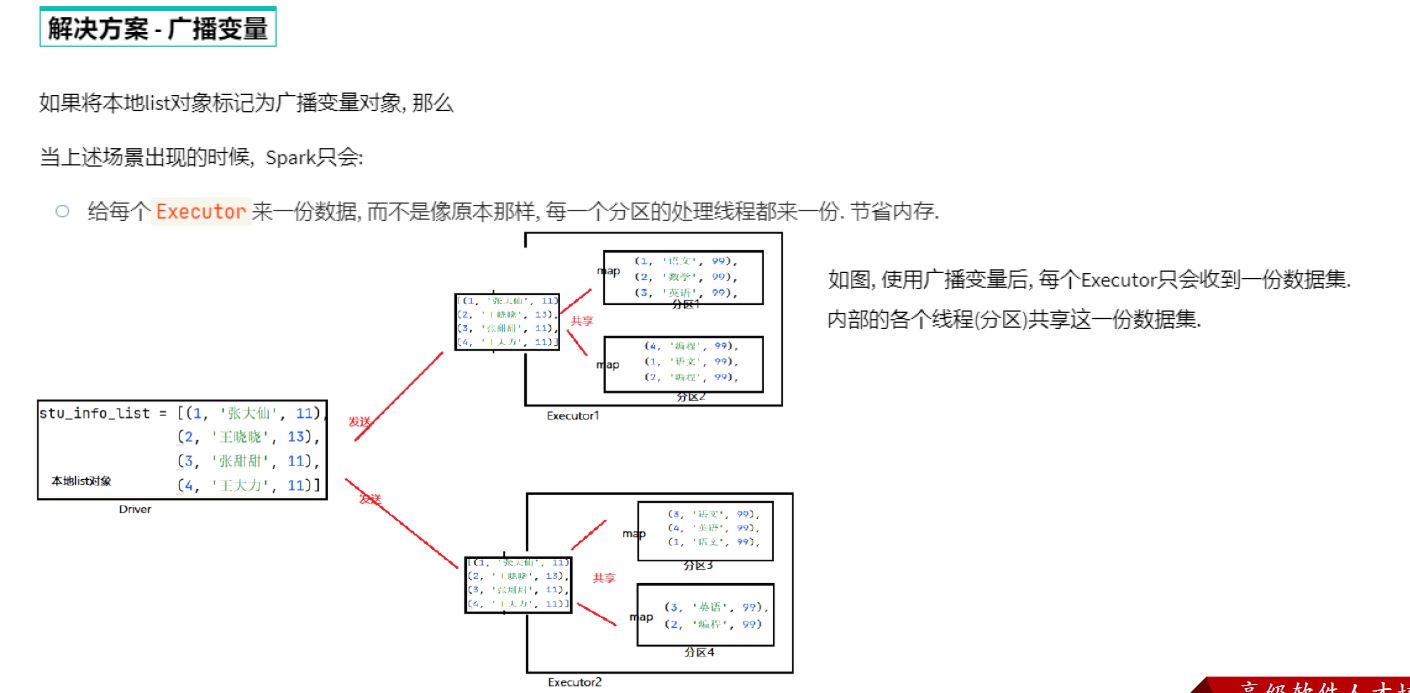
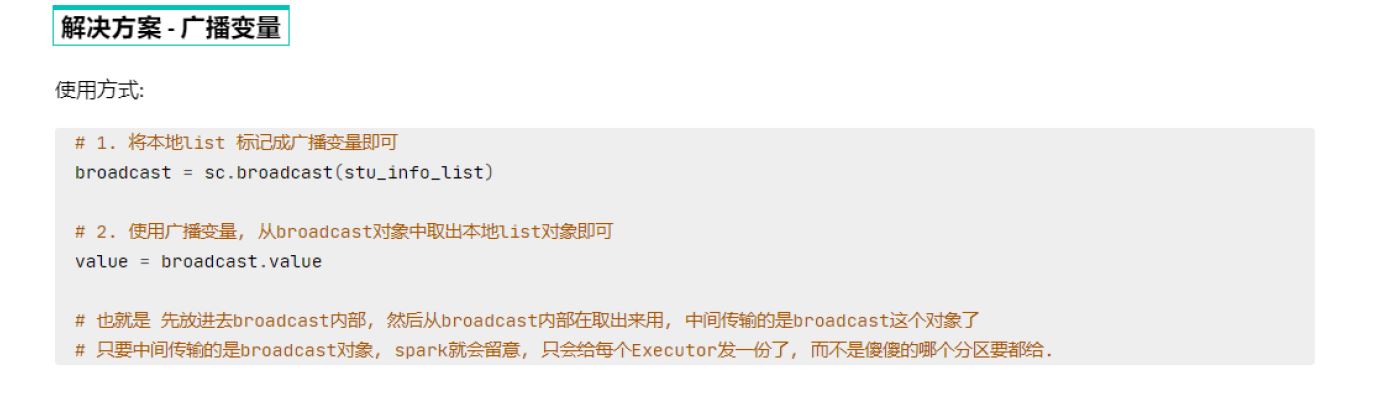
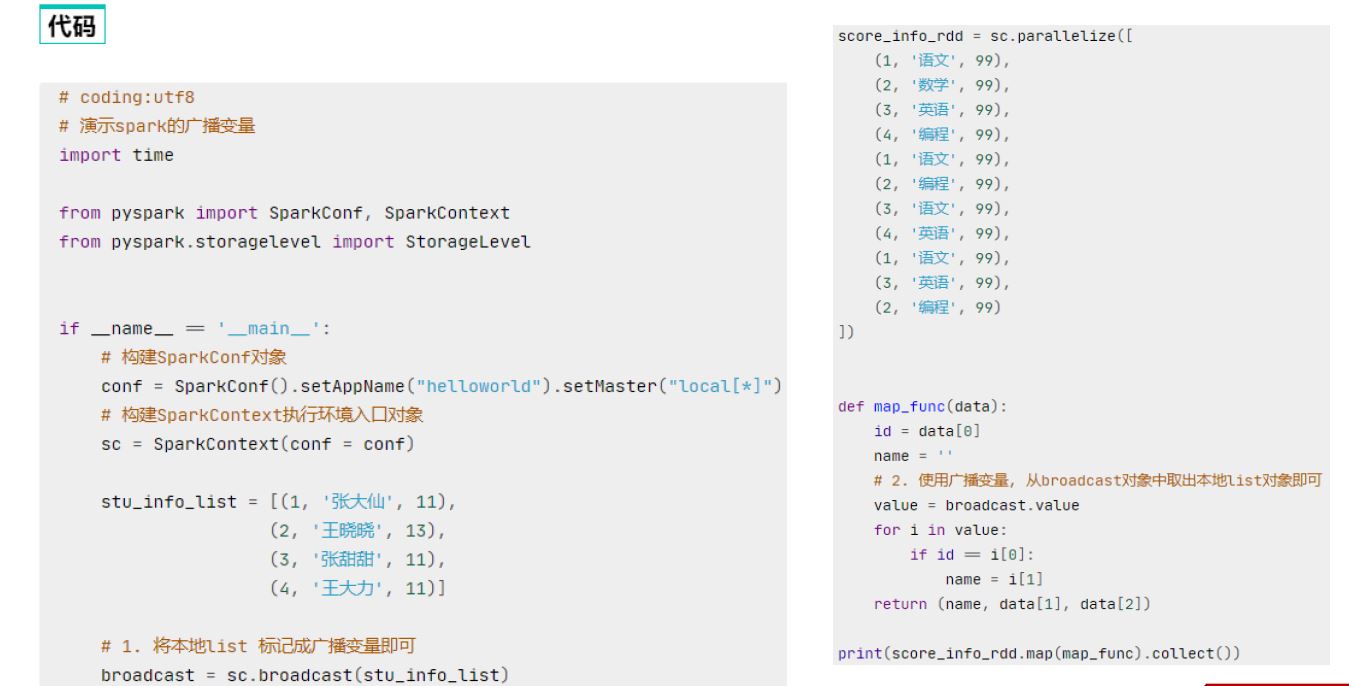
两种共享变量:广播变量(broadcast variable)与累加器(accumulator)
广播变量解决了什么问题?
分布式集合RDD和本地集合进行关联使用的时候, 降低内存占用以及减少网络IO传输, 提高性能.
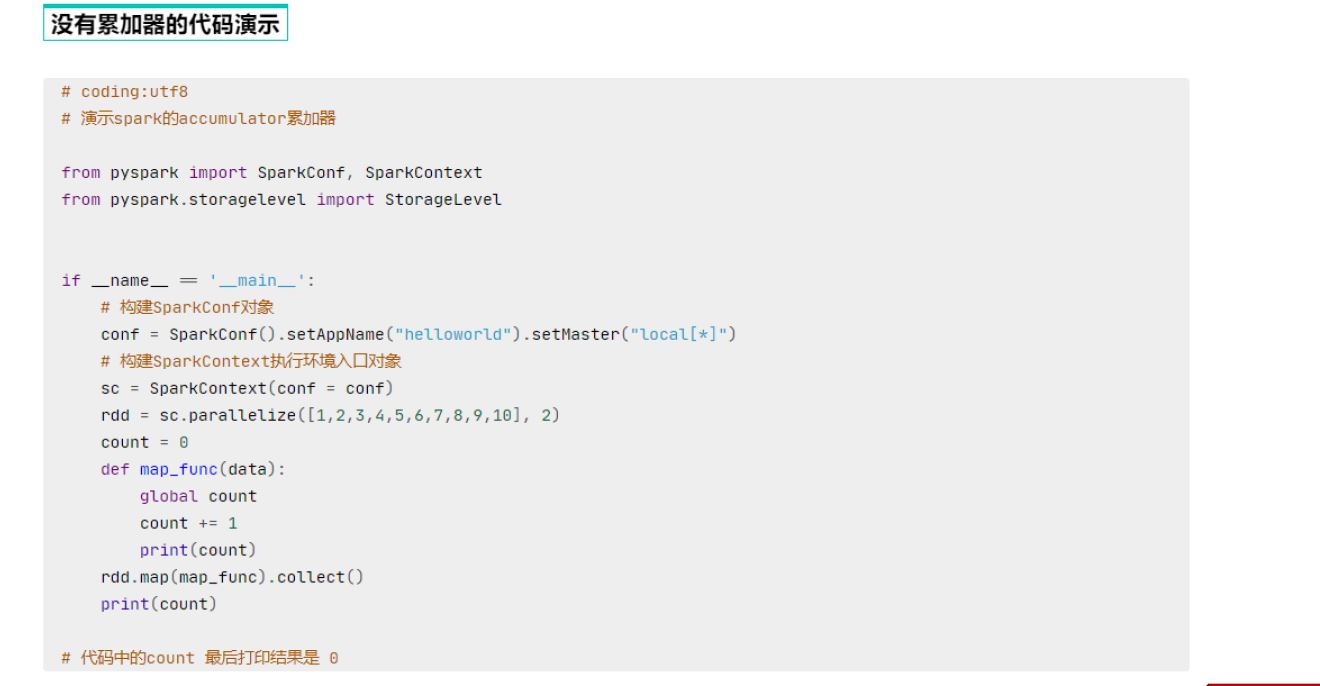
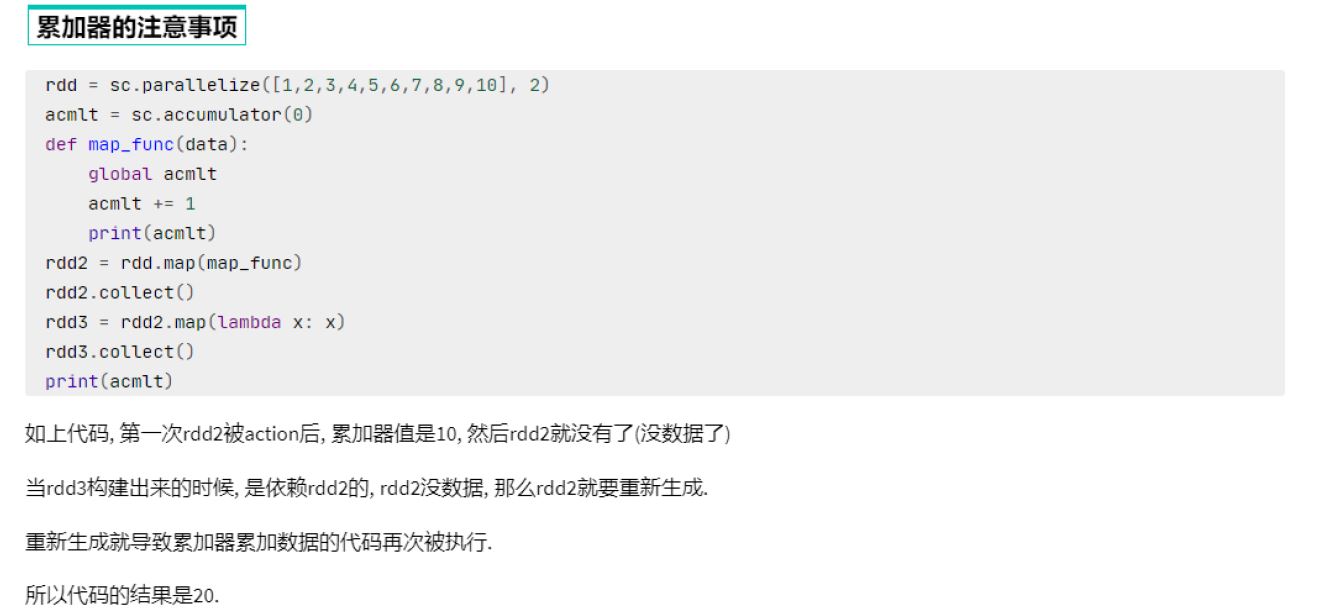
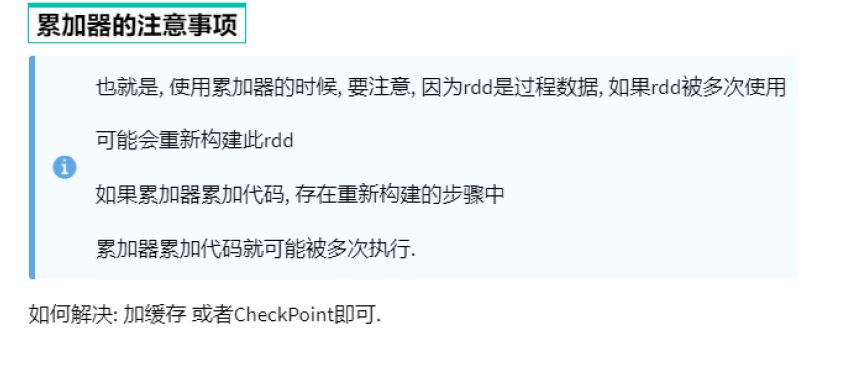
累加器解决了什么问题?
分布式代码执行中, 进行全局累加




1 | sc = spark.sparkContext |
1 | 55 |
累加器和reduce都可以得到聚合结果,效率???谁先执行 谁短,怎么衡量
https://blog.csdn.net/weixin_43810802/article/details/120772452
https://blog.csdn.net/zhuzuwei/article/details/104446388
https://blog.csdn.net/weixin_40161254/article/details/103472056
Use reduceByKey instead of groupByKey
groupByKey creates a lot of shuffling which hampers the performance, while reduceByKey does not shuffle the data as much
1 | in: |
聚合的作用
注意点就是 a,b 操作后的数据类型和a,b保持一致,举个例子 a+b 和a ,b类型一致,否则(a+b)+c会报错
1 collect
collect()
返回包含此RDD中的所有元素的列表
注意:因为所有数据都会加载到driver,所有只适用于数据量不大的情况
2 first
first()
返回RDD中的第一个元素
3 take
take(num)
取RDD的前num个元素
4 top
top(num, key=None)
排序
Get the top N elements from an RDD
5 foreach
foreach(f)
Applies a function to all elements of this RDD 分区输出
1 | def f(x): |
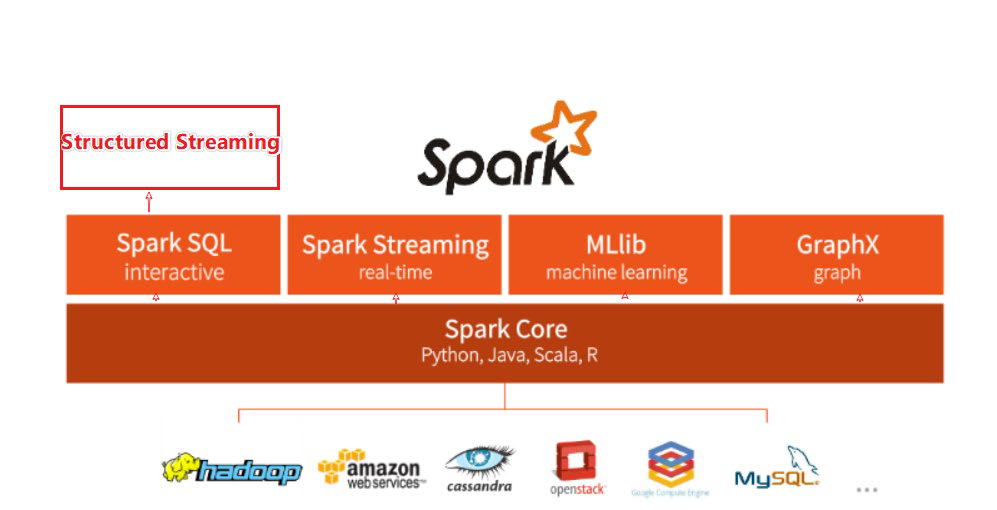
整个Spark 框架模块包含:Spark Core、Spark SQL、Spark Streaming、Spark GraphX、Spark MLlib,而后四项的能力都是建立在核心引擎之上
Spark Core:Spark的核心,Spark核心功能均由Spark Core模块提供,是Spark运行的基础。Spark Core以RDD为数据抽象,提供Python、Java、Scala、R语言的API,可以编程进行海量离线数据批处理计算。
SparkSQL:基于SparkCore之上,提供结构化数据的处理模块。SparkSQL支持以SQL语言对数据进行处理,SparkSQL本身针对离线计算场景。同时基于SparkSQL,Spark提供了StructuredStreaming模块,可以以SparkSQL为基础,进行数据的流式计算。
数据抽象:dataset(Java、Scala) dataframe(Java、Scala、Python、R)
SparkStreaming:以SparkCore为基础,提供数据的流式计算功能。
MLlib:以SparkCore为基础,进行机器学习计算,内置了大量的机器学习库和API算法等。方便用户以分布式计算的模式进行机器学习计算。
GraphX:以SparkCore为基础,进行图计算,提供了大量的图计算API,方便用于以分布式计算模式进行图计算。
https://blog.51cto.com/u_16213328/7866422
优先级

hadoop设置???
https://blog.csdn.net/weixin_43648241/article/details/108917865
SparkSession > SparkContext > HiveContext > SQLContext
SparkSession包含SparkContext
SparkContext包含HiveContext
HiveContext包含SQLContext
1 | SparkSession.builder.\ |
1 非实时 支持从 HDFS、HBase、Hive、ES、MongoDB、MySQL、PostgreSQL、AWS、Ali Cloud 等不同的存储系统、大数据库、关系型数据库中读入和写出数据
2 在实时流计算中可以从 Flume、Kafka 等多种数据源获取数据并执行流式计算。
https://spark.apache.org/docs/latest/submitting-applications.html
The spark-submit script in Spark’s bin directory is used to launch applications on a cluster. It can use all of Spark’s supported cluster managers through a uniform interface so you don’t have to configure your application especially for each one.
1 | ./bin/spark-submit \ |
--class: The entry point for your application (e.g. org.apache.spark.examples.SparkPi)--master: The master URL for the cluster (e.g. spark://23.195.26.187:7077)--deploy-mode: Whether to deploy your driver on the worker nodes (cluster) or locally as an external client (client) (default: client) †--conf: Arbitrary Spark configuration property in key=value format. For values that contain spaces wrap “key=value” in quotes (as shown). Multiple configurations should be passed as separate arguments. (e.g. --conf = --conf =)application-jar: Path to a bundled jar including your application and all dependencies. The URL must be globally visible inside of your cluster, for instance, an hdfs:// path or a file:// path that is present on all nodes.application-arguments: Arguments passed to the main method of your main class, if any当前为客户端,driver在哪取决于deploy mode
应该只能local和client
此时若是代码指定cluster会报错
1 | config("spark.submit.deployMode", "cluster") |
Exception in thread “main” org.apache.spark.SparkException: Cluster deploy mode is not applicable to Spark shells.
应该只能local和clien