sparkcore底层的数据结构是rdd
运行流程

1 注册并申请资源,分配资源
2 job->stage->task
3 4 5 driver executor 交互执行任务
executor 向driver申请任务, 还是driver给executor 分配任务?
例子
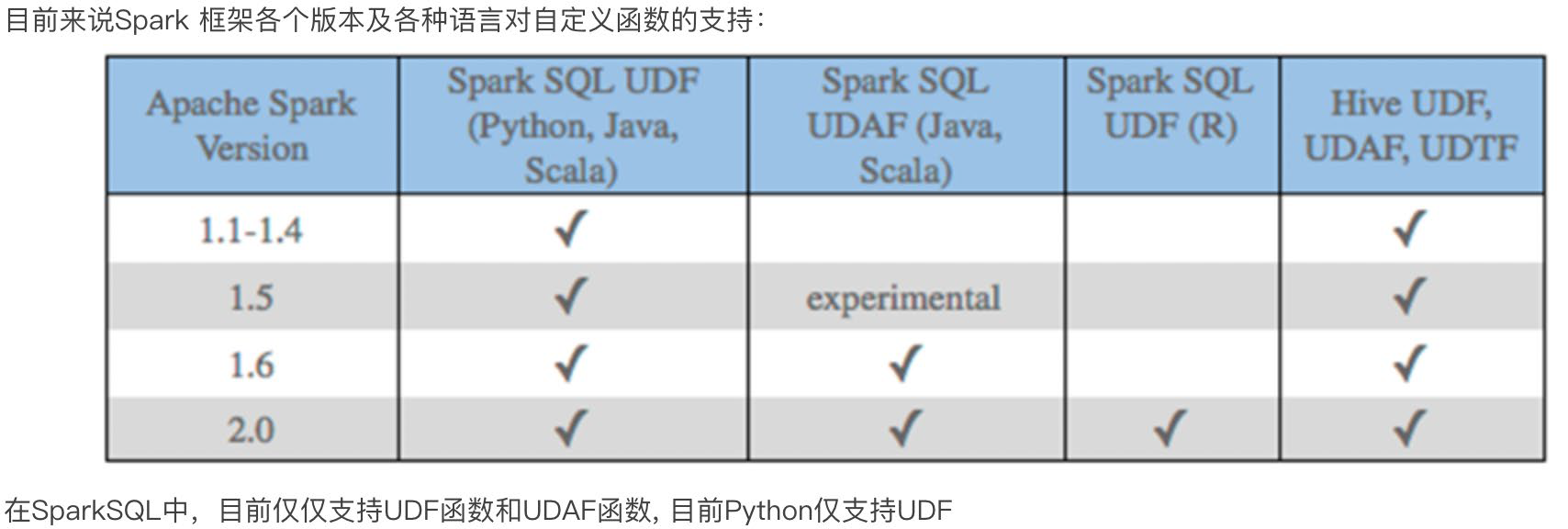
DataFrame支持两种风格进行编程,分别是:
DSL称之为:领域特定语言。
其实就是指DataFrame的特有API
DSL风格意思就是以调用API的方式来处理Data
比如:df.where().limit()
SQL语法风格
SQL风格就是使用SQL语句处理DataFrame的数据
比如:spark.sql(“SELECT * FROM xxx)

步骤:
https://blog.csdn.net/qq_43665254/article/details/112379113
https://blog.csdn.net/sunflower_sara/article/details/104044412
1、定义函数
2、注册函数
3、使用函数
1 | from pyspark.sql.functions import col, lit |
算子就是分布式集合对象的api
rdd算子分为两类:1.transformation 2.action
https://blog.csdn.net/weixin_45271668/article/details/106441457
https://blog.csdn.net/Android_xue/article/details/79780463
https://chowdera.com/2022/02/202202091419262471.html
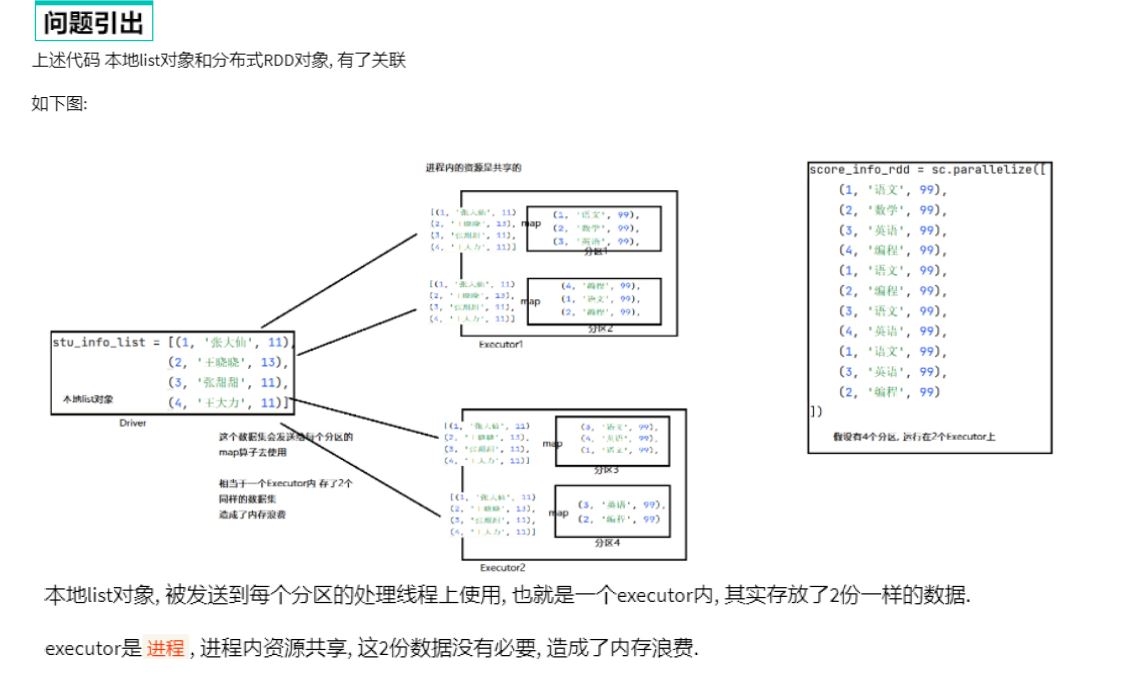
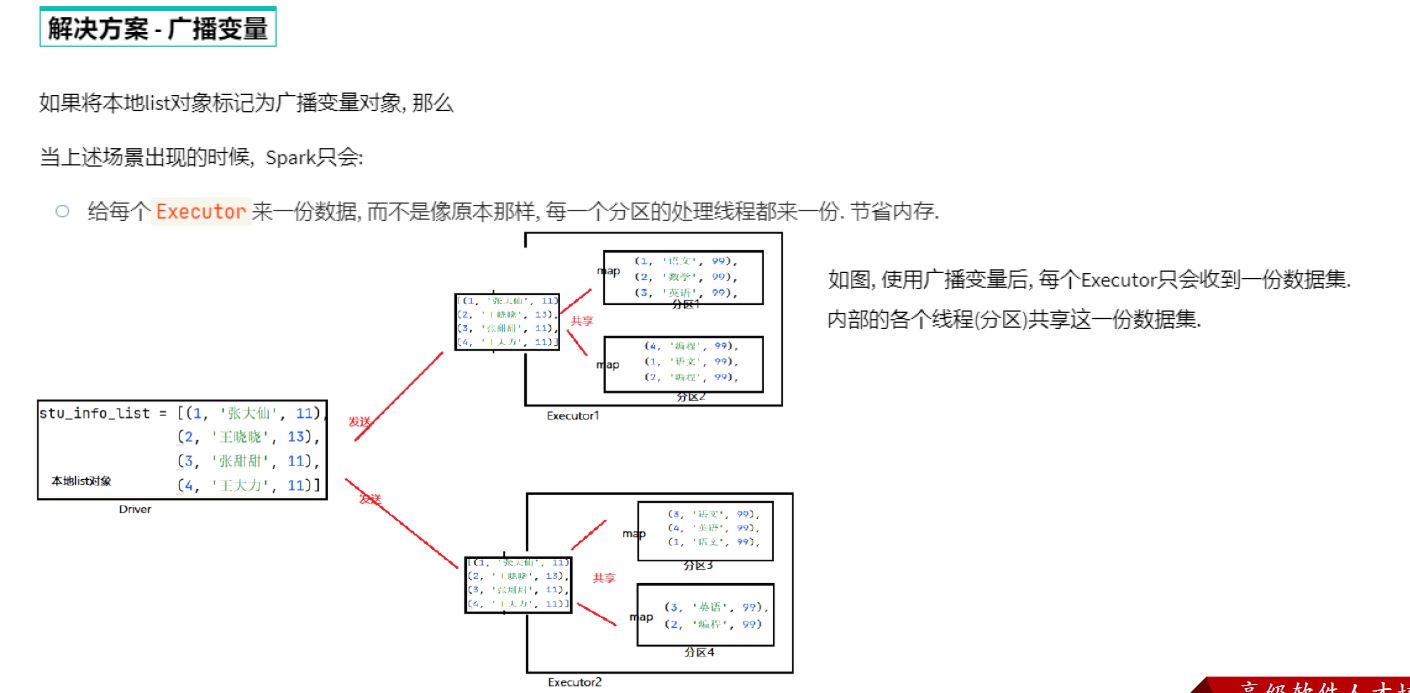
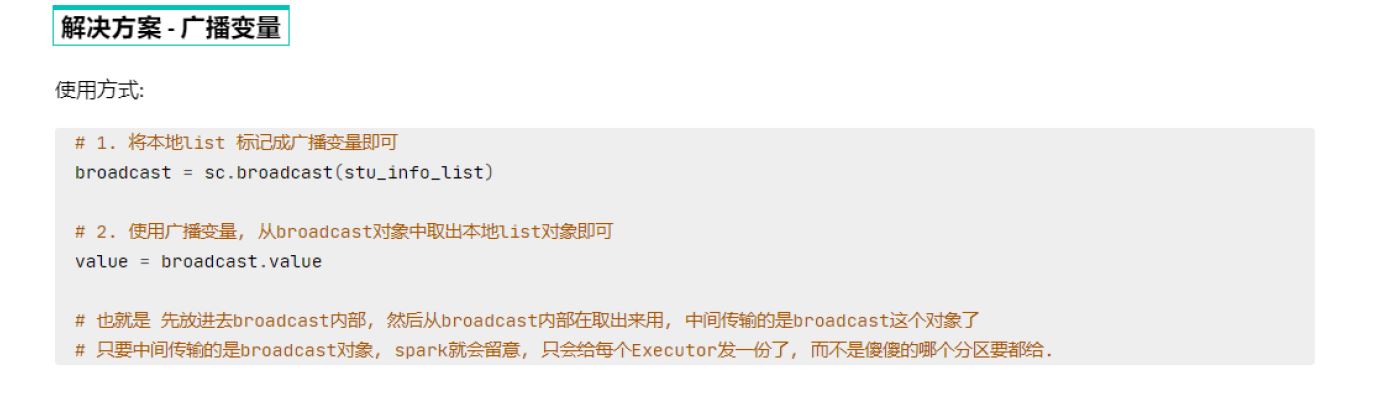
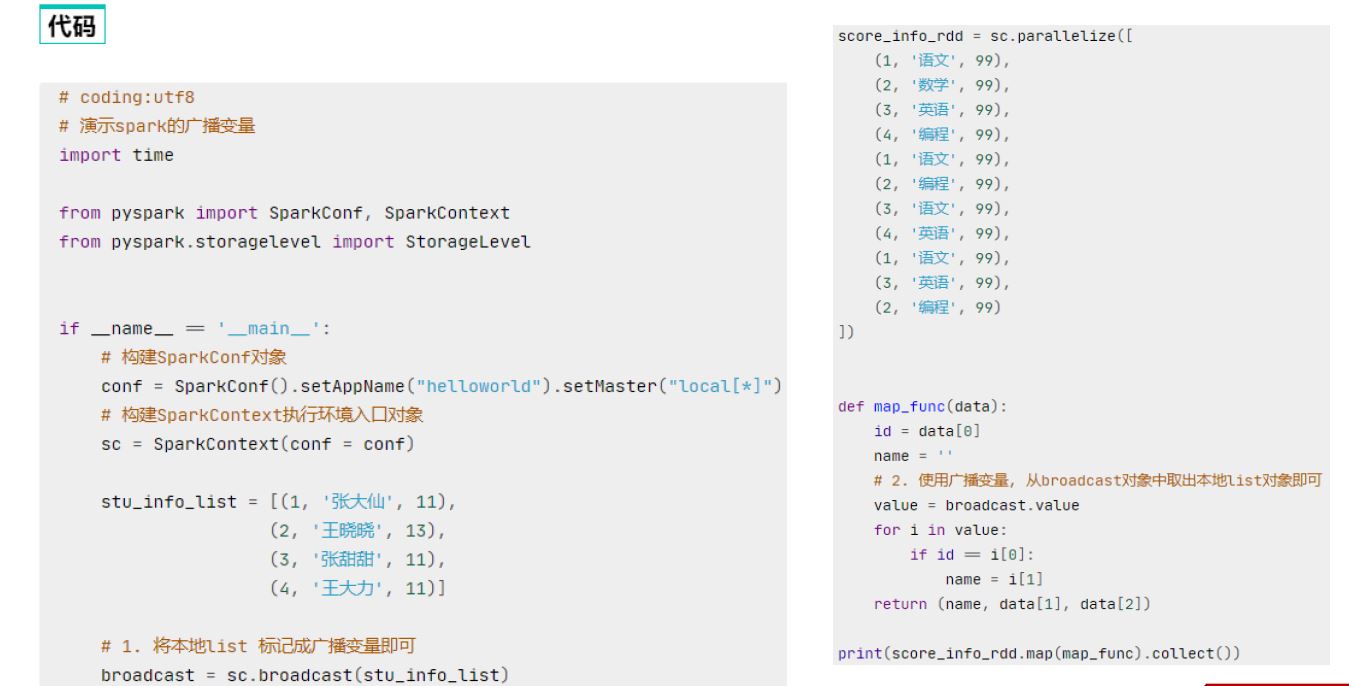
两种共享变量:广播变量(broadcast variable)与累加器(accumulator)
广播变量解决了什么问题?
分布式集合RDD和本地集合进行关联使用的时候, 降低内存占用以及减少网络IO传输, 提高性能.
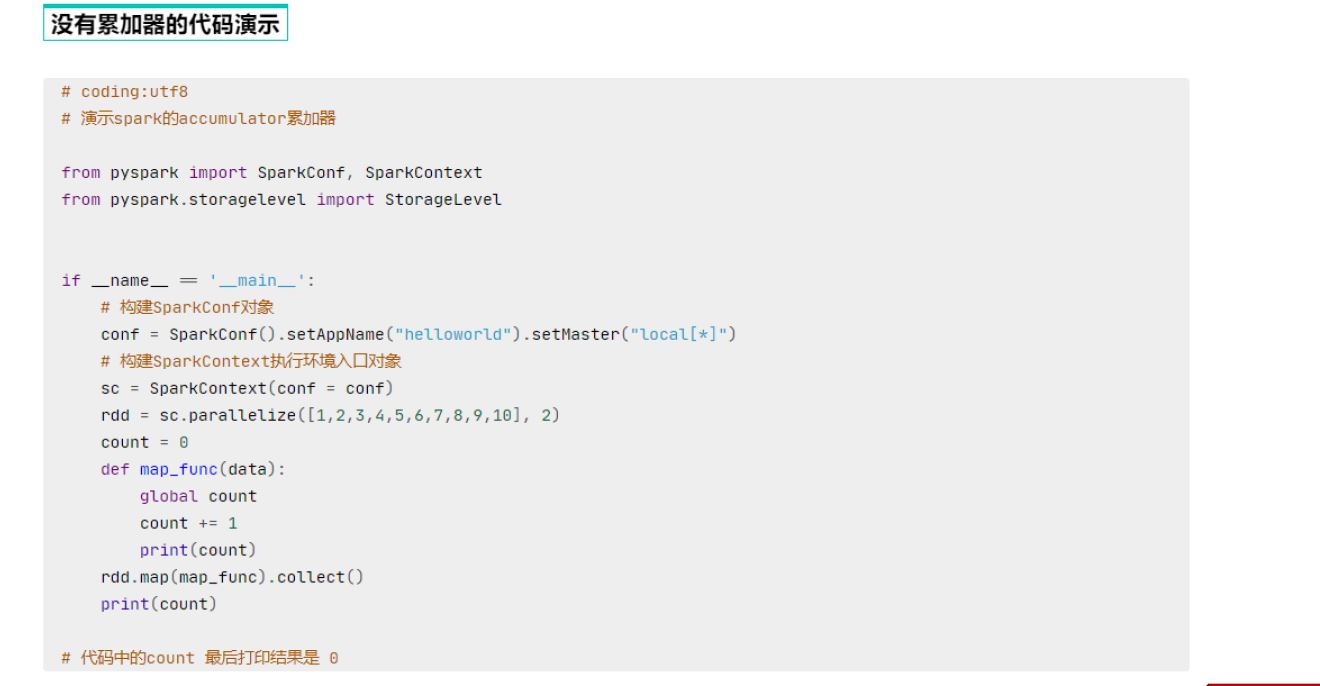
累加器解决了什么问题?
分布式代码执行中, 进行全局累加




1 | sc = spark.sparkContext |
1 | 55 |
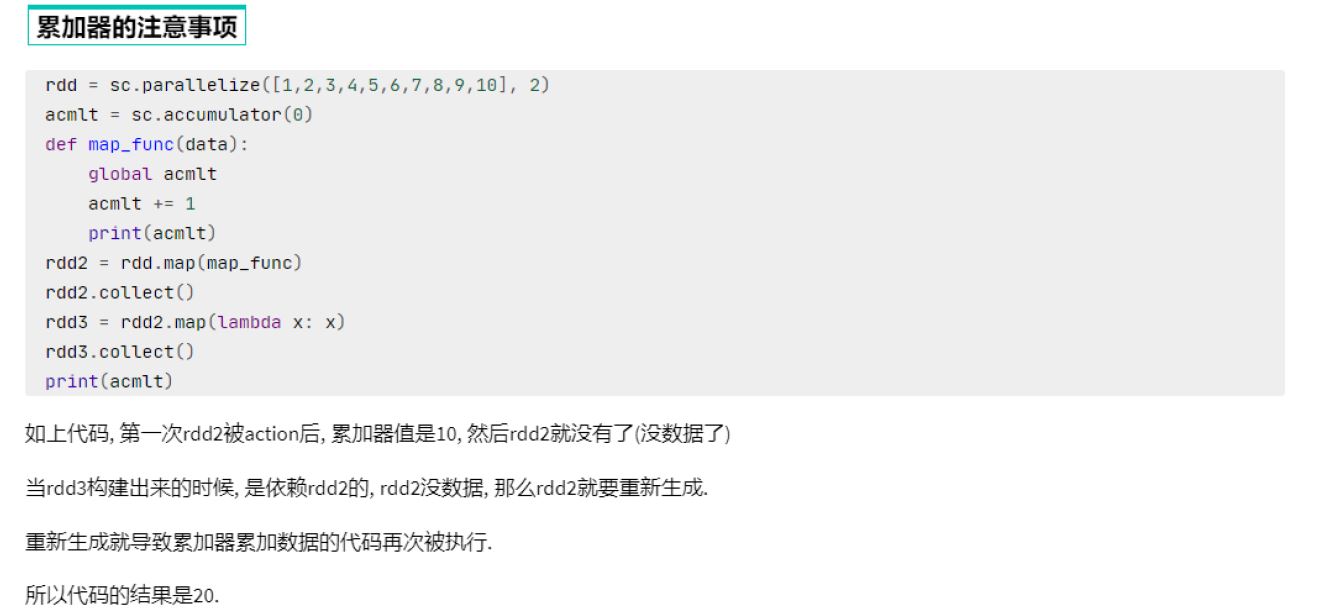
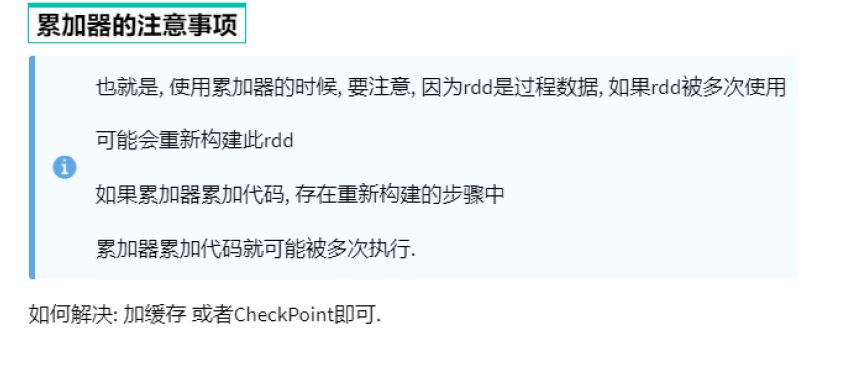
累加器和reduce都可以得到聚合结果,效率???谁先执行 谁短,怎么衡量
https://blog.csdn.net/weixin_43810802/article/details/120772452
https://blog.csdn.net/zhuzuwei/article/details/104446388
https://blog.csdn.net/weixin_40161254/article/details/103472056
Use reduceByKey instead of groupByKey
groupByKey creates a lot of shuffling which hampers the performance, while reduceByKey does not shuffle the data as much
1 | in: |
聚合的作用
注意点就是 a,b 操作后的数据类型和a,b保持一致,举个例子 a+b 和a ,b类型一致,否则(a+b)+c会报错
1 collect
collect()
返回包含此RDD中的所有元素的列表
注意:因为所有数据都会加载到driver,所有只适用于数据量不大的情况
2 first
first()
返回RDD中的第一个元素
3 take
take(num)
取RDD的前num个元素
4 top
top(num, key=None)
排序
Get the top N elements from an RDD
5 foreach
foreach(f)
Applies a function to all elements of this RDD 分区输出
1 | def f(x): |
Hive和Spark 均是“分布式SQL计算引擎”,mysql等不是,mysql跑单机上
均是构建大规模结构化数据计算的绝佳利器,同时SparkSQL拥有更好的性能。目前,企业中使用Hive仍旧居多,但SparkSQL将会在很近的未来替代Hive成为分布式SQL计算市场的顶级
https://www.jianshu.com/p/3aa52ee3a802
https://blog.csdn.net/hjw199089/article/details/77938688
https://blog.csdn.net/mys_35088/article/details/80864092
https://blog.csdn.net/dmy1115143060/article/details/82620715
https://blog.csdn.net/xxd1992/article/details/85254666
https://blog.csdn.net/m0_46657040/article/details/108737350
https://blog.csdn.net/heiren_a/article/details/111954523
https://blog.csdn.net/u011564172/article/details/53611109
https://blog.csdn.net/qq_22473611/article/details/107822168
https://www.jianshu.com/p/3aa52ee3a802
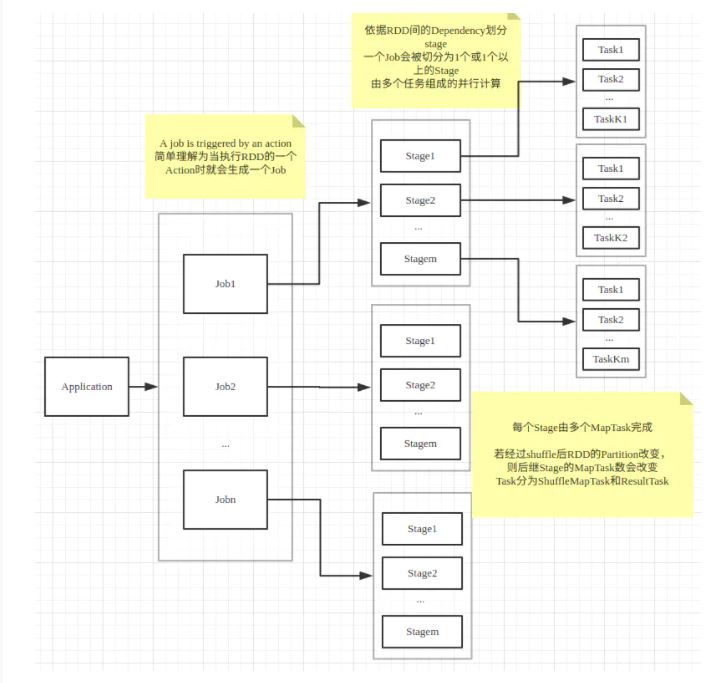
任务
一个action 一个job
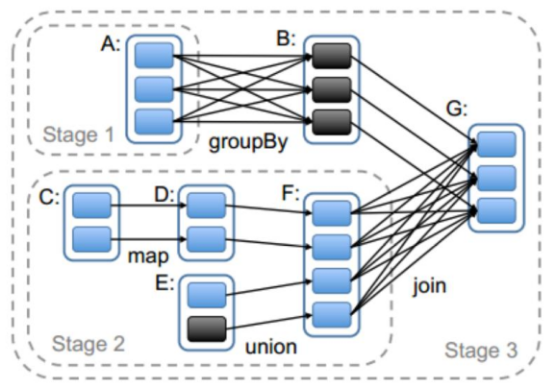
一个job根据rdd的依赖关系构建dag,根据dag划分stage,一个job包含一个或者多个stage
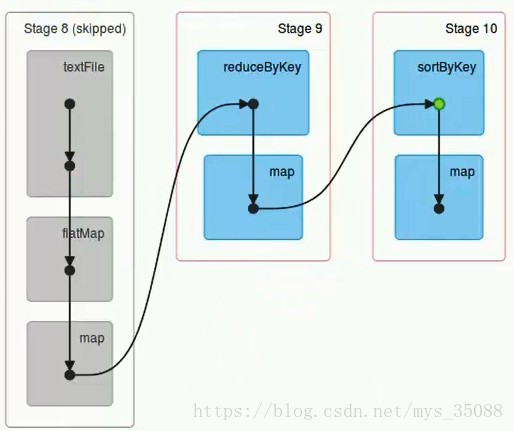
stage根据rdd的分区数决定task数量
一个task 对应很多record,也就是多少行数据
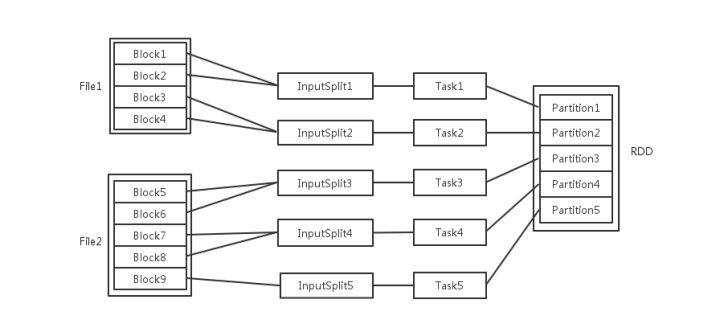
这里应该是 rdd的分区数决定task数量,task数量决定inputsplit数量,然后决定block的组合
https://juejin.cn/post/6844903848536965134
为什么分区?
分区的主要作用是用来实现并行计算,提高效率
分区方式
Spark包含两种数据分区方式:HashPartitioner(哈希分区)和RangePartitioner(范围分区)
分区数设置
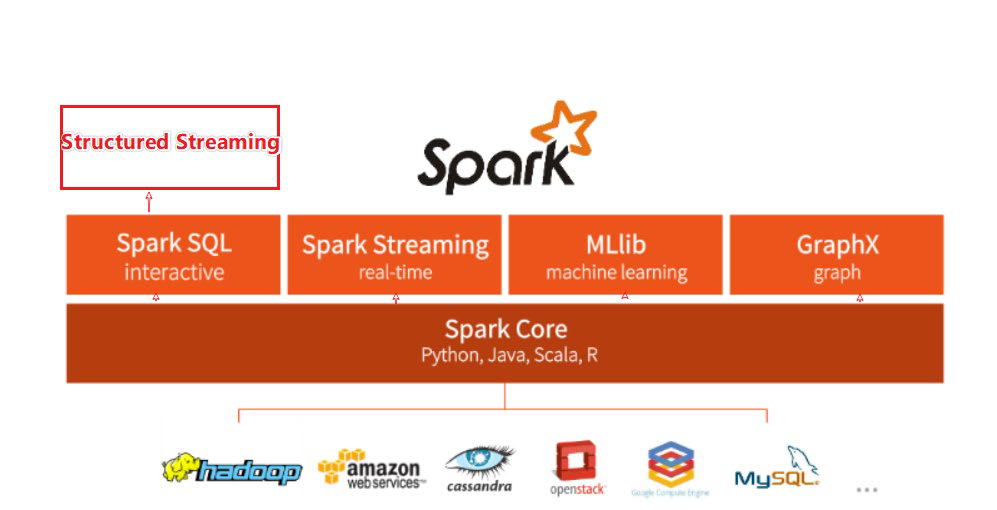
整个Spark 框架模块包含:Spark Core、Spark SQL、Spark Streaming、Spark GraphX、Spark MLlib,而后四项的能力都是建立在核心引擎之上
Spark Core:Spark的核心,Spark核心功能均由Spark Core模块提供,是Spark运行的基础。Spark Core以RDD为数据抽象,提供Python、Java、Scala、R语言的API,可以编程进行海量离线数据批处理计算。
SparkSQL:基于SparkCore之上,提供结构化数据的处理模块。SparkSQL支持以SQL语言对数据进行处理,SparkSQL本身针对离线计算场景。同时基于SparkSQL,Spark提供了StructuredStreaming模块,可以以SparkSQL为基础,进行数据的流式计算。
数据抽象:dataset(Java、Scala) dataframe(Java、Scala、Python、R)
SparkStreaming:以SparkCore为基础,提供数据的流式计算功能。
MLlib:以SparkCore为基础,进行机器学习计算,内置了大量的机器学习库和API算法等。方便用户以分布式计算的模式进行机器学习计算。
GraphX:以SparkCore为基础,进行图计算,提供了大量的图计算API,方便用于以分布式计算模式进行图计算。
https://www.educba.com/mapreduce-vs-spark/
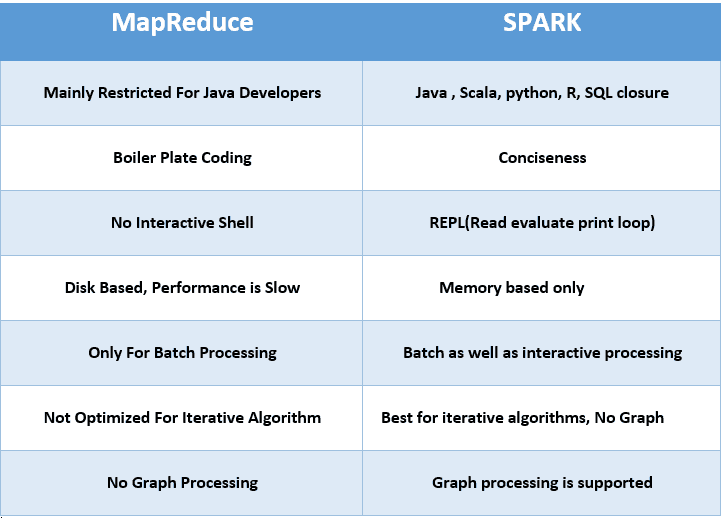
| MapReduce | Spark | |
|---|---|---|
| Product’s Category | From the introduction, we understood that MapReduce enables the processing of data and hence is majorly a data processing engine. | Spark, on the other hand, is a framework that drives complete analytical solutions or applications and hence making it an obvious choice for data scientists to use this as a data analytics engine. |
| Framework’s Performance and Data Processing | In the case of MapReduce, reading and writing operations are performed from and to a disk thus leading to slowness in the processing speed. | In Spark, the number of read/write cycles is minimized along with storing data in memory allowing it to be 10 times faster. But spark may suffer a major degradation if data doesn’t fit in memory. |
| Latency | As a result of lesser performance than Spark, MapReduce has a higher latency in computing. | Since Spark is faster, it enables developers with low latency computing. |
| Manageability of framework | MapReduce being only a batch engine, other components must be handled separately yet synchronously thus making it difficult to manage. | Spark is a complete data analytics engine, has the capability to perform batch, interactive streaming, and similar component all under the same cluster umbrella and thus easier to manage! |
| Real-time Analysis | MapReduce was built mainly for batch processing and hence fails when used for real-time analytics use cases. | Data coming from real-time live streams like Facebook, Twitter, etc. can be efficiently managed and processed in Spark. |
| Interactive Mode | MapReduce doesn’t provide the gamut of having interactive mode. | In spark it is possible to process the data interactively |
| Security | MapReduce has accessibility to all features of Hadoop security and as a result of this, it is can be easily integrated with other projects of Hadoop Security. MapReduce also supports ASLs. | In Spark, the security is by default set to OFF which might lead to a major security fallback. In the case of authentication, only the shared secret password method is possible in Spark. |
| Tolerance to Failure | In case of crash of MapReduce process, the process is capable of starting from the place where it was left off earlier as it relies on Hard Drives rather than RAMs | In case of crash of Spark process, the processing should start from the beginning and hence becomes less fault-tolerant than MapReduce as it relies of RAM usage. |
https://blog.csdn.net/JENREY/article/details/84873874
1 spark基于内存 ,mapreduce基于磁盘
指的是中间结果
MapReduce:通常需要将计算的中间结果写入磁盘,然后还要读取磁盘,从而导致了频繁的磁盘IO
Spark:不需要每次将计算的中间结果写入磁盘
2 spark粗粒度资源申请,MapReduce细粒度资源申请
spark 执行task不需要自己申请资源,提交任务的时候统一申请了
MapReduce 执行task任务的时候,task自己申请
3 spark基于多线程,mapreduce基于多进程
https://blog.51cto.com/u_16213328/7866422
优先级

hadoop设置???
https://blog.csdn.net/weixin_43648241/article/details/108917865
SparkSession > SparkContext > HiveContext > SQLContext
SparkSession包含SparkContext
SparkContext包含HiveContext
HiveContext包含SQLContext
1 | SparkSession.builder.\ |
1 非实时 支持从 HDFS、HBase、Hive、ES、MongoDB、MySQL、PostgreSQL、AWS、Ali Cloud 等不同的存储系统、大数据库、关系型数据库中读入和写出数据
2 在实时流计算中可以从 Flume、Kafka 等多种数据源获取数据并执行流式计算。