sugar
百度的BI可视化工具
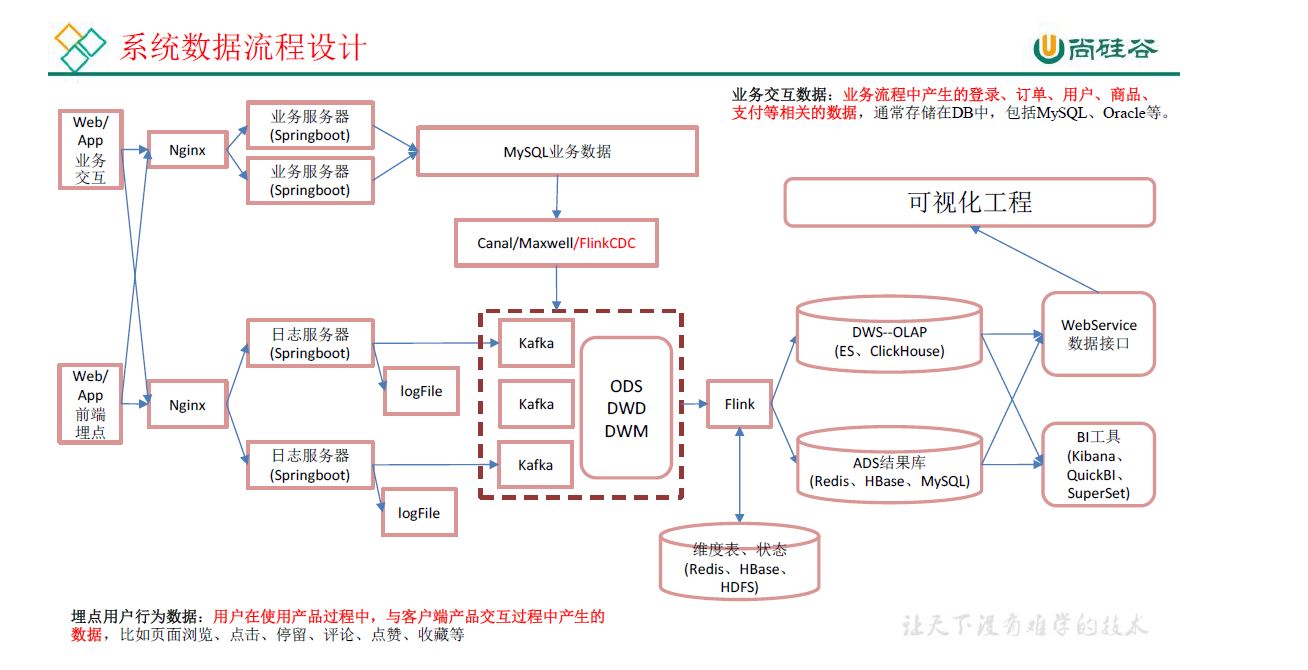
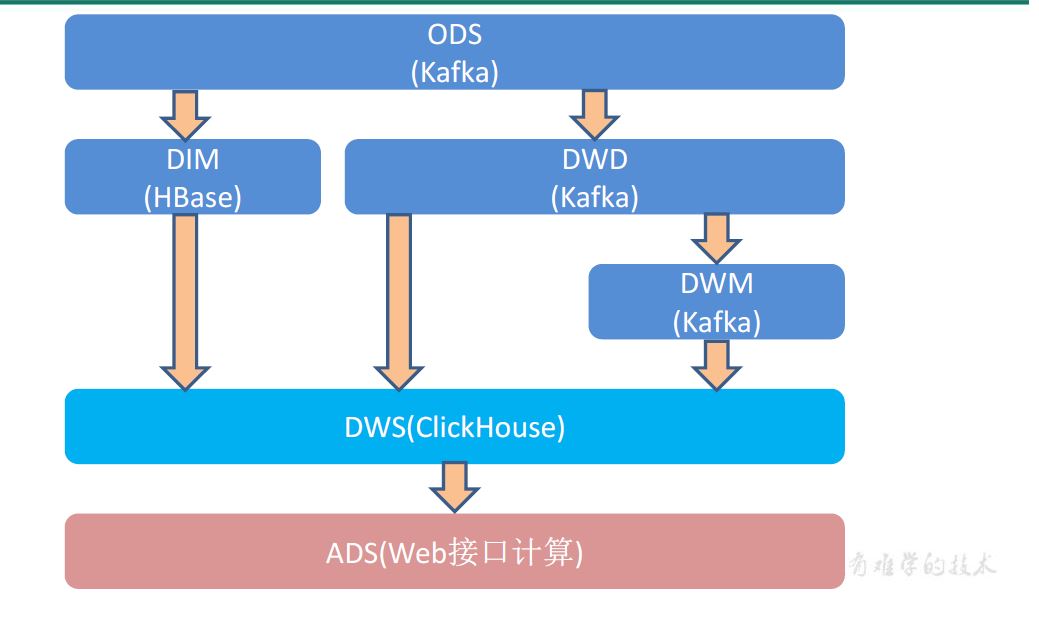
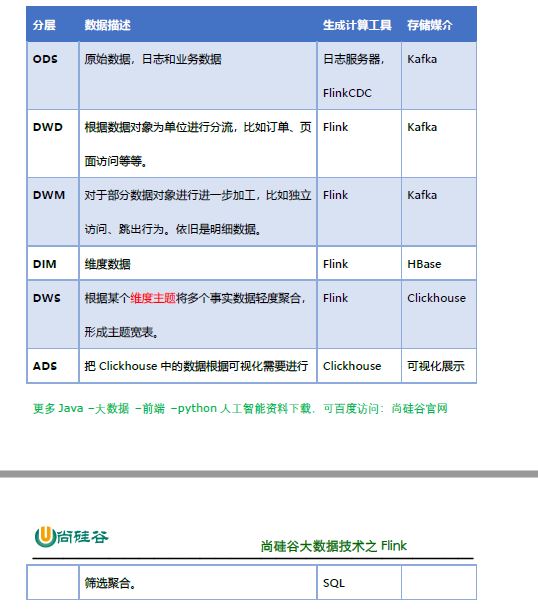
1 日志数据
前端(jar,产生日志数据)-》Nginx(集群间负载均衡)-》日志服务器(springboot,采集数据,jar)-》log,ods(kafka)
本地测试,本地起应用 -》 单机部署,单服务器起应用 -》 集群部署,集群起应用
2 业务数据
前端,jar,产生业务数据-》mysql,配置什么同步-》flinkcdc-》ods(kafka)
1 用户行为日志
ods(Kafka)-> flink -> dwd(kafka)
1 识别新老用户
业务需要
2 日志数据拆分
这3类日志,结构不同,写回Kafka不同主题
2 业务数据
ods(kafka) -> flink -> 1 维度数据,dim(HBASE) 2 事实数据 dwd(kafka)
1 ETL
过滤控制
2 动态分流
维度数据到hbase 事实数据到kafka
怎么分流?
ods的表里面哪些是维度表,哪些是事实表,需要提前知道表的分类信息,后面才可以分流。业务库的表会变化,表的分类信息实时更新,需要动态同步。这里将表的分类信息存在mysql,利用广播流发送。
dmd(kafka)-> flink -> dwm(kafka)
1 访问uv计算
UV,unique visitor
2 跳出明细计算
跳出率=跳出次数 / 访问次数
3 订单主题表
4 支付主题表
dwm(kafka)-> flink -> dws(clickhouse)
1 访客主题宽表
2 商品主题宽表
3 地区主题表
4 关键词主题表
https://blog.csdn.net/jianghuaijie/article/details/122009653
作用
DWM层的定位是什么,DWM层主要服务DWS,因为部分需求直接从DWD层到DWS层中间会有一定的计算量,而且这部分计算的结果很有可能被多个DWS层主题复用
构建
分主题
实时数仓没有dwt,因为dwt是累计统计,实时系统不适用
作用
轻度聚合,生成一系列的中间表,提升公共指标的复用性,减少重复加工
分主题,便于管理
构建
分主题
宽表
轻度聚合
https://blog.csdn.net/wzy0623/article/details/49797421
https://www.google.com/search?q=Degenerate+Dimension&sourceid=chrome&ie=UTF-8
https://www.jamesserra.com/archive/2011/11/degenerate-dimensions/
https://blog.csdn.net/yezonghui/article/details/120131320
当一个维度没有数据仓库需要的任何数据的时候就可以退化此维度,需要把退化的相关数据迁移到事实表中,然后删除退化的维度。
https://blog.csdn.net/qq_22473611/article/details/116702667
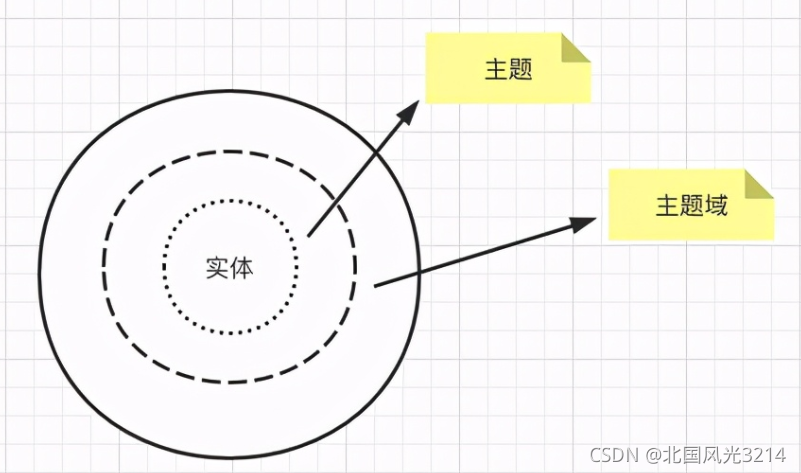
主题域下面可以有多个主题,主题还可以划分成更多的子主题,主题和主题之间的建设可能会有交叉现象,而实体则是不可划分的最小单位
1 按照业务系统划分
2 按照业务过程划分
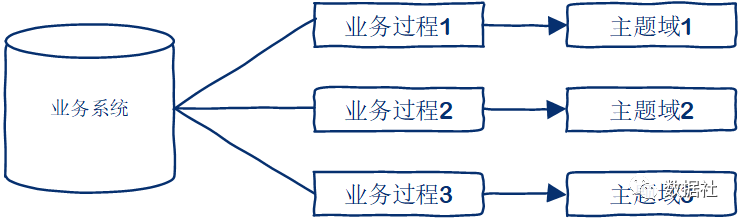
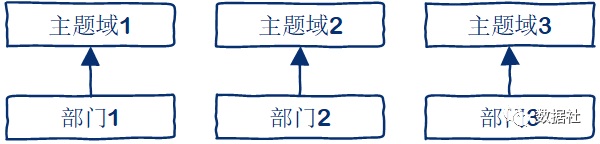
3 按照部门划分
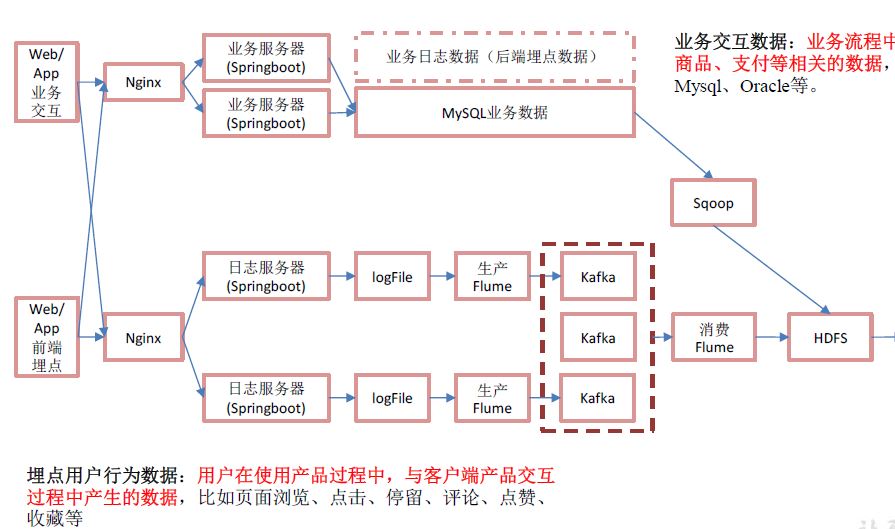
jar-》log-》flume-》kafka-》flume-》hdfs
用户行为数据存储在日志服务器,以.log文件存在,log-》flume-》kafka-》flume-》hdfs
jar-》mysql-》sqoop-》hdfs
业务数据存储在mysql,使用sqoop导入hdfs
前端-》Nginx-》日志服务器-》)log,Kafka(ods
1 前端埋点数据
通过jar包模拟
2 Nginx
https://blog.csdn.net/qq_40036754/article/details/102463099
负载均衡
3 日志服务器
spring boot搭建
首先,Spring 就是一个java框架,spring boot在 Spring 的基础上演进
4 落盘,整合 Kafka
落盘指的是存在日志服务器
生产者-》kafka-》消费者
生产 消费
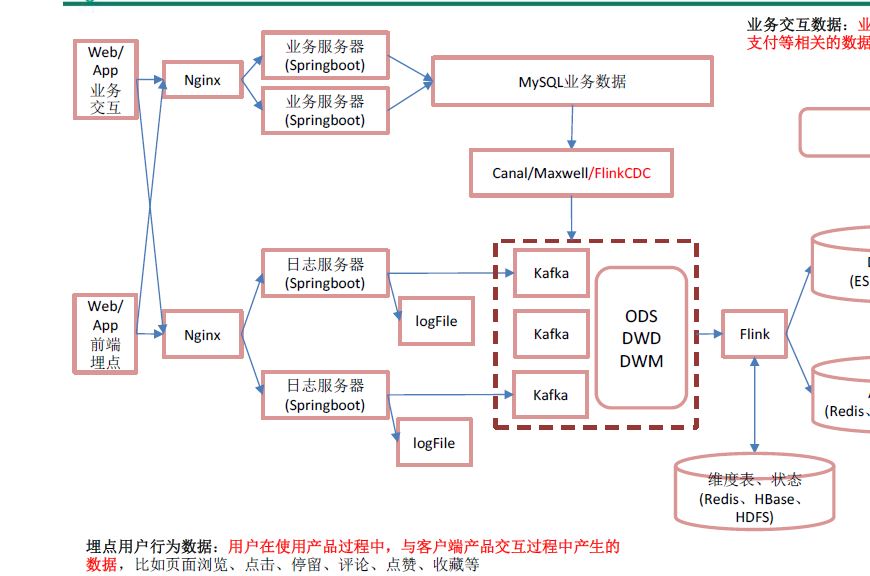
jar-》mysql-》flinkcdc-》kafka(ods)
不能使用sqoop,因为sqoop底层为mapreduce,太慢了,改用canal,maxwell或者flinkcdc
数据从mysql读到kafka,不是hdfs
flink-cdc
https://cloud.tencent.com/developer/article/1801766
Change Data Capture(变更数据获取)
https://www.cnblogs.com/yjd_hycf_space/p/7772722.html
https://blog.csdn.net/qq_33269009/article/details/90522087
https://blog.csdn.net/Stubborn_Cow/article/details/48420997
注意:很多人理解的ETL是在经过前两个部分之后,加载到数据仓库的数据库中就完事了。ETL不仅仅是在源数据—>ODS这一步,ODS—>DW, DW—>DM包含更为重要和复杂的ETL过程。