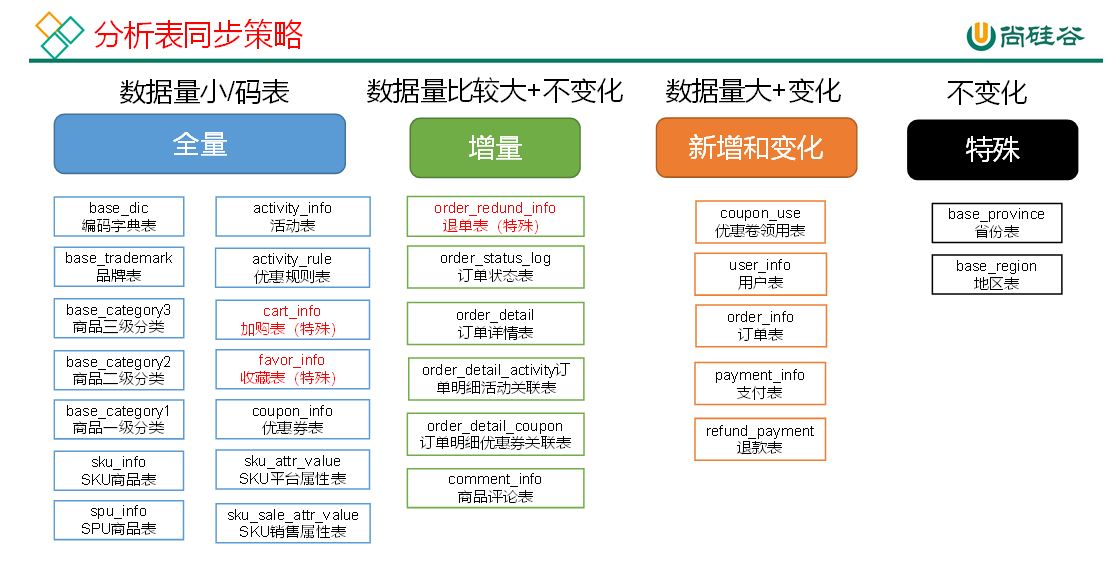
1 离线
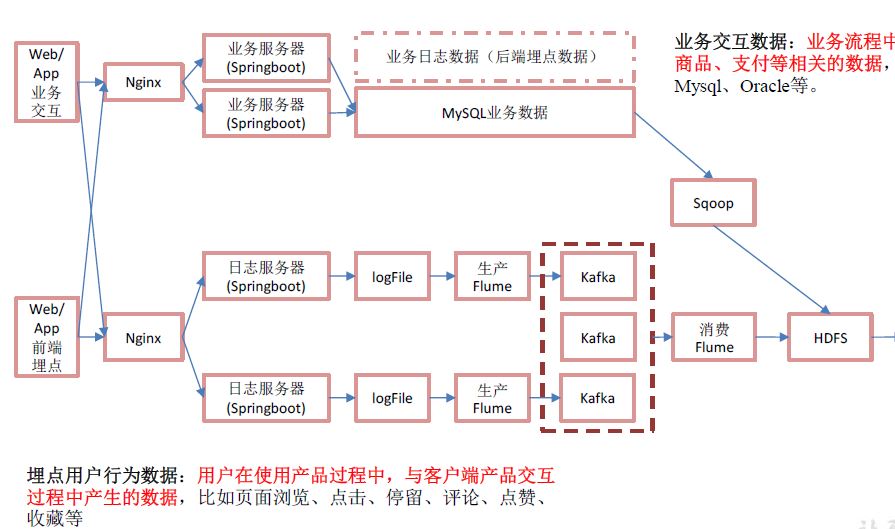
1.用户行为数据
jar-》log-》flume-》kafka-》flume-》hdfs
用户行为数据存储在日志服务器,以.log文件存在,log-》flume-》kafka-》flume-》hdfs
2 业务数据
jar-》mysql-》sqoop-》hdfs
业务数据存储在mysql,使用sqoop导入hdfs
2 实时
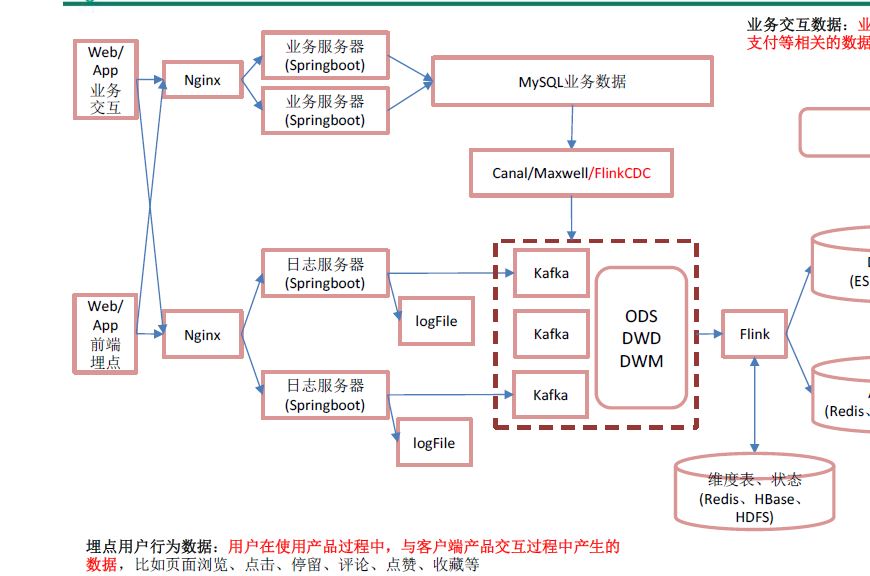
1.用户行为数据
前端-》Nginx-》日志服务器-》)log,Kafka(ods
1 前端埋点数据
通过jar包模拟
2 Nginx
https://blog.csdn.net/qq_40036754/article/details/102463099
负载均衡
3 日志服务器
spring boot搭建
首先,Spring 就是一个java框架,spring boot在 Spring 的基础上演进
4 落盘,整合 Kafka
落盘指的是存在日志服务器
生产者-》kafka-》消费者
生产 消费
2 业务数据
jar-》mysql-》flinkcdc-》kafka(ods)
不能使用sqoop,因为sqoop底层为mapreduce,太慢了,改用canal,maxwell或者flinkcdc
数据从mysql读到kafka,不是hdfs
flink-cdc
https://cloud.tencent.com/developer/article/1801766
Change Data Capture(变更数据获取)