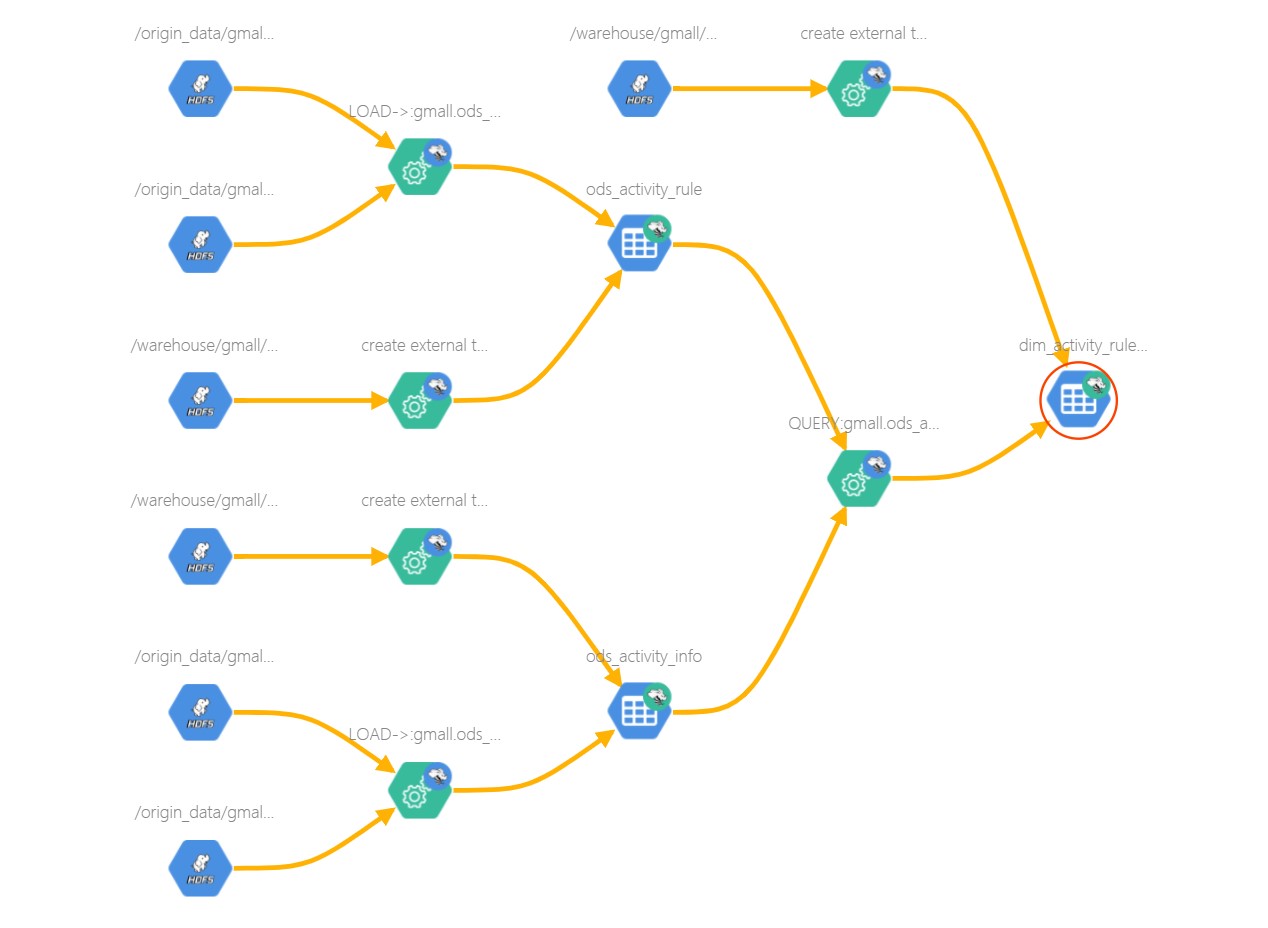
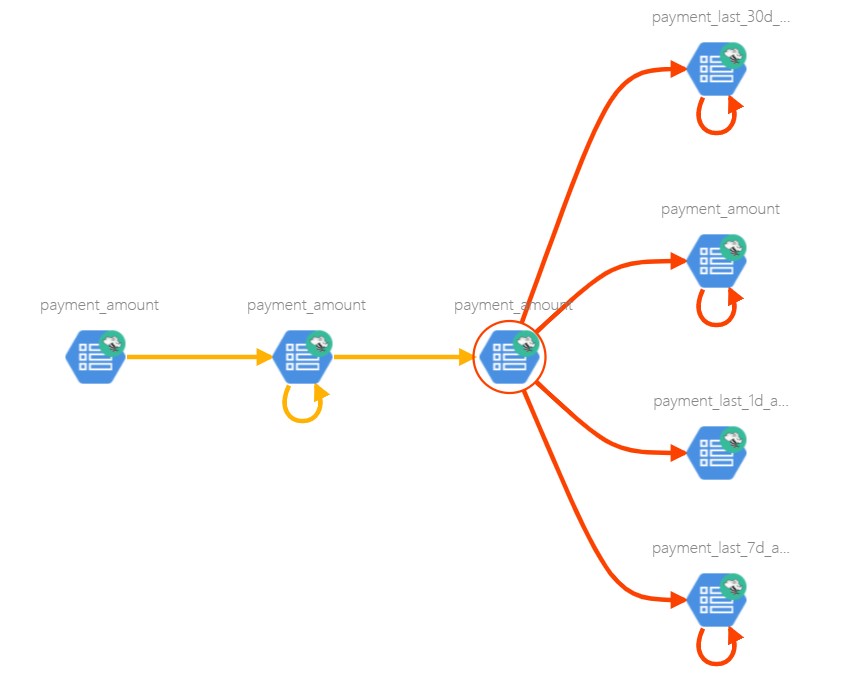
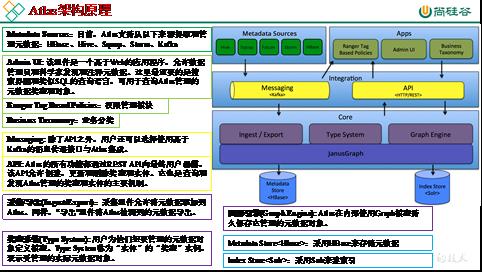
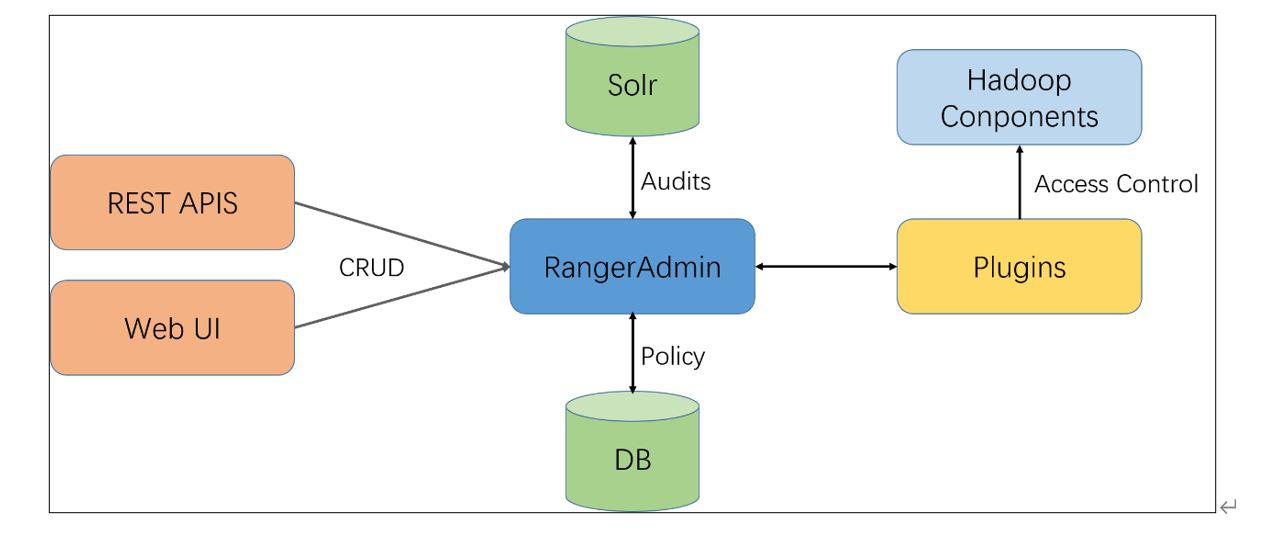
Metadata is simply data about data. It means it is a description and context of the data. It helps to organize, find and understand data. Here are a few real world examples of metadata:
This document describes how to configure authentication for Hadoop in secure mode.
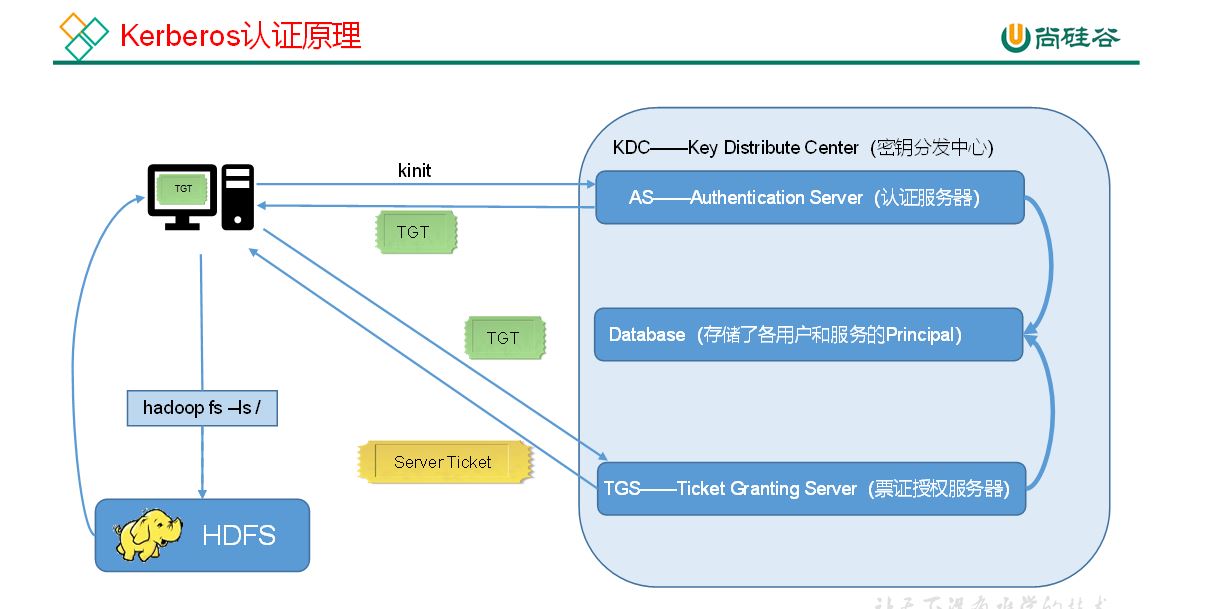
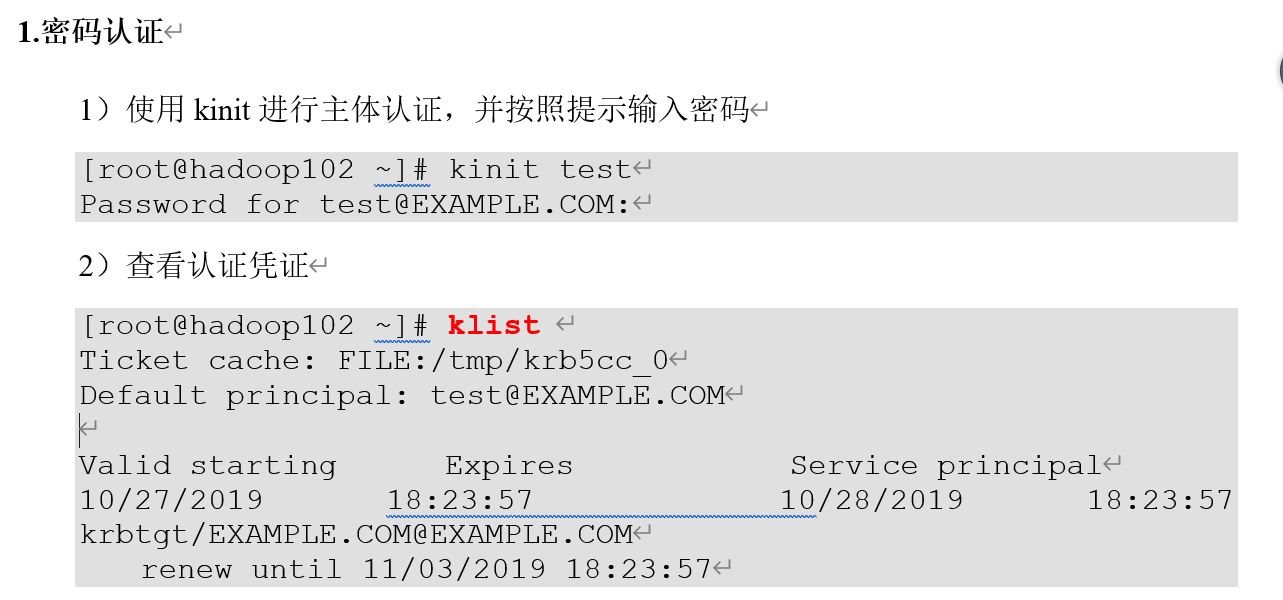
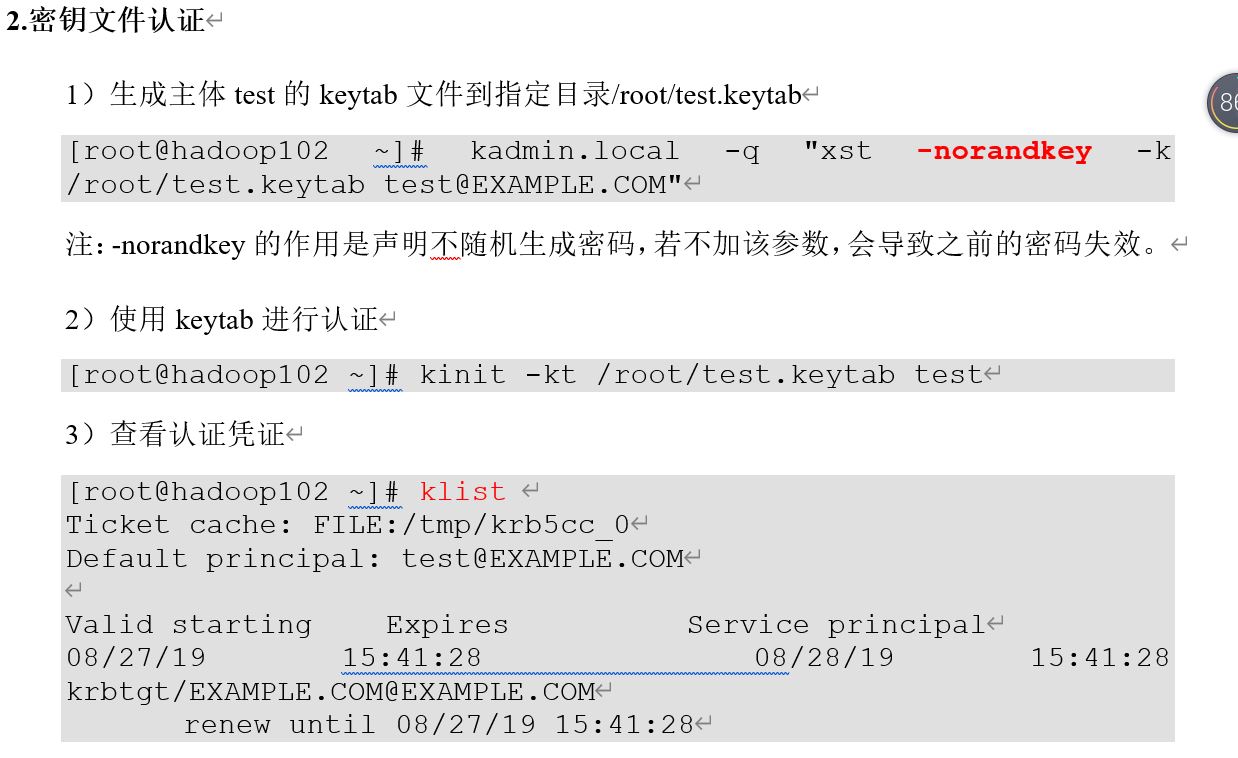
By default Hadoop runs in non-secure mode in which no actual authentication is required.By configuring Hadoop runs in secure mode, each user and service needs to be authenticated by Kerberos in order to use Hadoop services.
During start up the NameNode loads the file system state from the fsimage and the edits log file. It then waits for DataNodes to report their blocks so that it does not prematurely start replicating the blocks though enough replicas already exist in the cluster. During this time NameNode stays in Safemode. Safemode for the NameNode is essentially a read-only mode for the HDFS cluster, where it does not allow any modifications to file system or blocks. Normally the NameNode leaves Safemode automatically after the DataNodes have reported that most file system blocks are available. If required, HDFS could be placed in Safemode explicitly using bin/hadoop dfsadmin -safemode command. NameNode front page shows whether Safemode is on or off. A more detailed description and configuration is maintained as JavaDoc for setSafeMode().