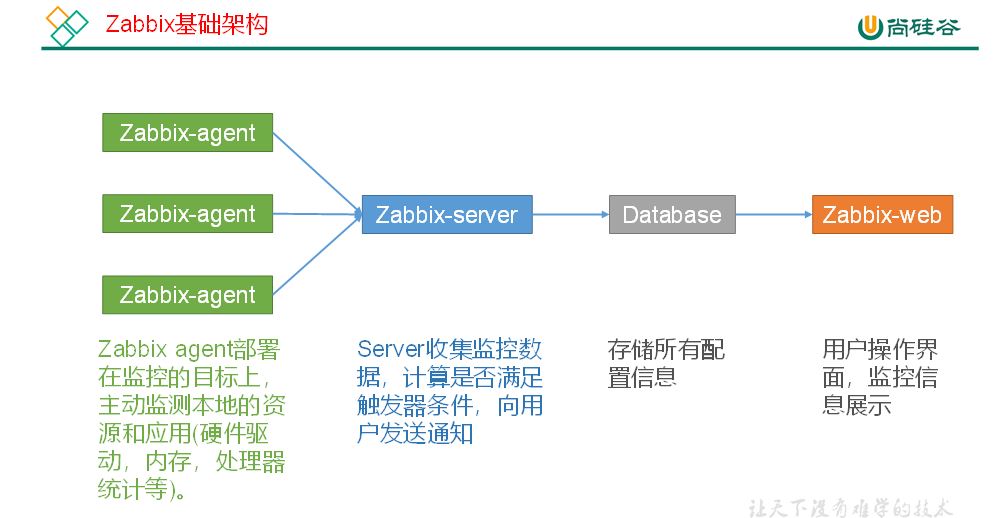
Grafana
Operational dashboards for your data here, there, or anywhere
Grafana是一款用Go语言开发的开源数据可视化工具,可以做数据监控和数据统计,带有告警功能。
Operational dashboards for your data here, there, or anywhere
Grafana是一款用Go语言开发的开源数据可视化工具,可以做数据监控和数据统计,带有告警功能。
Apache HBase is the Hadoop database, a distributed, scalable, big data store. HBase is a type of “NoSQL” database.
HBase是一种构建在HDFS之上的分布式、面向列的存储系统。
Hadoop已经有了HDFS和MapReduce,为什么需要HBase
1 Hadoop可以很好地解决大规模数据的离线批量处理问题,但是,受限于HadoopMapReduce编程框架的高延迟数据处理机制,使得Hadoop无法满足大规模数据实时处理应用的需求。
2 传统的通用关系型数据库无法应对在数据规模剧增时导致的系统扩展性和性能问题(分库分表也不能很好解决)。传统关系数据库在数据结构变化时一般需要停机维护;空列浪费存储空间。
HBase与传统的关系数据库的区别
1、数据类型:关系数据库采用关系模型,具有丰富的数据类型和存储方式,HBase则采用了更加简单的数据模型,它把数据存储为未经解释的字符串。
2、数据操作:关系数据库中包含了丰富的操作,其中会涉及复杂的多表连接。HBase操作则不存在复杂的表与表之间的关系,只有简单的插入、查询、删除、清空等,因为HBase在设计上就避免了复杂的表和表之间的关系。
3、存储模式:关系数据库是基于行模式存储的。HBase是基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的。
4、数据索引:关系数据库通常可以针对不同列构建复杂的多个索引,以提高数据访问性能。HBase只有一个索引——行键,通过巧妙的设计,HBase中的所有访问方法,或者通过行键访问,或者通过行键扫描,从而使得整个系统不会慢下来。
5、数据维护:在关系数据库中,更新操作会用最新的当前值去替换记录中原来的旧值,旧值被覆盖后就不会存在。而在HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍然保留。
6、可伸缩性:关系数据库很难实现横向扩展,纵向扩展的空间也比较有限。相反,HBase和BigTable这些分布式数据库就是为了实现灵活的水平扩展而开发的,能够轻易地通过在集群中增加或者减少硬件数量来实现性能的伸缩。
https://www.cnblogs.com/frankdeng/p/9310191.html
启动成功jps后可以看到hmaster ,hregionservice
不支持sql,对表操作需要使用hbase shell命令或者hbase api
在hbase上构建SQL层,使得hbase 能够使用标准SQL管理数据,Phoenix中的sql语句还是有些不同的
1 org.apache.hadoop.hbase.ipc.ServerNotRunningYetException: Server is not running yet
https://cloud.tencent.com/developer/article/1812290
2 stop-hbase.sh关闭不了,一直处于等待状态
https://blog.csdn.net/weixin_45462732/article/details/106909501
3 hregionservice启动就挂了
看日志
https://www.cnblogs.com/wendyw/p/12691971.html#_label3
https://juejin.cn/post/6844903777347043336
https://www.jianshu.com/p/53864dc3f7b4
https://www.cnblogs.com/frankdeng/p/9310191.html
https://blog.csdn.net/weixin_45462732/article/details/106909501
即席查询(Ad Hoc)是用户根据自己的需求,灵活的选择查询条件,系统能够根据用户的选择生成相应的统计报表。即席查询与普通应用查询最大的不同是普通的应用查询是定制开发的,而即席查询是由用户自定义查询条件的。
举例说明
以电商的数仓分析项目为例,有一些应用侧/业务侧的分析指标:每日活跃用户数(日活),每日留存用户数(留存),新注册用户有多少下了单(转换率),因为计算方法固定,变化的是每天的数据,因此这些指标的查询/计算SQL是提前写好的,到店被调度(Azkaban)执行即可;
但有一些指标或者临时增加的指标、临时增加的一些分析需求,是无法预知其计算逻辑的,所以要现写查询SQL,并且希望能很快拿到查询/计算结果,这就是即席查询
Kylin、druid、presto、impala
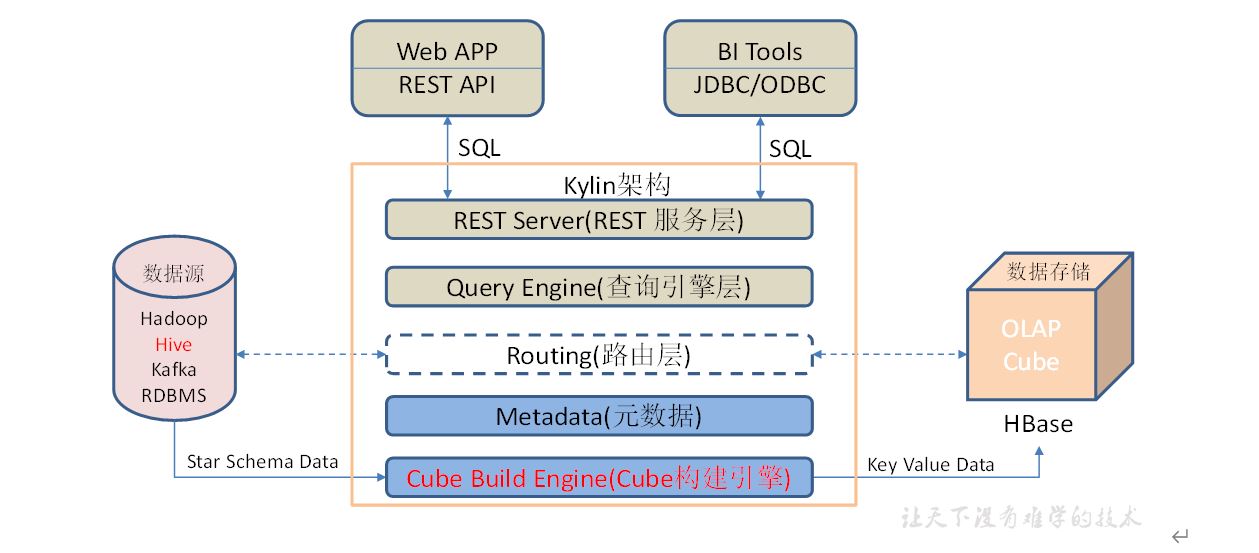
Apache Kylin是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
1)REST Server
REST Server是一套面向应用程序开发的入口点,旨在实现针对Kylin平台的应用开发工作。 此类应用程序可以提供查询、获取结果、触发cube构建任务、获取元数据以及获取用户权限等等。另外可以通过Restful接口实现SQL查询。
2)查询引擎(Query Engine)
当cube准备就绪后,查询引擎就能够获取并解析用户查询。它随后会与系统中的其它组件进行交互,从而向用户返回对应的结果。
3)路由器(Routing)
在最初设计时曾考虑过将Kylin不能执行的查询引导去Hive中继续执行,但在实践后发现Hive与Kylin的速度差异过大,导致用户无法对查询的速度有一致的期望,很可能大多数查询几秒内就返回结果了,而有些查询则要等几分钟到几十分钟,因此体验非常糟糕。最后这个路由功能在发行版中默认关闭。
4)元数据管理工具(Metadata)
Kylin是一款元数据驱动型应用程序。元数据管理工具是一大关键性组件,用于对保存在Kylin当中的所有元数据进行管理,其中包括最为重要的cube元数据。其它全部组件的正常运作都需以元数据管理工具为基础。 Kylin的元数据存储在hbase中。
5)任务引擎(Cube Build Engine)
这套引擎的设计目的在于处理所有离线任务,其中包括shell脚本、Java API以及Map Reduce任务等等。任务引擎对Kylin当中的全部任务加以管理与协调,从而确保每一项任务都能得到切实执行并解决其间出现的故障。
https://jishuin.proginn.com/p/763bfbd2bb9c
可以与Kylin结合使用的可视化工具很多,例如:
ODBC:与Tableau、Excel、PowerBI等工具集成
JDBC:与Saiku、BIRT等Java工具集成
RestAPI:与JavaScript、Web网页集成
Kylin开发团队还贡献了Zepplin的插件,也可以使用Zepplin来访问Kylin服务。

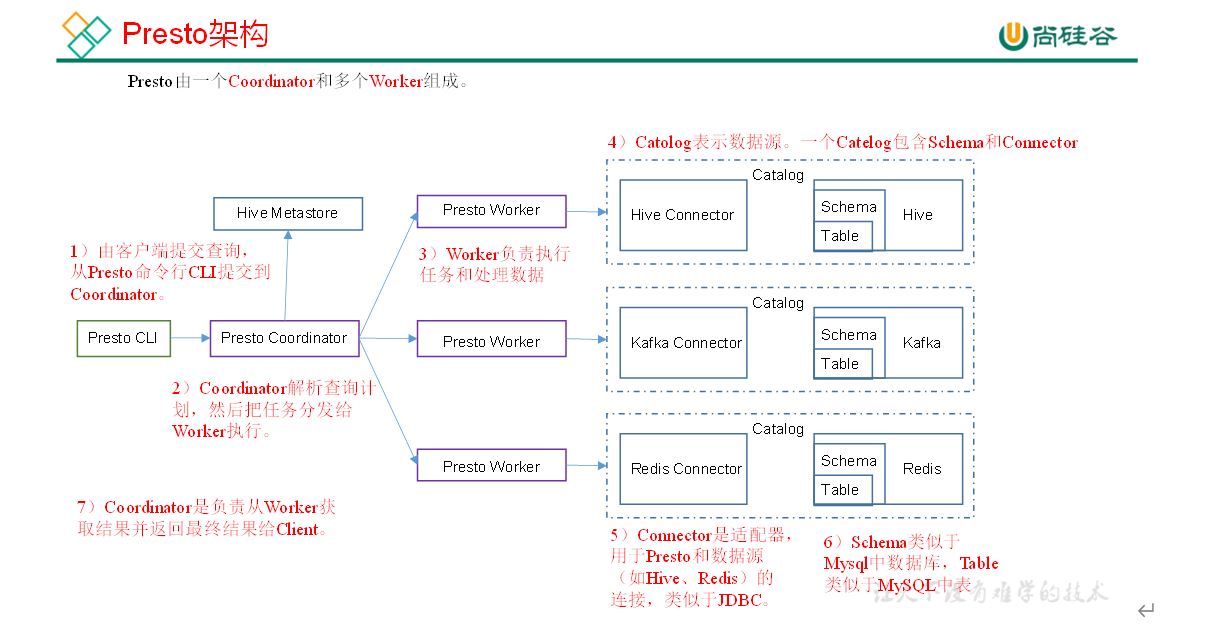
https://blog.csdn.net/u012551524/article/details/79124532
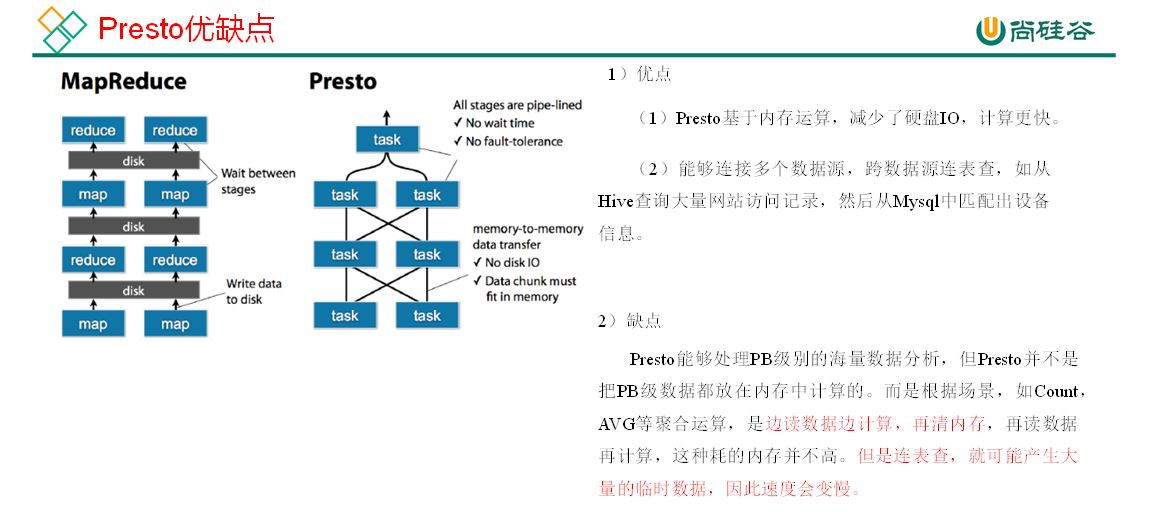
测试结论:Impala性能稍领先于Presto,但是Presto在数据源支持上非常丰富,包括Hive、图数据库、传统关系型数据库、Redis等。
https://blog.csdn.net/wtzhm/article/details/89220508
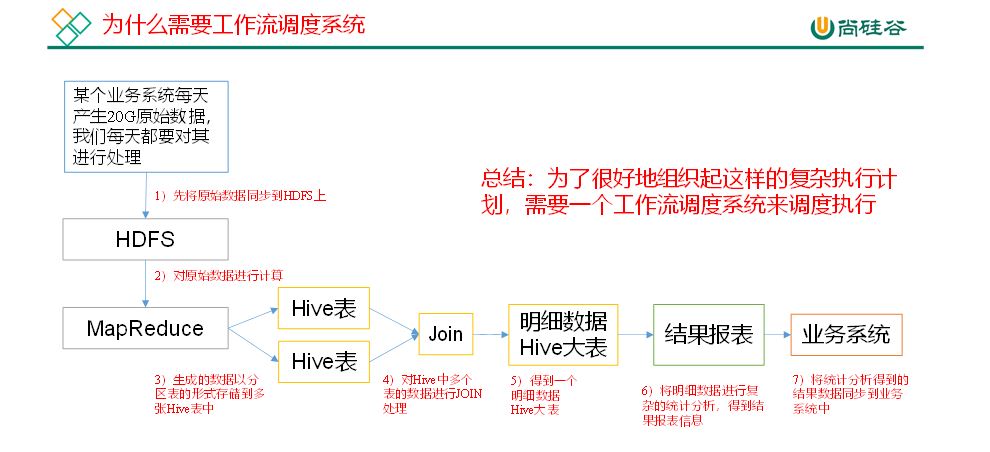
1)一个完整的数据分析系统通常都是由大量任务单元组成:Shell脚本程序,Java程序,MapReduce程序、Hive脚本等
2)各任务单元之间存在时间先后及前后依赖关系
3)为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行
1)简单的任务调度
直接使用Linux的Crontab来定义;
2)复杂的任务调度
开发调度平台或使用现成的开源调度系统,比如Ooize、Azkaban、 Airflow、DolphinScheduler等。
3)Azkaban
Azkaban is a batch workflow job scheduler created at LinkedIn to run Hadoop jobs. Azkaban resolves the ordering through job dependencies and provides an easy to use web user interface to maintain and track your workflows.
Azkaban是一个开源的任务调度系统,用于负责任务的调度运行(如数据仓库调度),用以替代linux中的crontab。
和Oozie对比
总体来说,Ooize相比Azkaban是一个重量级的任务调度系统,功能全面,但配置使用也更复杂。如果可以不在意某些功能的缺失,轻量级调度器Azkaban是很不错的候选对象。

1.数据准备
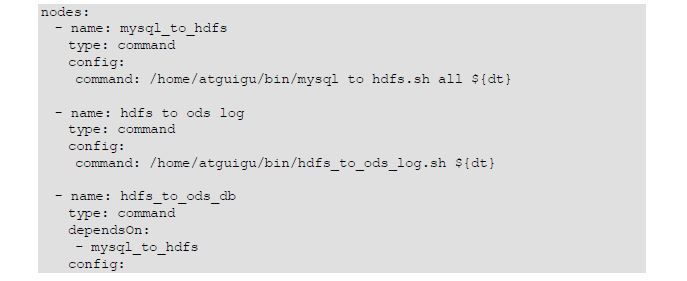
2.编写Azkaban工作流程配置文件
a.编写azkaban.project
b.编写gmall.flow文件
方案一:指定特定的Executor(hadoop102)去执行任务。
a.在MySQL中azkaban数据库executors表中,查询hadoop102上的Executor的id。
b.在执行工作流程时加入useExecutor属性
方案二:在Executor所在所有节点部署任务所需脚本和应用。
推荐使用方案二
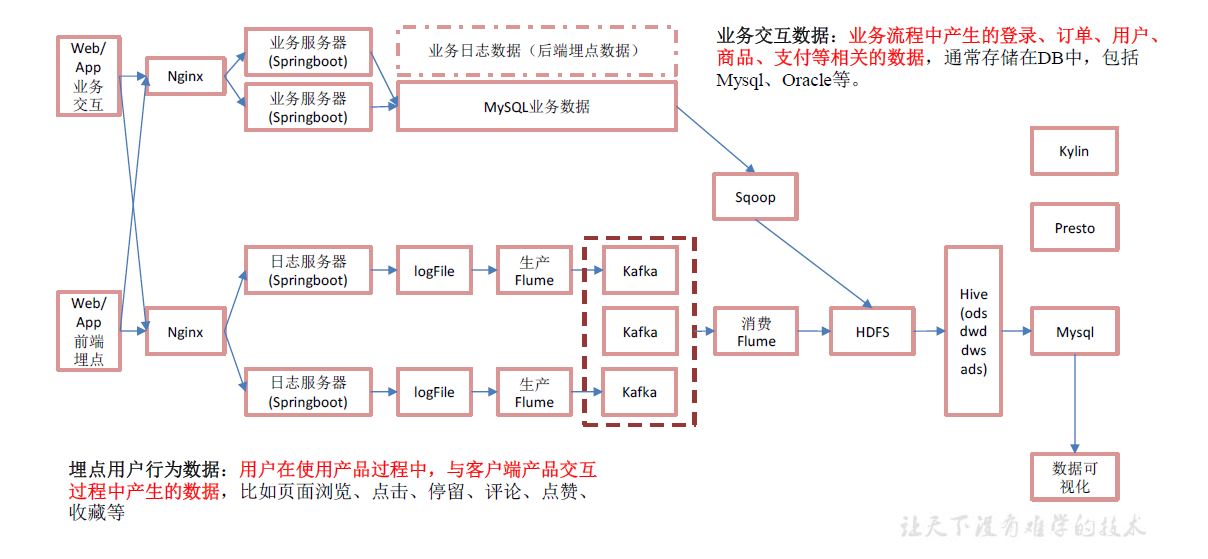
用户在使用产品过程中,通过埋点收集与客户端产品交互过程中产生的数据,并发往日志服务器进行保存。比如页面浏览、点击、停留、评论、点赞、收藏等。用户行为数据通常存储在日志文件中。
我们的日志结构大致可分为两类,一是普通页面埋点日志,二是启动日志。
普通页面日志结构如下,每条日志包含了,当前页面的页面信息,所有事件(动作)、所有曝光信息以及错误信息。除此之外,还包含了一系列公共信息,包括设备信息,地理位置,应用信息等,即下边的common字段。
启动日志结构相对简单,主要包含公共信息,启动信息和错误信息。
就是各行业在处理事务过程中产生的数据。比如用户在电商网站中登录、下单、支付等过程中,需要和网站后台数据库进行增删改查交互,产生的数据就是业务数据。业务数据通常存储在MySQL、Oracle等数据库中。
总共47张表,选了27张业务表
1 用户行为数据
jar-》log(日志服务器)-》flume-》kafka-》flume-》hdfs
2 业务数据
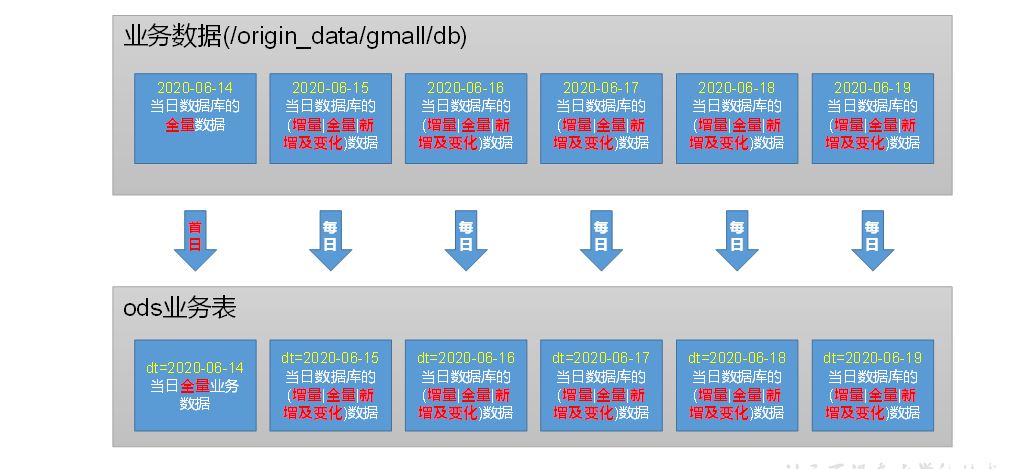
jar-》mysql-》sqoop-》hdfs
hdfs(ori)-》hdfs(ods)
1张表,topic_log -> ods_log
a.建表
就一个字段”line“
b 分区
首日,每日都是全量
c .数据装载
27张表
0 整体
b 同步

c .数据装载
1.活动信息表
activity_info -> ods_activity_info
a 建表
少了个“activity_desc”,多了”dt”

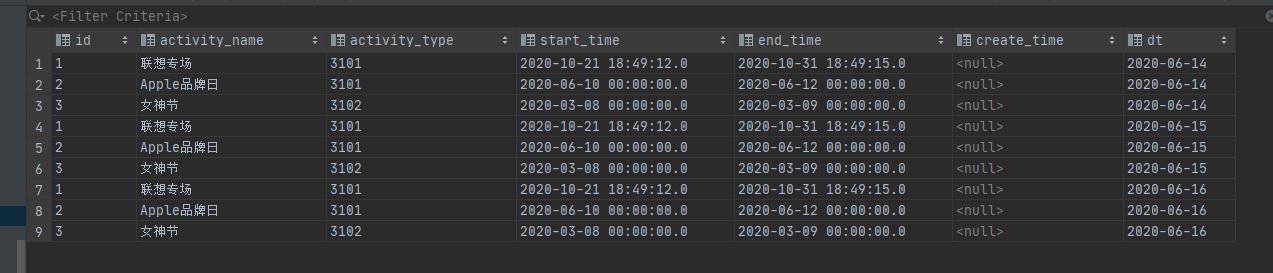
b 同步
首日,每日都是全量
c .数据装载
hdfs(ods)-》hdfs(dim)
构建6张维度表
1 商品维度表
a 建表
b 分区
首日,每日都是全量
c 数据装载
2 优惠券维度表
3 活动维度表
4 地区维度表
b 分区
地区维度表数据相对稳定,变化概率较低,故无需每日装载,首日全量
5 时间维度表
b 分区
通常情况下,时间维度表的数据并不是来自于业务系统,而是手动写入,并且时间维度表数据具有可预见性,无须每日导入,一般首日可一次性导入一年的数据
c 数据装载
1)创建临时表tmp_dim_date_info
2)将数据文件上传到HFDS上临时表指定路径/warehouse/gmall/tmp/tmp_dim_date_info/
3)执行以下语句将其导入时间维度表
1 | insert overwrite table dim_date_info select * from tmp_dim_date_info; |
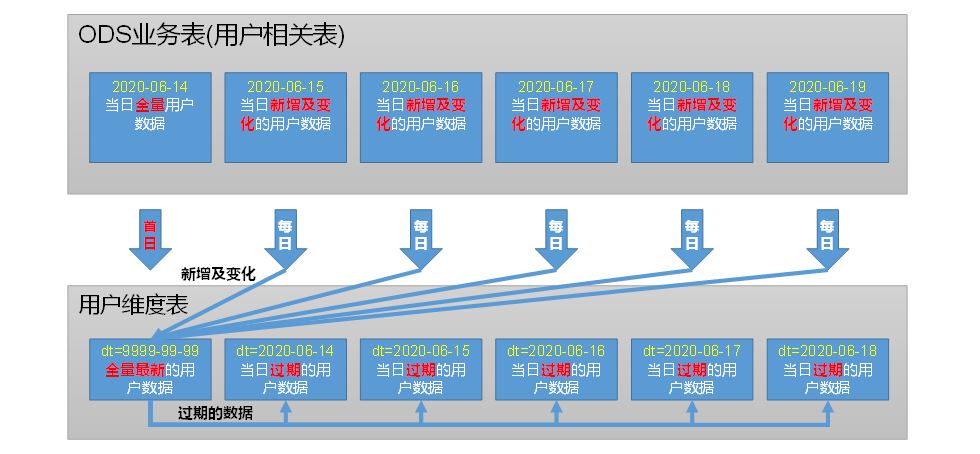
6 用户维度表
b 分区
拉链表
https://cloud.tencent.com/developer/article/1752848#

c 数据装载
hdfs(ods)-》hdfs(dwd)
0 日志数据拆解
ods_log由两部分构成,分别为页面日志和启动日志,拆解成5张表
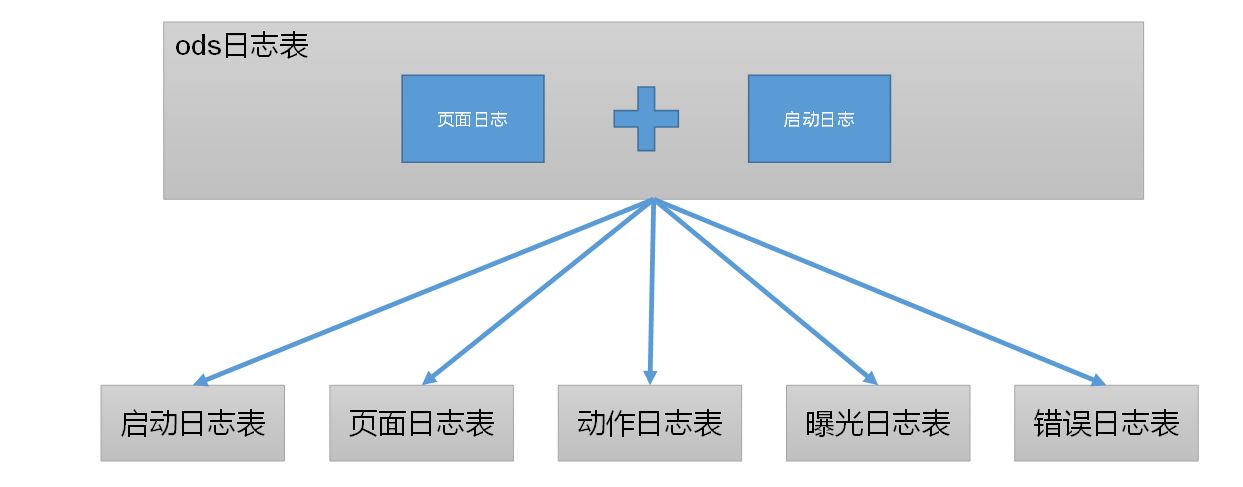
1 启动日志表
b 分区
首日,每日全量
c 数据装载

2 页面日志表
3 动作日志表
4 曝光日志表
5 错误日志表
1 评价事实表(事务型事实表)
b 分区

c 数据装载
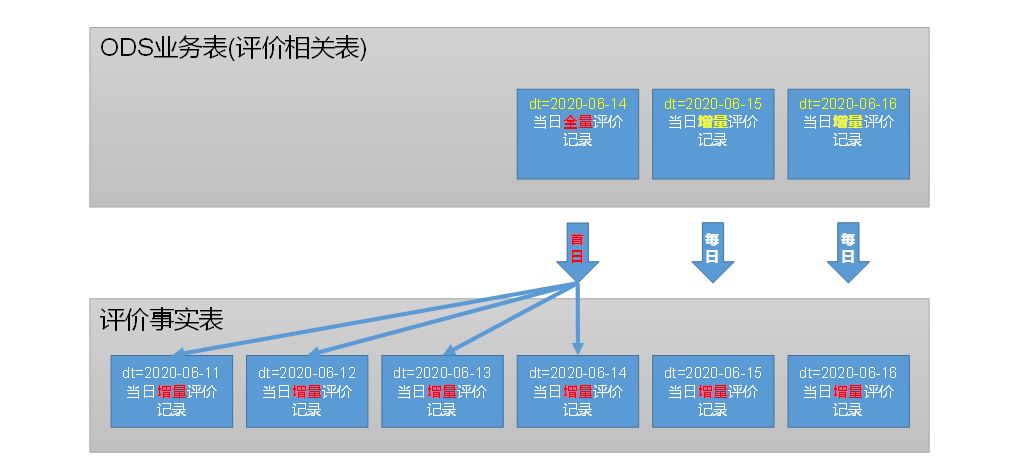
首日,动态分区;每日,静态分区
2 订单明细事实表(事务型事实表)
3 退单事实表(事务型事实表)
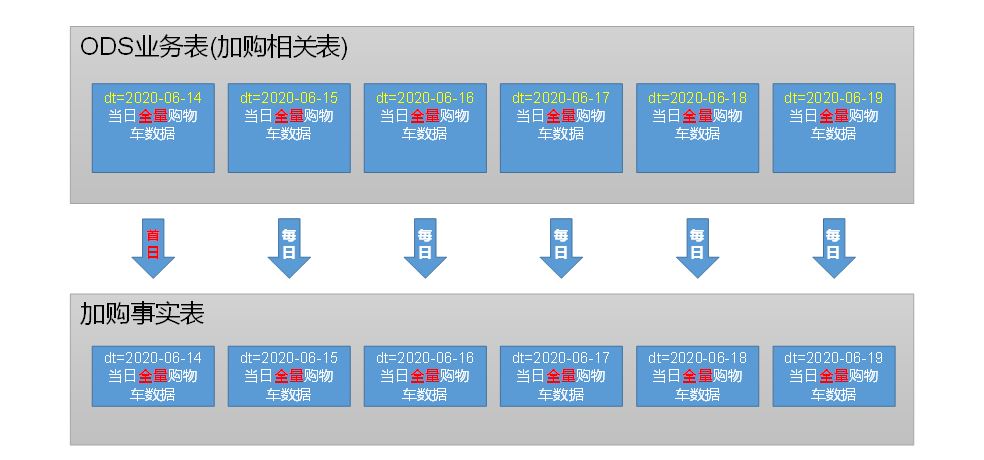
4 加购事实表(周期型快照事实表)
b 分区

c 数据加载
5 收藏事实表(周期型快照事实表)
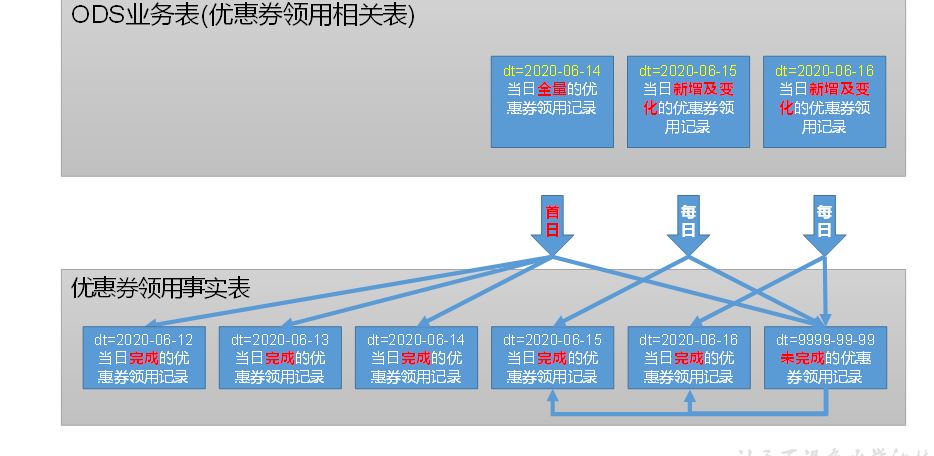
6 优惠券领用事实表(累积型快照事实表)
b 分区

c 数据加载
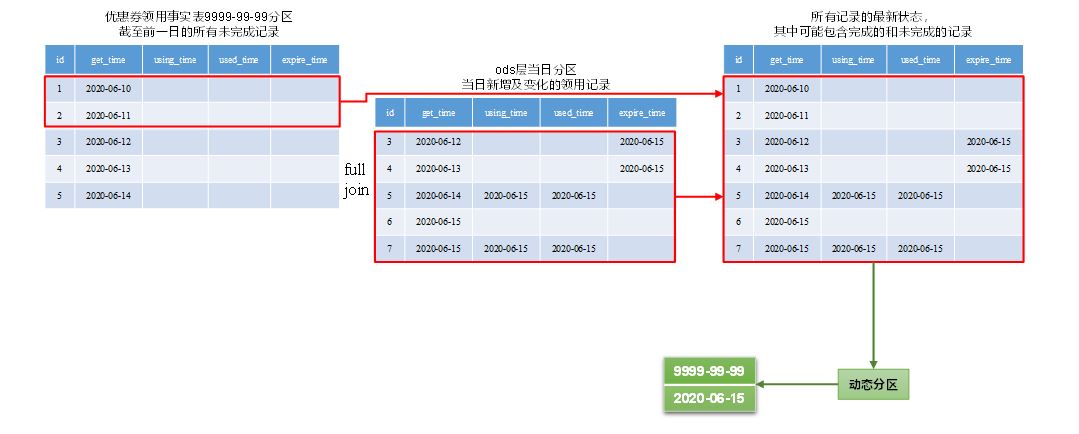
(1)首日
1 | insert overwrite table dwd_coupon_use partition(dt) |
(2)每日
7 支付事实表(累积型快照事实表)
8 退款事实表(累积型快照事实表)
9 订单事实表(累积型快照事实表)
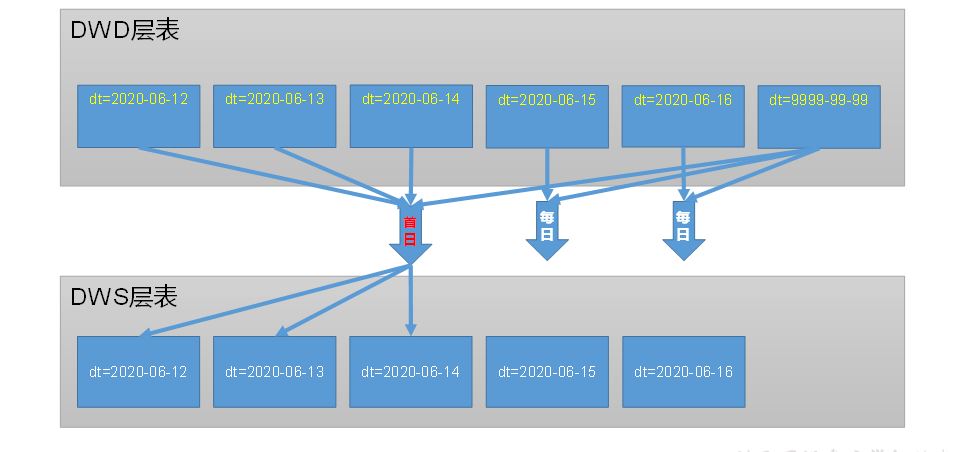
hdfs(dwd)-》hdfs(dws)
0 整体
b 分区

c 数据装载
1 访客主题
2 用户主题
3 商品主题
4 优惠券主题
5 活动主题
6 地区主题
hdfs(dws)-》hdfs(DWT)
0 整体
c 数据装载
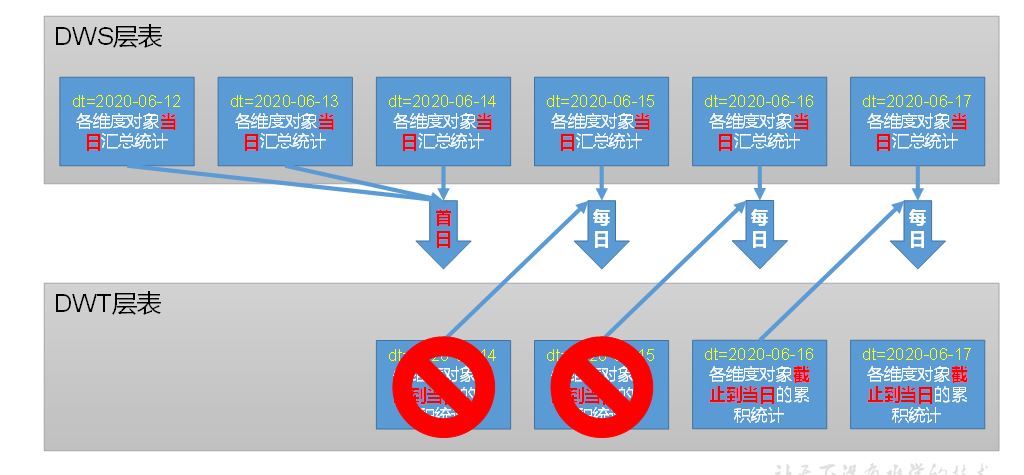
只保留当天和前一天的分区,过时的需要清理掉i
1 访客主题
2 用户主题
3 商品主题
4 优惠券主题
5 活动主题
6 地区主题
hdfs(DWT)-》hdfs(ADS)-》mysql
1 访客统计
a 建表
| 指标 | 说明 | 对应字段 |
|---|---|---|
| 访客数 | 统计访问人数 | uv_count |
| 页面停留时长 | 统计所有页面访问记录总时长,以秒为单位 | duration_sec |
| 平均页面停留时长 | 统计每个会话平均停留时长,以秒为单位 | avg_duration_sec |
| 页面浏览总数 | 统计所有页面访问记录总数 | page_count |
| 平均页面浏览数 | 统计每个会话平均浏览页面数 | avg_page_count |
| 会话总数 | 统计会话总数 | sv_count |
| 跳出数 | 统计只浏览一个页面的会话个数 | bounce_count |
| 跳出率 | 只有一个页面的会话的比例 | bounce_rate |
b 分区
c 数据装载
第一步:对所有页面访问记录进行会话的划分。
第二步:统计每个会话的浏览时长和浏览页面数。
第三步:统计上述各指标。
2 路径分析
用户访问路径的可视化通常使用桑基图
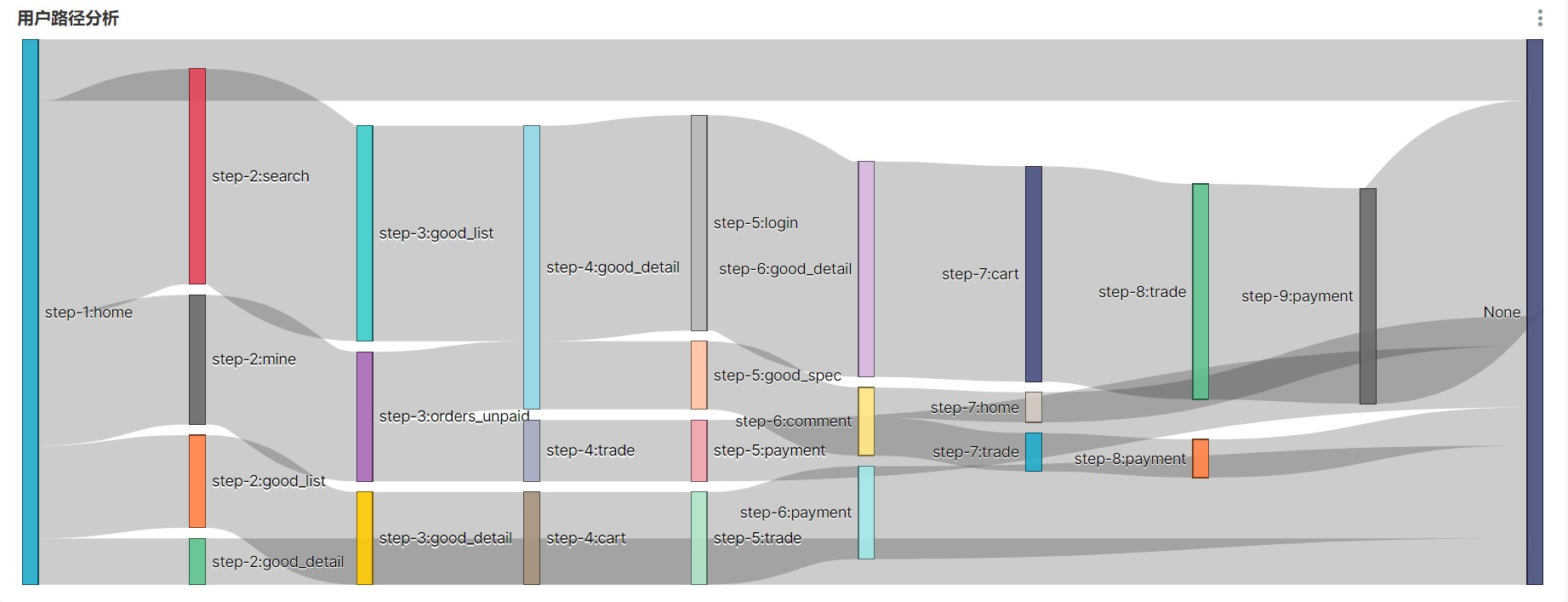
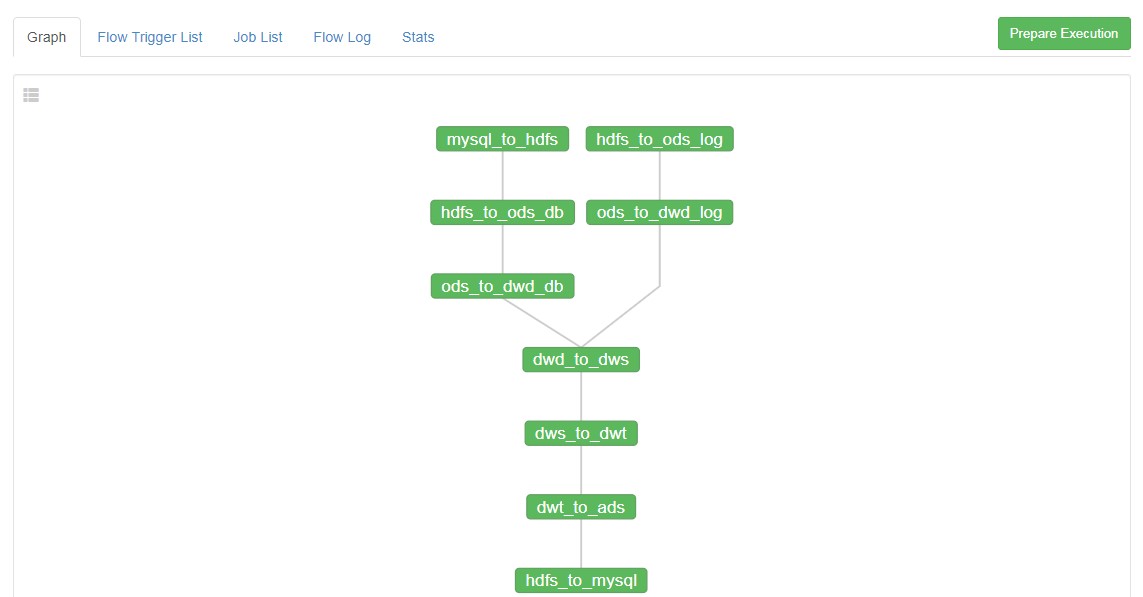
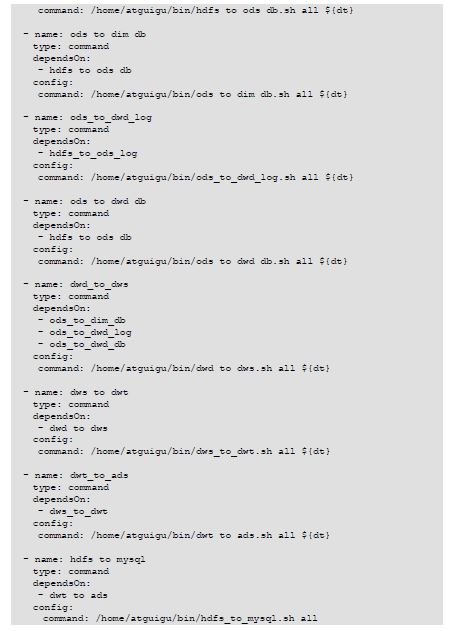
就是将原来写的脚本文件串起来
Navicat
破解
https://cdmana.com/2022/114/202204240555321952.html
DataGrip
需要用到JDBC协议连接到Hive,故需要启动HiveServer2。
DataGrip 版是由JetBrains 公司(就是那个出品Intellij IDEA 的公司)推出的数据库管理软件。
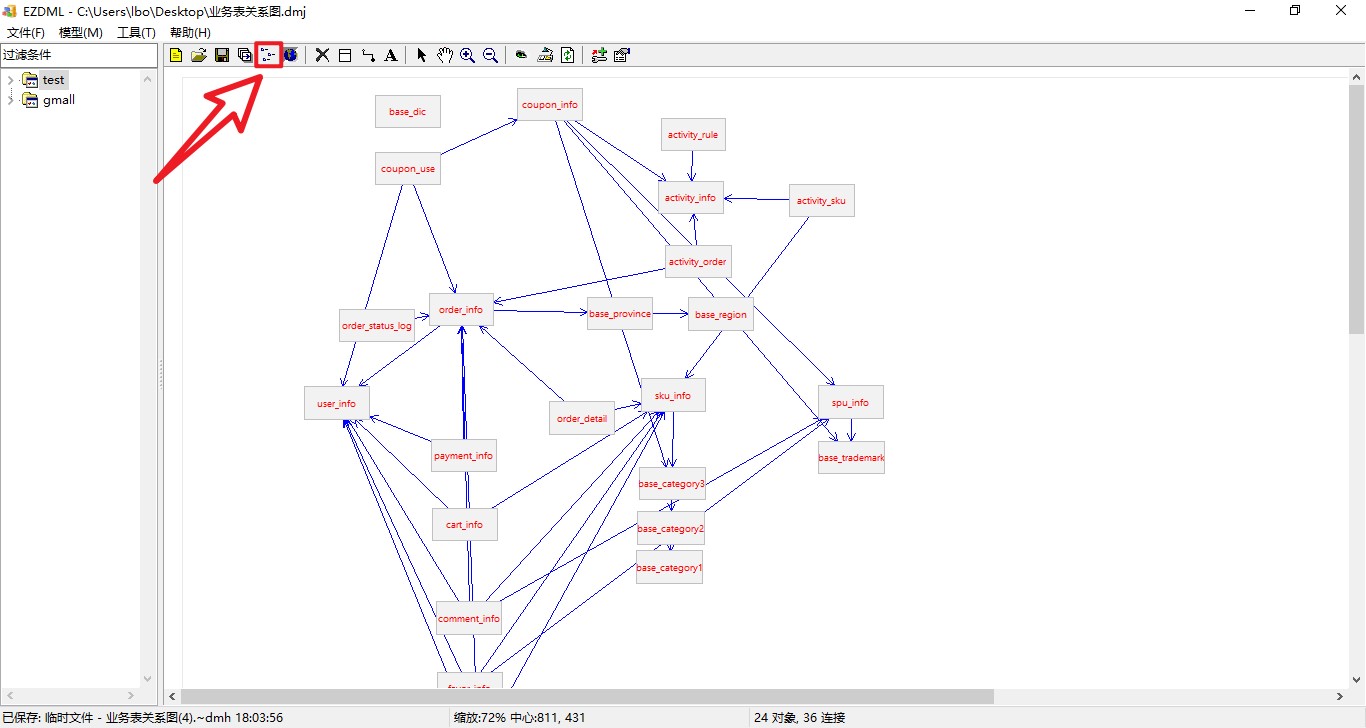
EZDML
来辅助我们梳理复杂的业务表关系,效果如下