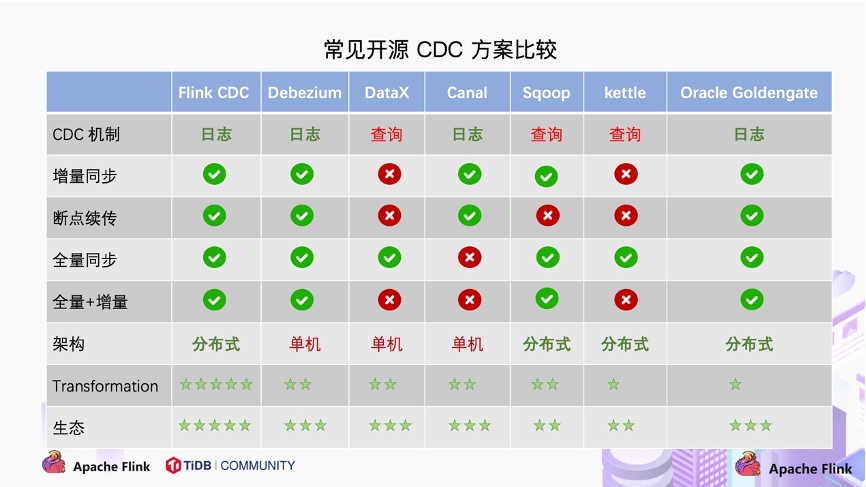
https://zhuanlan.zhihu.com/p/269780713
https://help.aliyun.com/document_detail/137663.html
异构数据集成
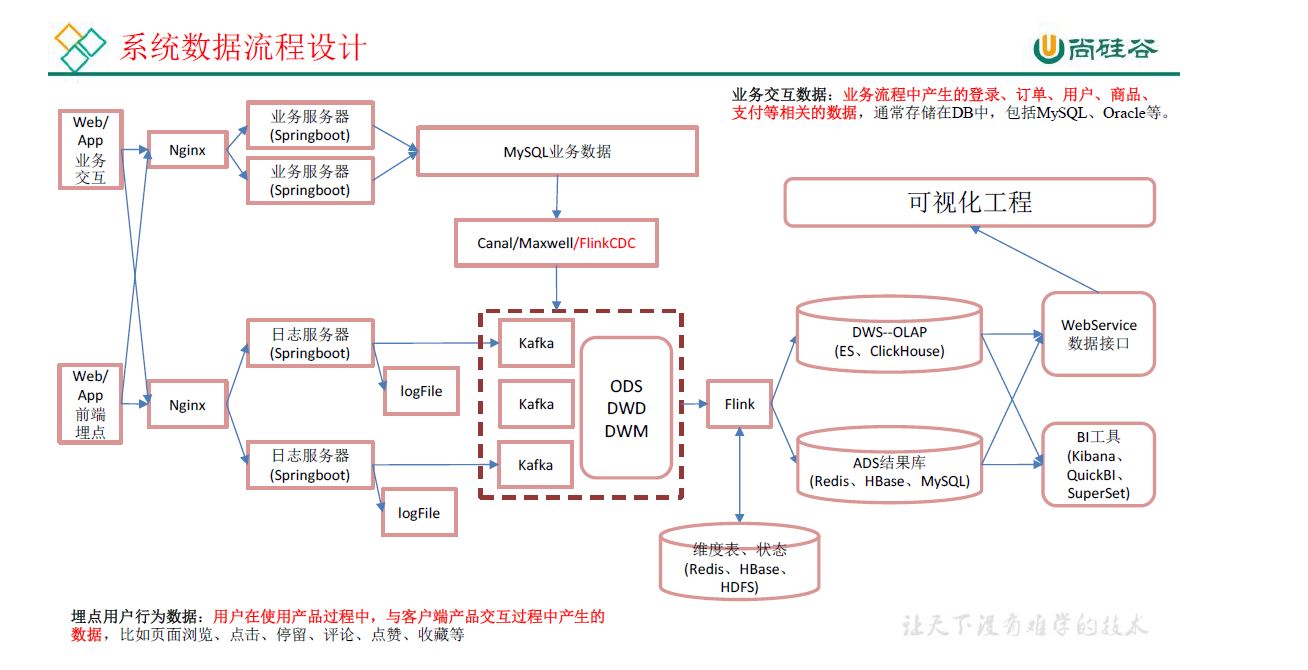
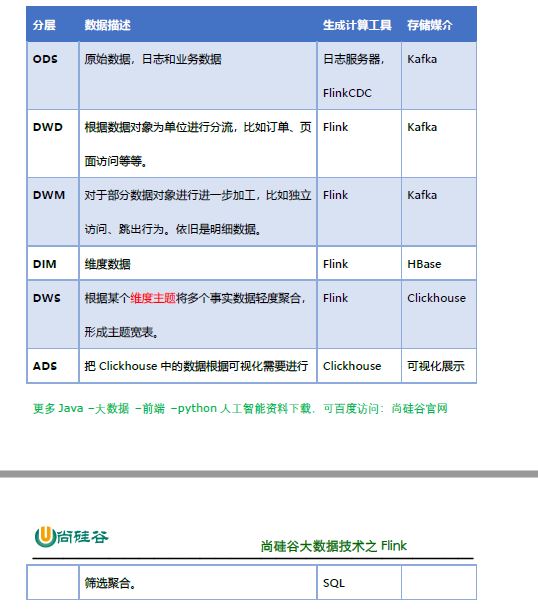
1 日志数据
前端(jar,产生日志数据)-》Nginx(集群间负载均衡)-》日志服务器(springboot,采集数据,jar)-》log,ods(kafka)
本地测试,本地起应用 -》 单机部署,单服务器起应用 -》 集群部署,集群起应用
2 业务数据
前端,jar,产生业务数据-》mysql,配置什么同步-》flinkcdc-》ods(kafka)
1 用户行为日志
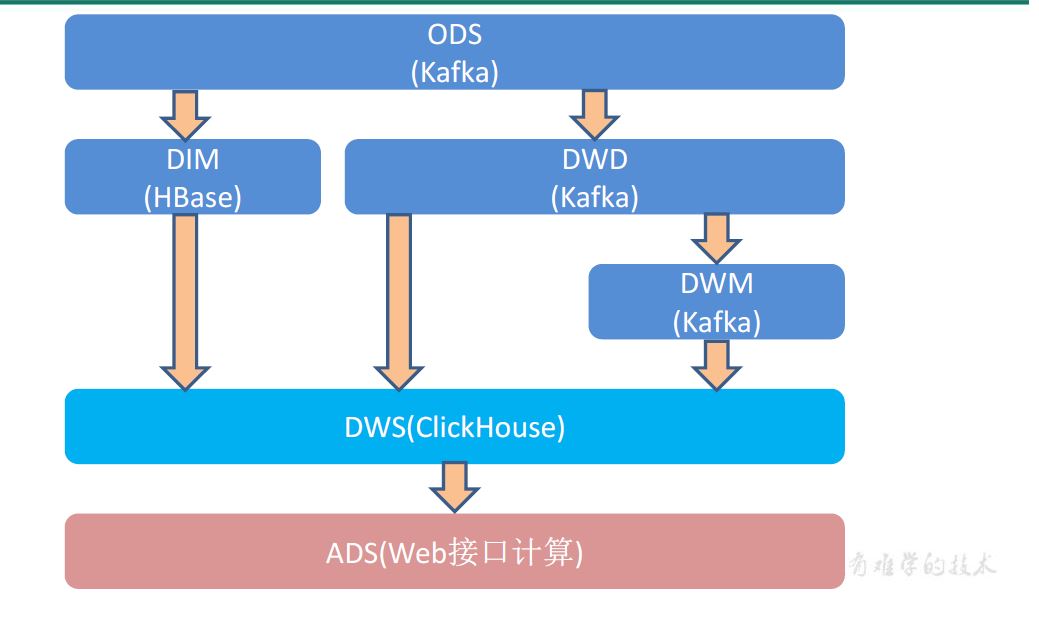
ods(Kafka)-> flink -> dwd(kafka)
1 识别新老用户
业务需要
2 日志数据拆分
这3类日志,结构不同,写回Kafka不同主题
2 业务数据
ods(kafka) -> flink -> 1 维度数据,dim(HBASE) 2 事实数据 dwd(kafka)
1 ETL
过滤控制
2 动态分流
维度数据到hbase 事实数据到kafka
怎么分流?
ods的表里面哪些是维度表,哪些是事实表,需要提前知道表的分类信息,后面才可以分流。业务库的表会变化,表的分类信息实时更新,需要动态同步。这里将表的分类信息存在mysql,利用广播流发送。
dmd(kafka)-> flink -> dwm(kafka)
1 访问uv计算
UV,unique visitor
2 跳出明细计算
跳出率=跳出次数 / 访问次数
3 订单主题表
4 支付主题表
dwm(kafka)-> flink -> dws(clickhouse)
1 访客主题宽表
2 商品主题宽表
3 地区主题表
4 关键词主题表
启动命令
1 | /opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties |
关闭命令
1 | /opt/module/kafka/bin/kafka-server-stop.sh stop |
topic

生产

消费

查看消费情况
指定offset
https://blog.csdn.net/jianghuaijie/article/details/122009653
作用
DWM层的定位是什么,DWM层主要服务DWS,因为部分需求直接从DWD层到DWS层中间会有一定的计算量,而且这部分计算的结果很有可能被多个DWS层主题复用
构建
分主题
实时数仓没有dwt,因为dwt是累计统计,实时系统不适用
作用
轻度聚合,生成一系列的中间表,提升公共指标的复用性,减少重复加工
分主题,便于管理
构建
分主题
宽表
轻度聚合
https://blog.csdn.net/yu0_zhang0/article/details/81776459
https://www.jianshu.com/p/28b825367ba1
https://www.jianshu.com/p/d53f528daca7
Hive索引的目标是提高对表的某些列进行查询查找的速度。
索引所能提供的查询速度的提高是以存储索引的磁盘空间为代价的。
Hive 3.0开始将 移除index的功能,取而代之的是Hive 2.3版本开始的物化视图,自动重写的物化视图替代了index的功能。
https://blog.csdn.net/u011447164/article/details/105790713
区别于普通视图
1 | create materialized view view2 |
https://blog.csdn.net/yhb315279058/article/details/51035631
https://www.cnblogs.com/yanshw/p/11988347.html
增加 Driver 内存
1 | --driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M). |
1 读入数据太大
解决思路是增加 Driver 内存
1 | from pyspark import SparkContext |
2 数据回传太大,也就是聚合到driver的数据太大
解决思路是分区输出,具体做法是 foreach
1 | rdd = sc.parallelize(range(100)) |
通用的解决办法就是增加 Executor 内存 但这并不一定是最好的办法
1 map 过程产生大量对象
解决思路是减少每个 task 的大小,从而减少每个 task 的输出
具体做法是在 会产生大量对象的 map 操作前 添加 repartition(重新分区) 方法,分区成更小的块传入 map
1 | rdd.flatMap(lambda x: ['%d'%x*50 for _ in range(100000000)]).count() # 100 * 100000000 个对象,内存溢出 |
2 shuffle导致
shuffle内存溢出的情况可以说都是shuffle后发生数据倾斜,单个文件过大导致
参考数据倾斜解决方案
https://blog.csdn.net/JasonDing1354/article/details/46882585
https://blog.csdn.net/dengxing1234/article/details/73613484
容错指的是一个系统在部分模块出现故障时还能否持续的对外提供服务
https://blog.csdn.net/wzy0623/article/details/49797421
https://www.google.com/search?q=Degenerate+Dimension&sourceid=chrome&ie=UTF-8
https://www.jamesserra.com/archive/2011/11/degenerate-dimensions/
https://blog.csdn.net/yezonghui/article/details/120131320
当一个维度没有数据仓库需要的任何数据的时候就可以退化此维度,需要把退化的相关数据迁移到事实表中,然后删除退化的维度。
https://www.jianshu.com/p/d518e9f5d5f9
1 好处
a. 提高代码可读性
结构清晰
b. 优化执行速度
子查询结果存在内存中,不需要重复计算
2 用法
1 | with table_name as(子查询语句) 其他sql; |
1 | with temp as ( |
与基本表不同,它是一个虚表。在数据库中,存放的只是视图的定义,而不存放视图包含的数据项,这些项目仍然存放在原来的基本表结构中。
视图是只读的,不能向视图中插入或加载或改变数据
作用:
1 便捷
通过引入视图机制,用户可以将注意力集中在其关心的数据上(而非全部数据),这样就大大提高了用户效率与用户满意度,而且如果这些数据来源于多个基本表结构,或者数据不仅来自于基本表结构,还有一部分数据来源于其他视图,并且搜索条件又比较复杂时,需要编写的查询语句就会比较烦琐,此时定义视图就可以使数据的查询语句变得简单可行。
2 安全
定义视图可以将表与表之间的复杂的操作连接和搜索条件对用户不可见,用户只需要简单地对一个视图进行查询即可,故增加了数据的安全性,但不能提高查询效率。
创建
1 | CREATE VIEW [IF NOT EXISTS] view_name [(column_name [COMMENT column_comment], ...) ] |
删除
1 | DROP VIEW view_name |