groupByKey creates a lot of shuffling which hampers the performance, while reduceByKey does not shuffle the data as much
持久化
https://cloud.tencent.com/developer/article/1760389
https://blog.csdn.net/dudadudadd/article/details/114102341
https://yiqingqing.blog.csdn.net/article/details/121772325
https://blog.csdn.net/feizuiku0116/article/details/122839247
https://blog.csdn.net/CyAurora/article/details/119654676
https://www.cnblogs.com/Transkai/p/11347224.html
https://blog.csdn.net/CyAurora/article/details/119654676
https://blog.csdn.net/dudadudadd/article/details/114102341
1 缓存
懒执行
空间换时间
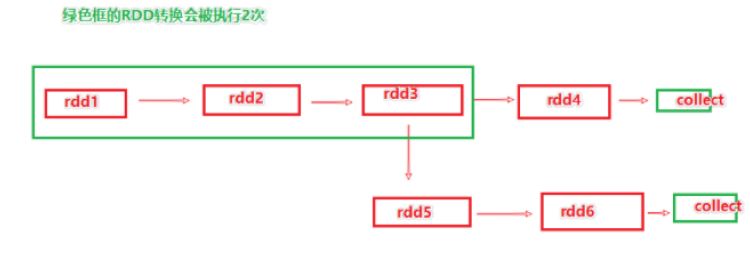
rdd3如果不消失,那么绿色链路就不用执行两次
持久化的目标就是将rdd3保存到内存或者磁盘
但是有丢失风险,比如硬盘损坏,内存被清理等,所以为了规避风险,会保留rdd的血缘(依赖)关系
如何保存:
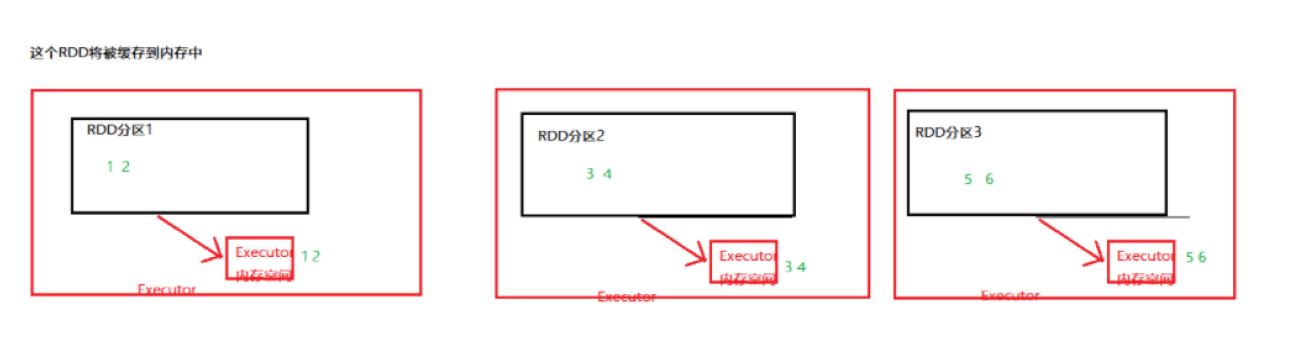
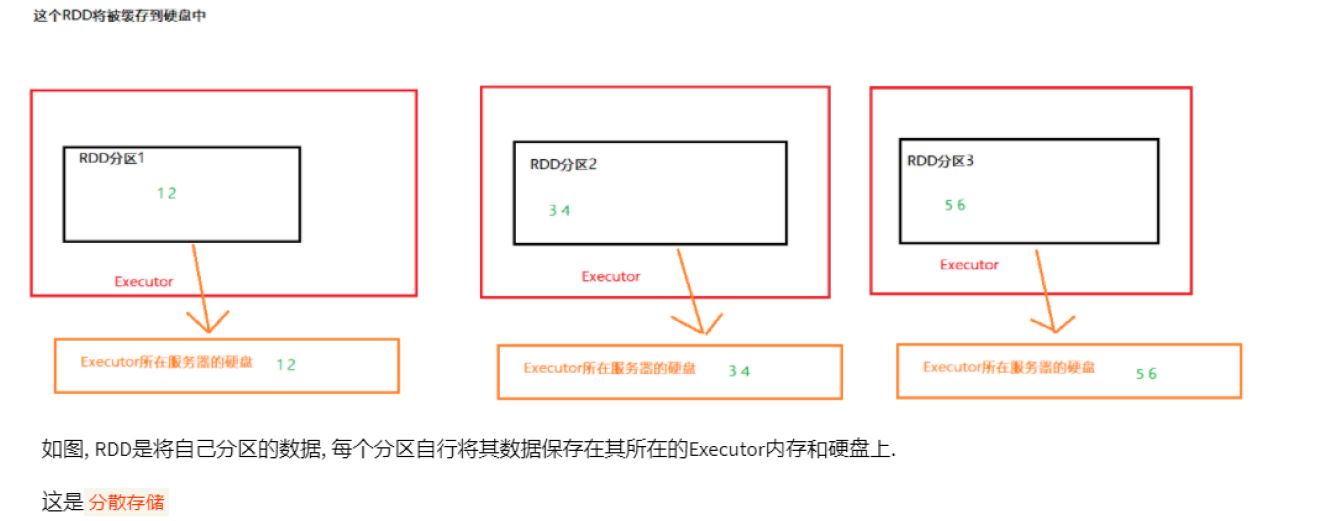
1 persist

2 cache
https://blog.csdn.net/donger__chen/article/details/86366339
底层调用persist,persist的特殊情况,persist(MEMORY_ONLY)
2 checkpoint
特殊的持久化
仅支持硬盘
设计上认为安全没有风险,所以不需要保留血缘关系
如何保存:
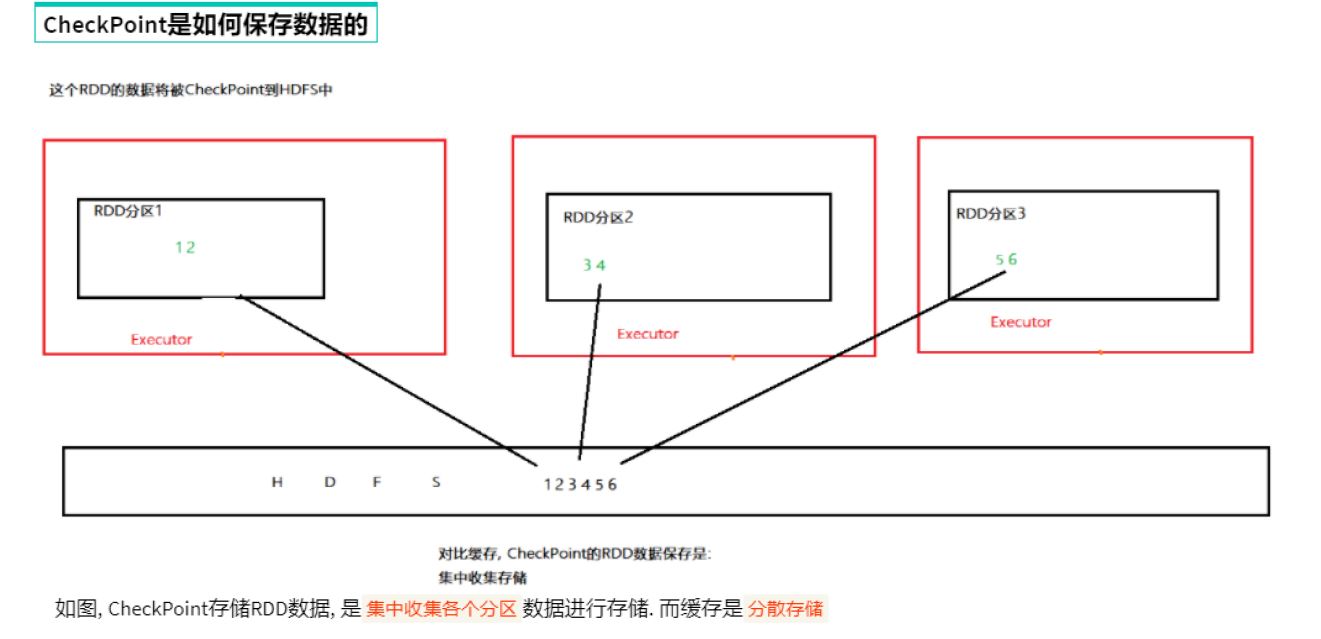
3 对比


pyspark
PySpark宗旨是在不破坏Spark已有的运行时架构,在Spark架构外层包装一层Python API,借助Py4j实现Python和Java的交互,进而实现通过Python编写Spark应用程序
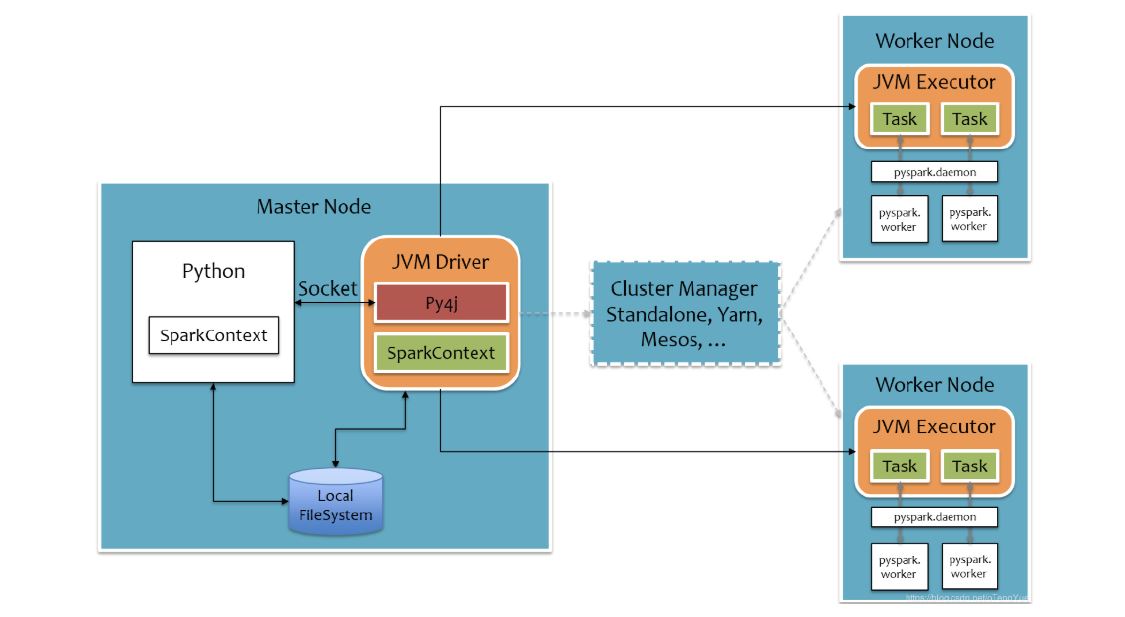
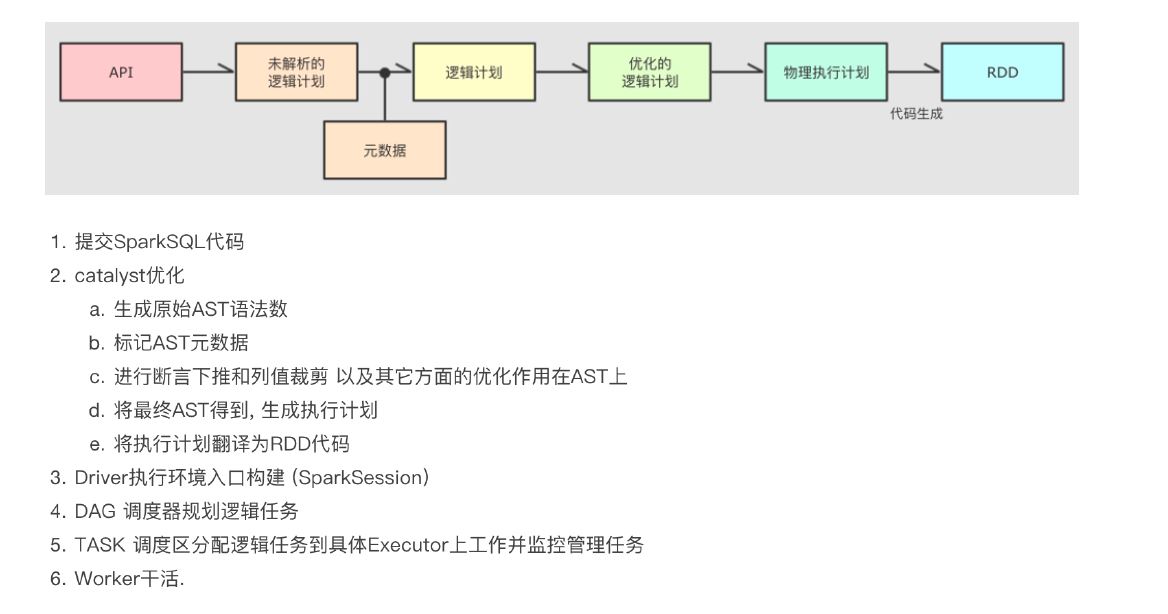
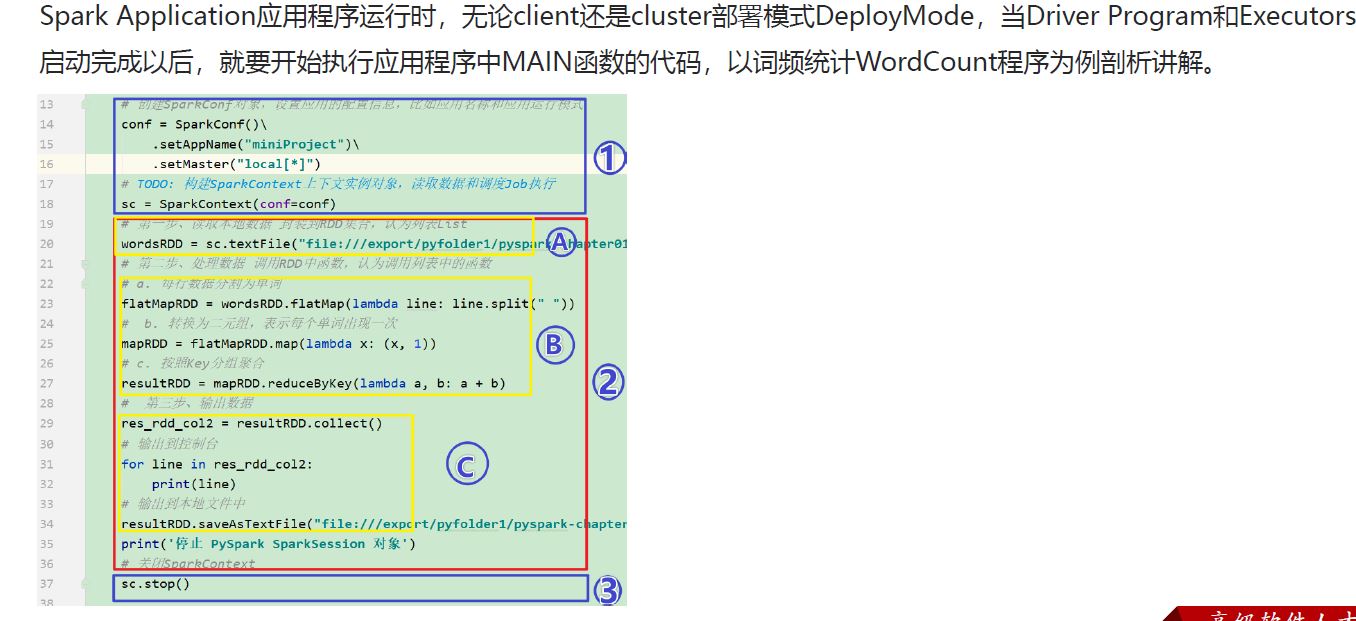
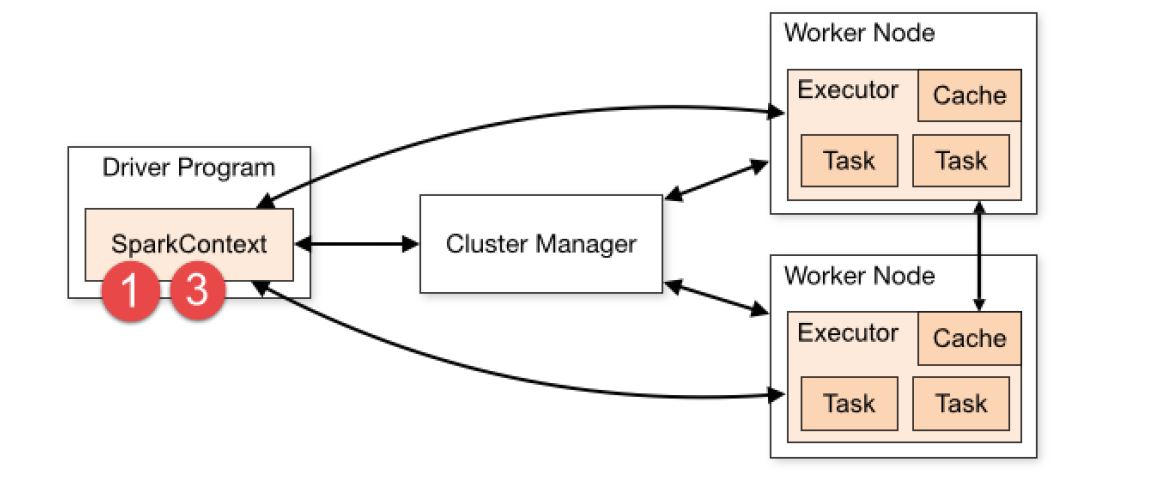
Sparkcore运行流程

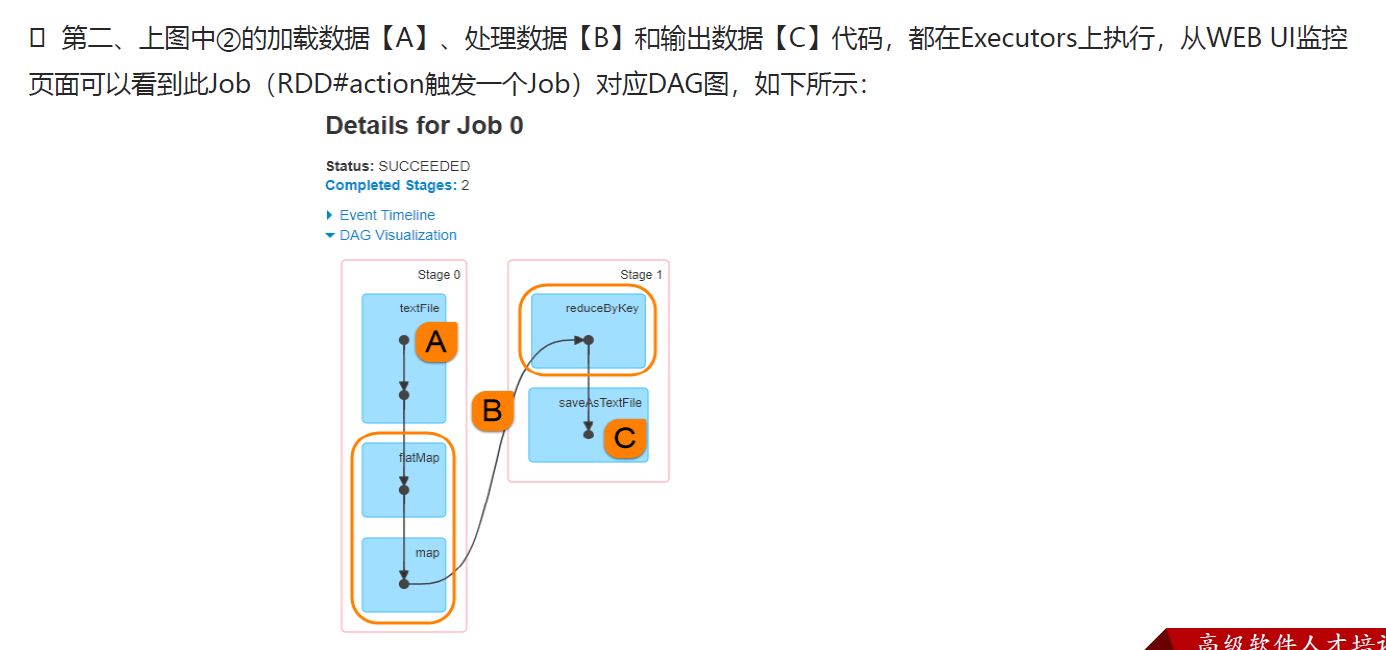
Hive与传统数据库对比
| Hive | 传统数据库 | |
|---|---|---|
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Raw Device或者 Local FS |
| 数据格式 | 用户自定义 | 系统决定 |
| 数据更新 | 不支持 | 支持 |
| 执行 | MapReduce | Excutor |
| 执行延迟 | 高 | 低 |
| 处理数据规模 | 大 | 小 |
| 索引 | 0.8版本后加入位图索引 | 有复杂的索引 |
| 可扩展性 | 高 | 低 |
IaaS、PaaS和SaaS
IaaS: Infrastructure-as-a-Service(基础设施即服务)
PaaS: Platform-as-a-Service(平台即服务)
SaaS: Software-as-a-Service(软件即服务)
各组件web ui的地址
https://blog.csdn.net/qq_41851454/article/details/79938811
node ip+port
yarn
resource maneger +8088
hdfs
namenode +50070/9870/9871
spark
4040: 是一个运行的Application在运行的过程中临时绑定的端口,用以查看当前任务的状态.4040被占用会顺延到4041.4042等.4040是一个临时端口,当前程序运行完成后, 4040就会被注销哦。当使用spark交互工具,如spark-sql,spark-shell
8080: 默认是StandAlone下, Master角色(进程)的WEB端口,用以查看当前Master(集群)的状态
18080: 默认是历史服务器的端口, 由于每个程序运行完成后,4040端口就被注销了. 在以后想回看某个程序的运行状态就可以通过历史服务器查看,历史服务器长期稳定运行,可供随时查看被记录的程序的运行过程.
配置历史服务器
https://blog.csdn.net/Heitao5200/article/details/79674684
https://blog.csdn.net/yu0_zhang0/article/details/80396080
注意端口号和hadoop一致,9000->8020
flink
Apache Flink runs the dashboard on port 8081. Since this is a common port there might be conflict with some other services running on the same machines
port和端口可以在flink/conf/flink-conf.yaml 中查看
hive metastore
端口9083
hbase
16010
dataframe
0.两种风格
DataFrame支持两种风格进行编程,分别是:
1 DSL风格
DSL称之为:领域特定语言。
其实就是指DataFrame的特有API
DSL风格意思就是以调用API的方式来处理Data
比如:df.where().limit()
2 SQL风格
SQL语法风格
SQL风格就是使用SQL语句处理DataFrame的数据
比如:spark.sql(“SELECT * FROM xxx)
1 用户自定义函数

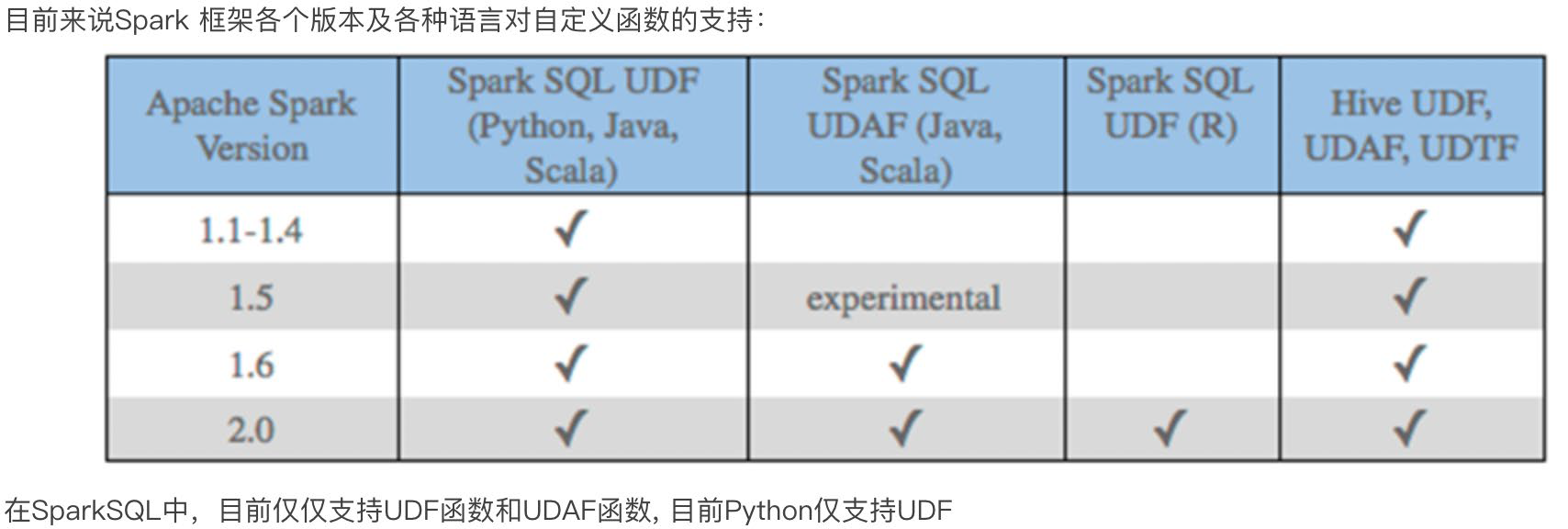
步骤:
https://blog.csdn.net/qq_43665254/article/details/112379113
https://blog.csdn.net/sunflower_sara/article/details/104044412
1、定义函数
2、注册函数
3、使用函数
2 withColumn
1 | from pyspark.sql.functions import col, lit |