--type1 CASE <表达式> WHEN <值1> THEN <操作> WHEN <值2> THEN <操作> ... ELSE <操作> END --type2 CASE WHEN <条件1> THEN <命令> WHEN <条件2> THEN <命令> ... ELSE commands END
# Write your MySQL query statement below select t.business_id from (select *, avg(E1.occurences ) over(partition by E1.event_type ) as ave_occu from Events E1 ) t where t.occurences > t.ave_occu group by t.business_id having count(t.business_id)>=2
4 判断
1 in
(E1.id , E1.month) in ((1,8))
2 BETWEEN AND
BETWEEN ‘2019-06-28’ AND ‘2019-07-27’
3 EXISTS
用于判断查询子句是否有记录,如果有一条或多条记录存在返回 True,否则返回 False。
1 2 3 4
SELECT column_name(s) FROM table_name WHERE EXISTS (SELECT column_name FROM table_name WHERE condition);
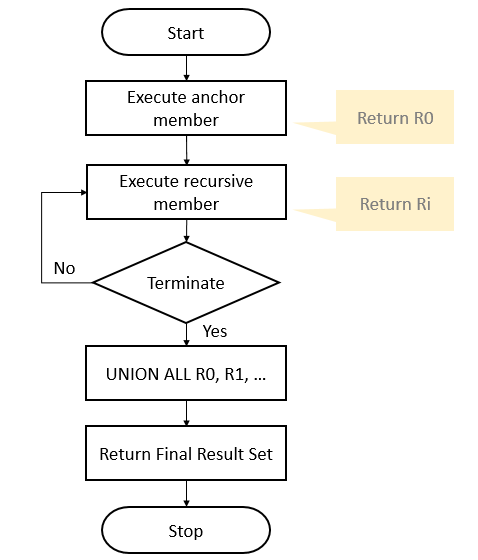
WITH expression_name (column_list) AS ( -- Anchor member initial_query UNION ALL -- Recursive member that references expression_name. recursive_query ) -- references expression name SELECT * FROM expression_name
SELECT UserID,ManagerID,Name,Name AS ManagerName FROM dbo.Employee WHERE ManagerID=-1
userid
managerid
name
managername
1
-1
boss
boss
R1:
1 2 3
SELECT c.UserID,c.ManagerID,c.Name,p.Name AS ManagerName FROM CTE P INNERJOIN dbo.Employee c ON p.UserID=c.ManagerID
此时Employee为完整的,cte为
userid
managerid
name
managername
1
-1
boss
boss
得到结果为
c.userid
c.managerid
c.name
c.managername
p.userid
p.managerid
p.name
p.managername
11
1
A1
A1
1
-1
boss
boss
12
1
A2
A2
1
-1
boss
boss
13
1
A3
A3
1
-1
boss
boss
1
SELECT c.UserID,c.ManagerID,c.Name,p.Name AS ManagerName
userid
managerid
name
name
11
1
A1
boss
12
1
A2
boss
13
1
A3
boss
R2,R3…
最后union all R0,R1,R2,。。。
16 select 常数
1 2 3 4 5 6 7 8 9 10 11 12 13
SELECT 1,-1,N'Boss' UNION ALL SELECT 11,1,N'A1' UNION ALL SELECT 12,1,N'A2' UNION ALL SELECT 13,1,N'A3' UNION ALL SELECT 111,11,N'B1' UNION ALL SELECT 112,11,N'B2' UNION ALL SELECT 121,12,N'C1'
sum(frequency) over(partiton by num ) --分组累加 sum(frequency) over() --total_frequency 全部累加 sum(frequency) over(order by num desc) --desc_frequency, 逆序累加 sum(frequency) over(order by num asc) --asc_frequency,正序累加 SUM(Salary) OVER (PARTITION BY Id ORDER BY Month asc range 2 PRECEDING) --range 2 PRECEDING 当前以及前面2行
avg(frequency) over() --total_frequency ,全部平均 avg(frequency) over(order by num desc) --desc_frequency, 逆序平均 avg(frequency) over(order by num asc) --asc_frequency, 正序平均
select distinct C1.seat_id as seat_id from Cinema C1 join Cinema C2 on C1.free=1 and C2.free=1 and abs(C1.seat_id-C2.seat_id)=1 order by seat_id
power
1 2 3 4
# Write your MySQL query statement below select round(min(Power(Power(P1.x-P2.x,2)+Power(P1.y-P2.y,2),0.5)),2) as shortest from Point2D P1 join Point2D P2 on P1.x!=P2.x or P1.y!=P2.y
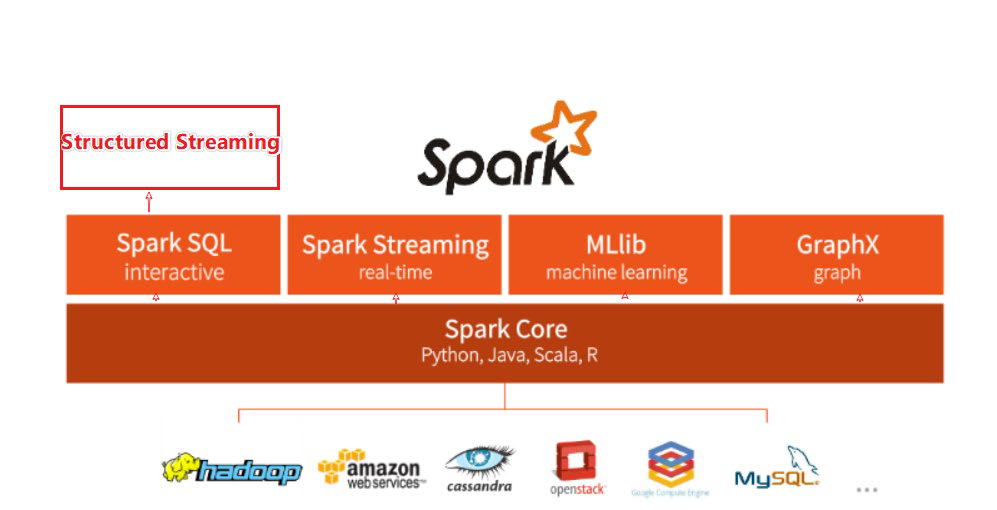
From the introduction, we understood that MapReduce enables the processing of data and hence is majorly a data processing engine.
Spark, on the other hand, is a framework that drives complete analytical solutions or applications and hence making it an obvious choice for data scientists to use this as a data analytics engine.
Framework’s Performance and Data Processing
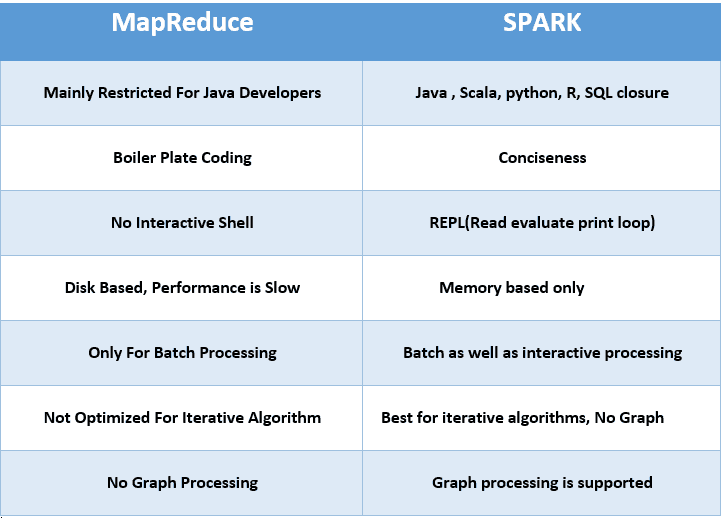
In the case of MapReduce, reading and writing operations are performed from and to a disk thus leading to slowness in the processing speed.
In Spark, the number of read/write cycles is minimized along with storing data in memory allowing it to be 10 times faster. But spark may suffer a major degradation if data doesn’t fit in memory.
Latency
As a result of lesser performance than Spark, MapReduce has a higher latency in computing.
Since Spark is faster, it enables developers with low latency computing.
Manageability of framework
MapReduce being only a batch engine, other components must be handled separately yet synchronously thus making it difficult to manage.
Spark is a complete data analytics engine, has the capability to perform batch, interactive streaming, and similar component all under the same cluster umbrella and thus easier to manage!
Real-time Analysis
MapReduce was built mainly for batch processing and hence fails when used for real-time analytics use cases.
Data coming from real-time live streams like Facebook, Twitter, etc. can be efficiently managed and processed in Spark.
Interactive Mode
MapReduce doesn’t provide the gamut of having interactive mode.
In spark it is possible to process the data interactively
Security
MapReduce has accessibility to all features of Hadoop security and as a result of this, it is can be easily integrated with other projects of Hadoop Security. MapReduce also supports ASLs.
In Spark, the security is by default set to OFF which might lead to a major security fallback. In the case of authentication, only the shared secret password method is possible in Spark.
Tolerance to Failure
In case of crash of MapReduce process, the process is capable of starting from the place where it was left off earlier as it relies on Hard Drives rather than RAMs
In case of crash of Spark process, the processing should start from the beginning and hence becomes less fault-tolerant than MapReduce as it relies of RAM usage.