Deep Match to Rank Model for Personalized Click-Through Rate Prediction
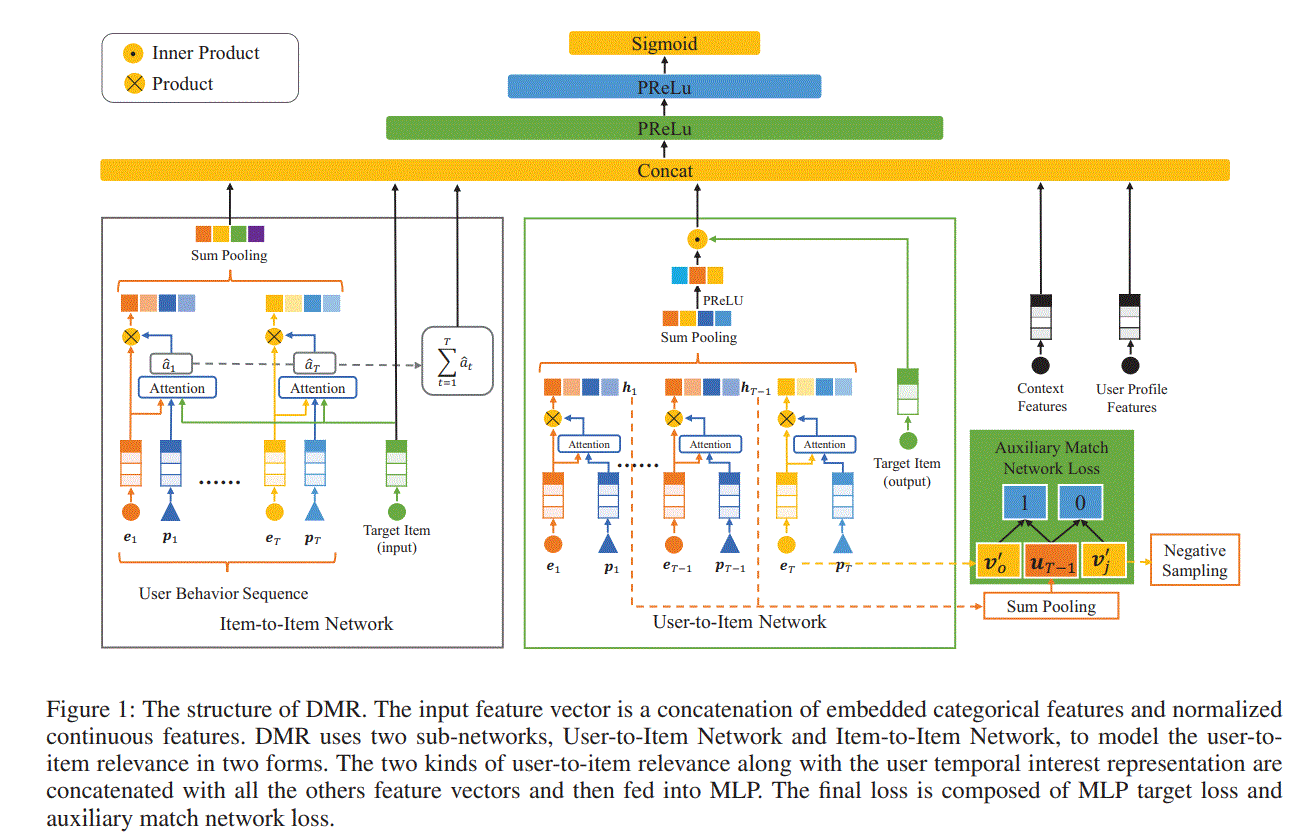
1 输入特征
由4个部分构成,分别为User Profile, User Behavior, Target Item and Context,每个特征都包含子特征,比如User Profile contains user ID, consumption level and so on。最初的表示为one-hot形式,经过embedding层,转成高纬向量,通过查找表来实现。最后4个特征分别表示为$\textbf{x}_p,\textbf{x}_b,\textbf{x}_t,\textbf{x}_c$,以$\textbf{x}_b$来举例,$\textbf{x}_b=[e_1,e_2,…,e_T]\in \mathbb{R}^{T\times d_e}$
2 User-to-Item Network
we apply attention mechanism with positional encoding as query to adaptively learn the weight for each behavior,where the position of user behavior is the serial number in the behavior sequence ordered by occurred time
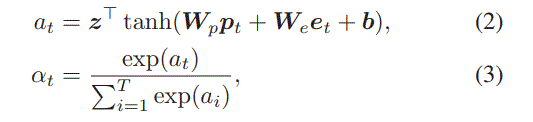
其中$\textbf{z}\in \mathbb{R}^{d_h}$是学习的参数,$\textbf{p}_t\in \mathbb{P}^{d_p}$是位置$t$的embedding
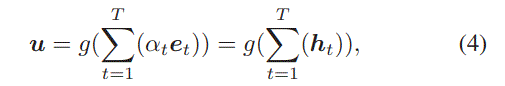
为什么不用$\textbf{x}_t$,而用$\textbf{v}^{‘}$表示Target Item。作者的意思是对于Target Item,有两个查找表,we call $\textbf{V}$ the input representation and $\textbf{V}^{‘}$ the output representation of Target Item。we apply inner product operation to represent the user-to-item relevance

3 Item-to-Item Network
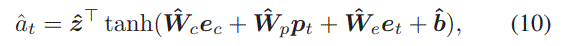

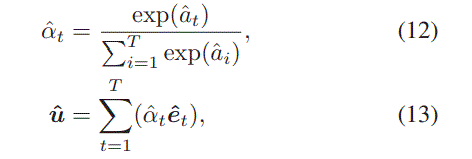
4 final
And the final input of MLP is represented by $\textbf{c}=[\textbf{x}_p,\textbf{x}_t,\textbf{x}_c,\hat{\textbf{u}},r,\hat{r}]$
5 loss
target
The loss for input feature vector $\textbf{x}=[\textbf{x}_p,\textbf{x}_b,\textbf{x}_t,\textbf{x}_c]$ and click label $ y \in \{0, 1\} $is:
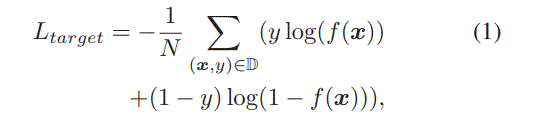
auxiliary match network
主要是提高$r$对于user-to-item relevance的表现能力而引入。
The probability that user with the first $T −1$ behaviors click item $j$ next can be formulated with the softmax function as:
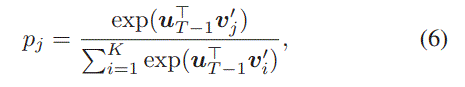
其中$\textbf{v}^{‘}_j$表示第$j$个商品的output representation。With cross-entropy as loss function, we have the loss as follows:
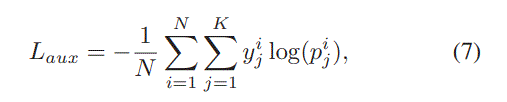
However, the cost of computing $p_j$ in Equation (6) is huge,引入负采样,然后loss为
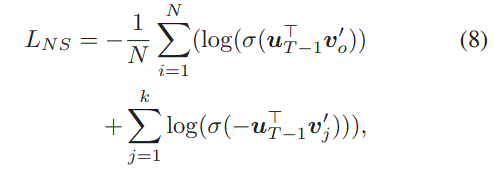
final
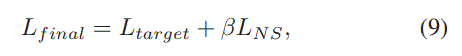
参考
阿里2020年发表在AAAI上的关于CTR的paper,原文链接 https://sci-hub.se/10.1609/aaai.v34i01.5346
常见问题
CTR模型为什么普遍采用二分类建模而不是回归建模
https://zhuanlan.zhihu.com/p/372110635
CTR 预估和推荐系统有什么区别???
https://blog.csdn.net/qiqi123i/article/details/105259351
CTR 预估和排序学习有什么区别???
CTR预估模型属于point-wise模型
Deep Interest Evolution Network for Click-Through Rate Prediction
1.概述
对din的改进
din:强调用户兴趣是多样的,并使用基于注意力模型来捕获用户的兴趣
dien:不但要找到用户的兴趣,还要抓住用户兴趣的变化过程
2.结构
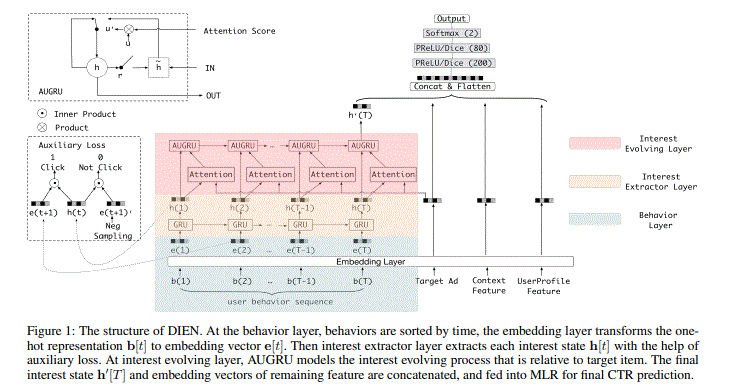
1 behavior layer
Feature Representation
User Profile, User Behavior, Ad and Context
one-hot vector
Embedding
transforms the large scale sparse feature into lowdimensional dense feature
2 Interest Extractor Layer
利用GRU作为基本单元
3 Interest Evolving Layer
主要两个部分,一个是attention一个是AUGRU
attention
用公式表示为:
AUGRU
结构如上图,用式子表达如下:
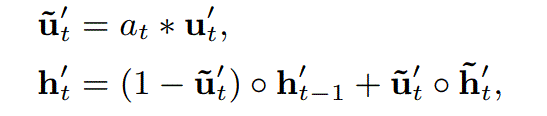
3 loss
target
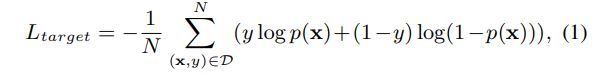
为了提高准确率引入Auxiliary loss
其中$\sigma$为sigmoid
global loss:
参考
Deep Interest Network for Click-Through Rate Prediction
1.DEEP INTEREST NETWORK
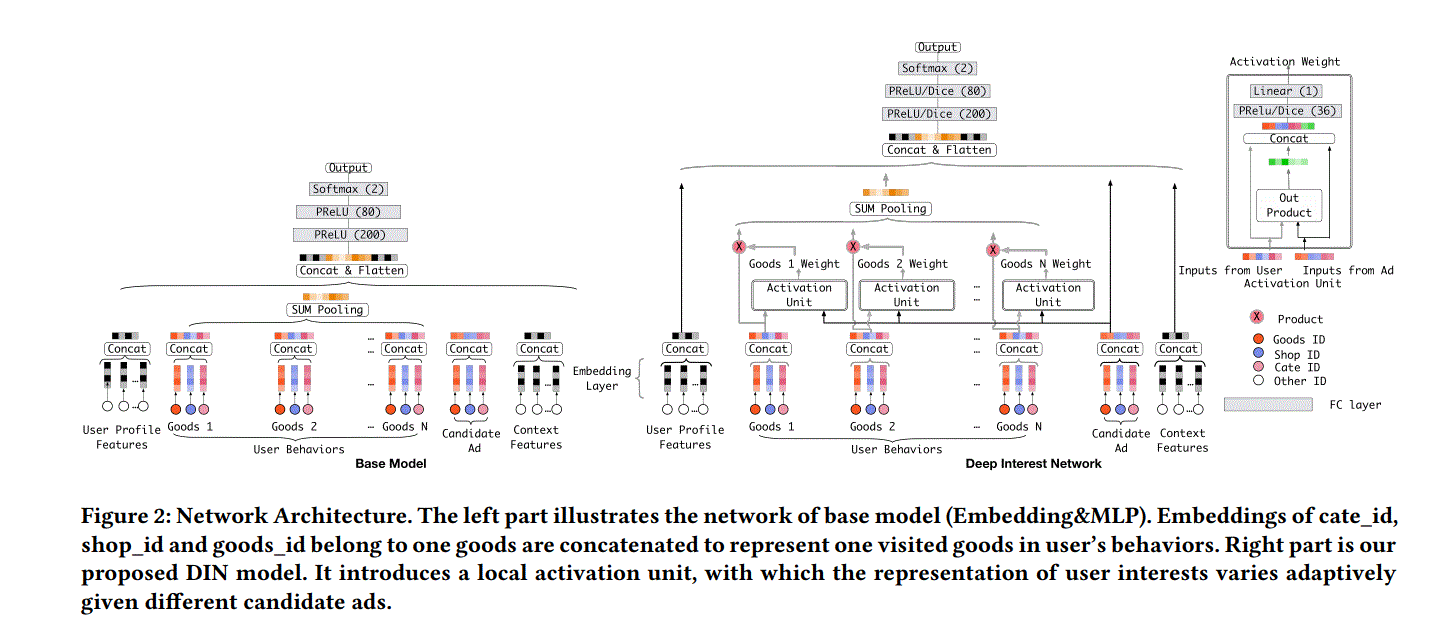
1.1 特征表示
特征可以表示为$\textbf{x}=[t_1^T,t_2^T,…,t_M^T]^T$,one hot表示,举个例子如下
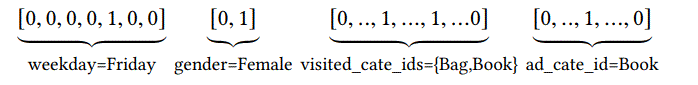
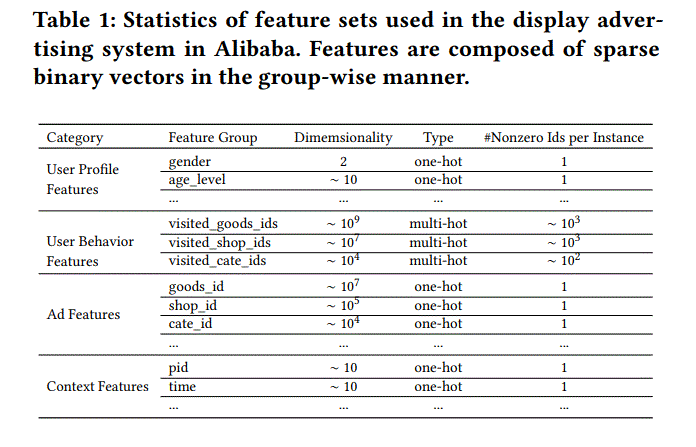
1.2 embedding层
对于$t_i \in \mathbb{R}^{K_i}$,$W^i=[w_1^i,…,w_j^i,…,w_{K_i}^i] \in \mathbb{R}^{D\times K_i} $

1.3 Pooling layer and Concat layer
Two most commonly used pooling layers are sum pooling and average pooling, which apply element-wise sum/average operations to the list of embedding vectors.
1.4 Activation unit
DIN就是在base的基础上加入local activation unit,作用是对用户行为特征的不同商品给与不同权重,其余保持不变,式子表示如下
其中$a(\cdot)$为上图中activate unit,与attention很像,原文是Local activation unit of Eq.(3) shares similar ideas with attention methods which are developed in NMT task[1].
1.5 MLP
1.6 Loss
交叉熵表示为:
2.训练技巧
Practically, training industrial deep networks with large scale sparse input features is of great challenge. 引入Mini-batch Aware Regularization和Data Adaptive Activation Function,具体不在此介绍