排序评价指标
1 效果
1.ndcg
一个query一个ndcg
所有query的ndcg平均就是系统的ndcg
2 正逆序比
1 predict , label
https://zhuanlan.zhihu.com/p/440042900
2 feature , label
2 性能
1 p95
2 qps
一个query一个ndcg
所有query的ndcg平均就是系统的ndcg
1 predict , label
https://zhuanlan.zhihu.com/p/440042900
2 feature , label
1 p95
2 qps
https://tech.meituan.com/2022/08/11/coarse-ranking-exploration-practice.html
https://tech.meituan.com/2021/07/08/multi-business-modeling.html
https://tech.meituan.com/2020/07/09/bert-in-meituan-search.html
整体结构如下
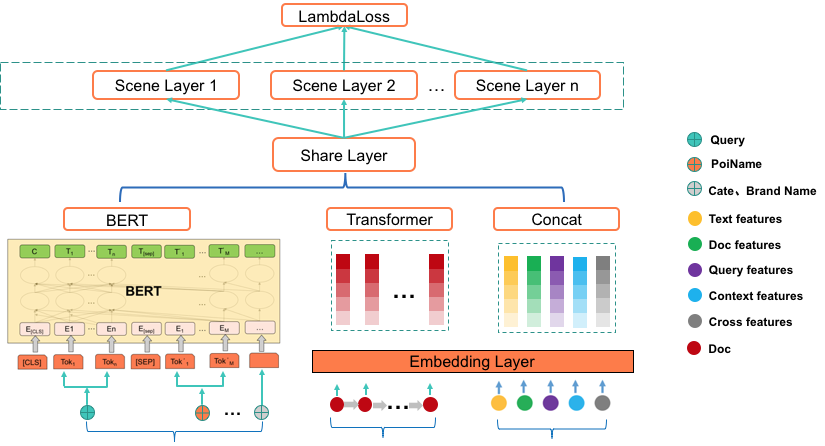
1 BERT预训练
2 多任务学习
场景层:根据业务场景进行划分,每个业务场景单独设计网络结构
3 联合训练
两个任务分别为:
1 相关性任务:相关性+NER(多任务增强相关性)
2 排序任务
怎么联合没看出来
之前是两阶段finetune: 1. 先相关性任务 2 然后排序任务
简单介绍微软出品的DSSM,CNN-DSSM,LSTM-DSSM
原文分别为:
《Learning Deep Structured Semantic Models for Web Search using Clickthrough Data》
《A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval》
《SEMANTIC MODELLING WITH LONG-SHORT-TERM MEMORY FOR INFORMATION RETRIEVAL》
首先为什么叫做双塔,query塔做在线serving,doc塔离线计算embeding建索引,推到线上即可。
注意, DSSM中query和不同的doc是共享参数的, https://flashgene.com/archives/72820.html
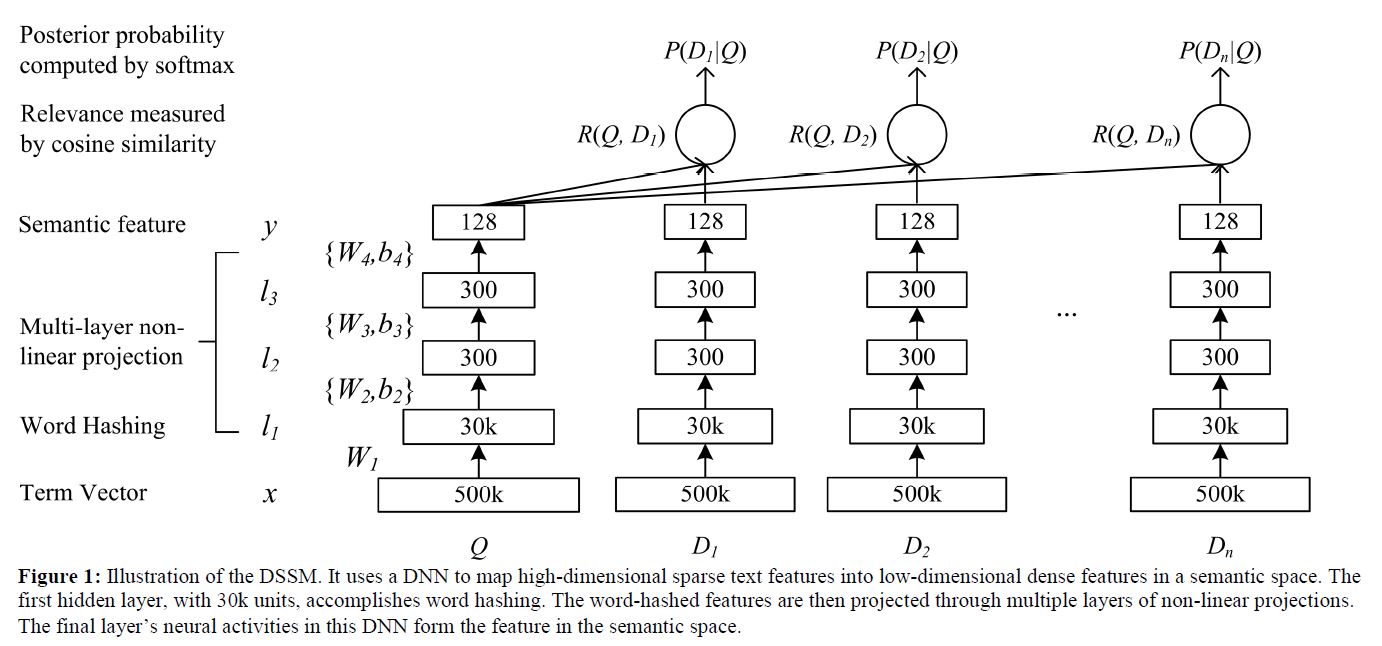
模型的整体结构如上图所示,$Q$为query,$D_i$为文档。
文本的初始词袋表示为$x$,因为参数过多,不利于训练,所以降低维度,就提出了word hashing
word hashing其实就是利于char n-gram分词,然后用向量表示(只是这里依然用词袋表示向量,而不是稠密向量),如下所示

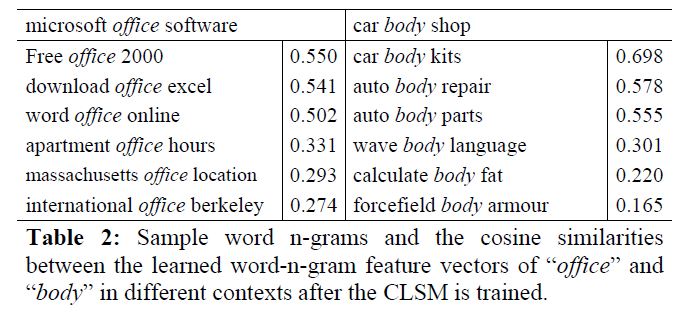
这里有个顾虑为是否存在不同的词使用相同的向量表示。关于这个作者做了实验,结果如下。
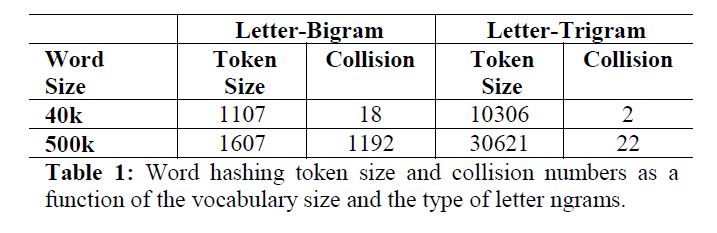
对于词汇数量500K大小的词表,采用3-gram后,此表压缩到30k,而且重复表示的仅为22个。重复表示率为0.0044%,维度压缩到原来6%,可以说非常有效。
然后为多层的非线性映射,每层都为全连接网络,得到
非线性映射层的最后一层得到语义特征$y$为
利用余弦相似度衡量$Q$和$D$相似度得到
最后的概率输出为
其中$\gamma$为smoothing factor。
样本集构造,对每个正样本$(Q,D^+)$,搭配4个随机负样本$(Q,D_j^-;j=1,..,4)$
损失函数为:
其中$\wedge$为模型参数。
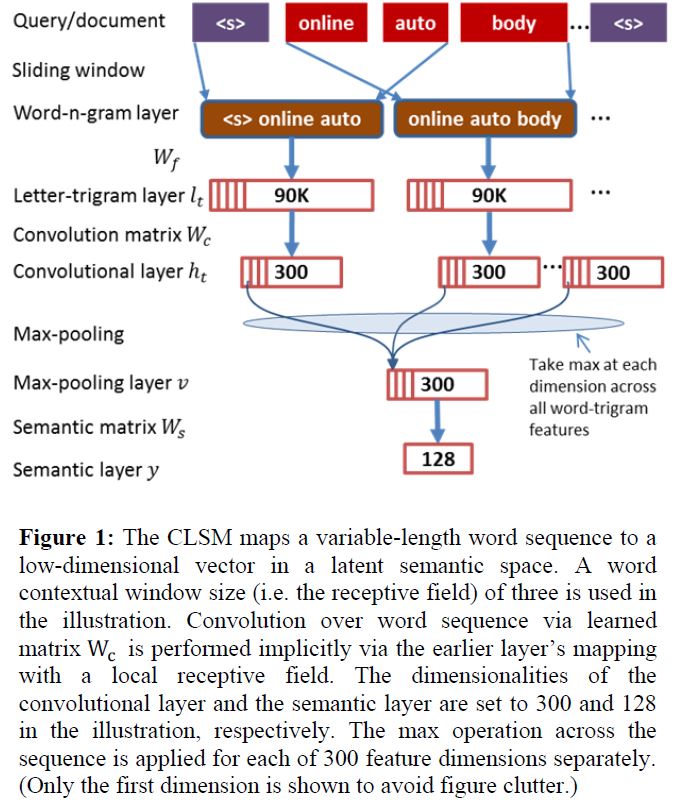
模型包括几个部分:(1) a word-n-gram layer obtained by running a contextual sliding window over the input word sequence (2) a letter-trigram layer that transforms each word-trigram into a letter-trigram representation vector (3) a convolutional layer that extracts contextual features for each word with its neighboring words defined by a window (4) a max-pooling layer that discovers and combines salient word-n-gram features to form a fixed-length sentence-level feature vector (5) a semantic layer that extracts a high-level semantic feature vector for the input word sequence.
在DSSM的Letter-trigram的基础上加了Word-n-gram,Word-n-gram就是对原始输入文本做滑窗,对于第$t$个word-n-gram可以表示为:
其中$n=2d+1,f_t$为的第$t$个词语的letter-trigram。一个letter-trigram的维度为$30K$,那么一个word-n-gram维度为$n\times30K$
举个例子,如上图,输入文本为$(s) \ online \ auto\ body \ (s)$,滑动窗口大小为n=3,可得$(s)\ online \ auto,\ online \ auto \ body ,auto\ body \ (s) $,那么
$l_1=[f^T((s)),f^T(online ),f^T(auto)]^T,\\l_2=[f^T(online ),f^T(auto),f^T(body)]^T,\\l_3=[f^T(auto),f^T(body),f^T((s))]^T$
语境相关特征向量$h_t$可以表示为:
其中$W_c$为特征转换矩阵,也就是卷积矩阵,对于全部的word n-grams,$W_c$共享。有小伙伴肯定好奇,这不就是全连接吗,和卷积什么关系,俺也疑惑?
下图为作者做的一个实验。
获取局部的语境相关的特征向量后,我们需要把它们合在一起组合句子级别的特征向量。由于语句中某些词语不重要,我们可以忽略它,有些词语很重要,要保留。为了达到这个目的,使用了max pooling,用式子描述如下
其中$v(i)$表示池化层输出$v$的第$i$个元素,$K$为$v$的维度和$h_t$的维度一样,$h_t(i)$是第$t$个局部语境特征向量的第$i$个元素。举个例子如下,

语义向量表示$y$,用公式描述如下
和DSSM都一样,
cnn-dssm只能捕获局部的文本信息,lstm对于长序列的信息捕获能力强于lstm,因此使用lstm改进dssm。
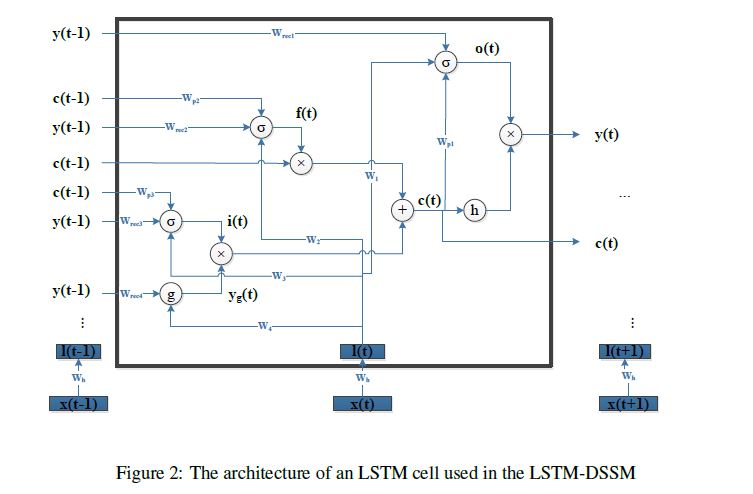
整体结构如下图,注意红色的部分为残差传递的方向。
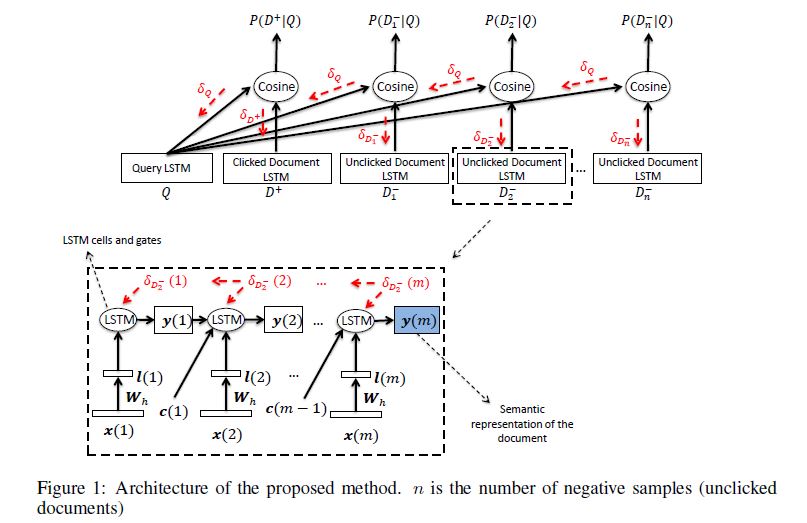
图中的LSTM单元是LSTM的变种,加入了peep hole的 LSTM,具体结构如下。