Solr
https://zhuanlan.zhihu.com/p/71629409?fileGuid=It0Qkg2AiecFMx62
Solr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
https://zhuanlan.zhihu.com/p/71629409?fileGuid=It0Qkg2AiecFMx62
Solr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
改写主要步骤query纠错、query对齐、query扩展
在搜索过程中由于对先验知识的掌握不足或者在使用输入法的时候误输入导致的,本质为去噪过程。
常用的query纠错方法有数字、拼音、漏字、重复字、谐音/形近字等方式。
对于输入query并无错误,但表达上与搜索引擎索引内容不相符而作的一种改写操作。例如“星爷是哪一年生的”,通过实体对齐,可改写为“周星驰的出生时间”。
方法:1.对齐规则 2.文本改写模型
是将与用户输入的query的相似扩展query进行展示,使得用户可以选择更多的搜索内容,帮助用户挖掘潜在需求。
一段文本分词后,对于不同的词语,在相同文本中的重要性应该是不同的。
baseline的无监督方法可以是:tf-idf。
本质是分类任务,多用在搜索引擎和智能问答中。
解决方法
1、基于规则模板意图识别
https://blog.csdn.net/qq_16555103/article/details/100767984
2、基于深度学习模型来对用户的意图进行判别
比如fasttext,LSTM+attention,BERT
https://arxiv.org/pdf/2106.09297.pdf
http://xtf615.com/2021/10/07/taobao-ebr/
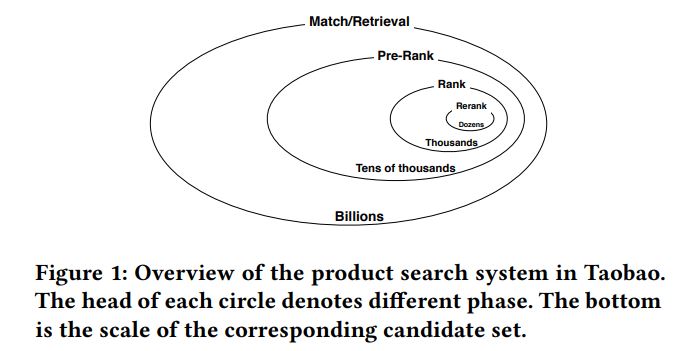
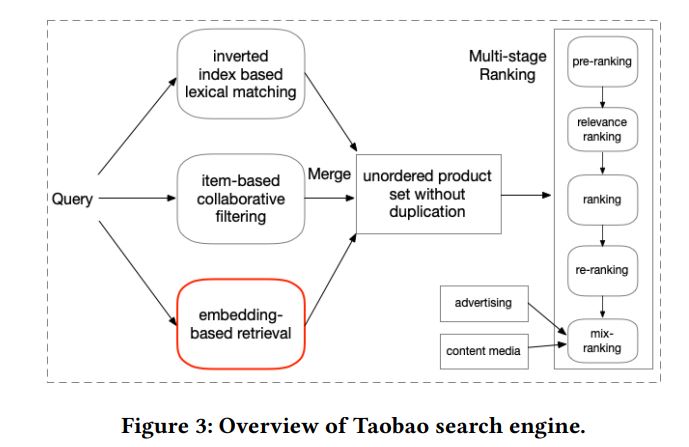
框架是搜索系统主流的结构,即匹配/检索,粗排,精排,重排。
fall into two categories: representation-based learning and interaction-based learning.
Other than semantic and relevance matching, more complex factors/trade-offs, e.g., user personalization [2, 3, 10] and retrieval efficiency [5], need to be considered when applying deep models to a large-scale online retrieval system.
Representation-based models with an ANN (approximate near neighbor) algorithm have become the mainstream trend to efficiently deploy neural retrieval models in industry.
整体结构入下:
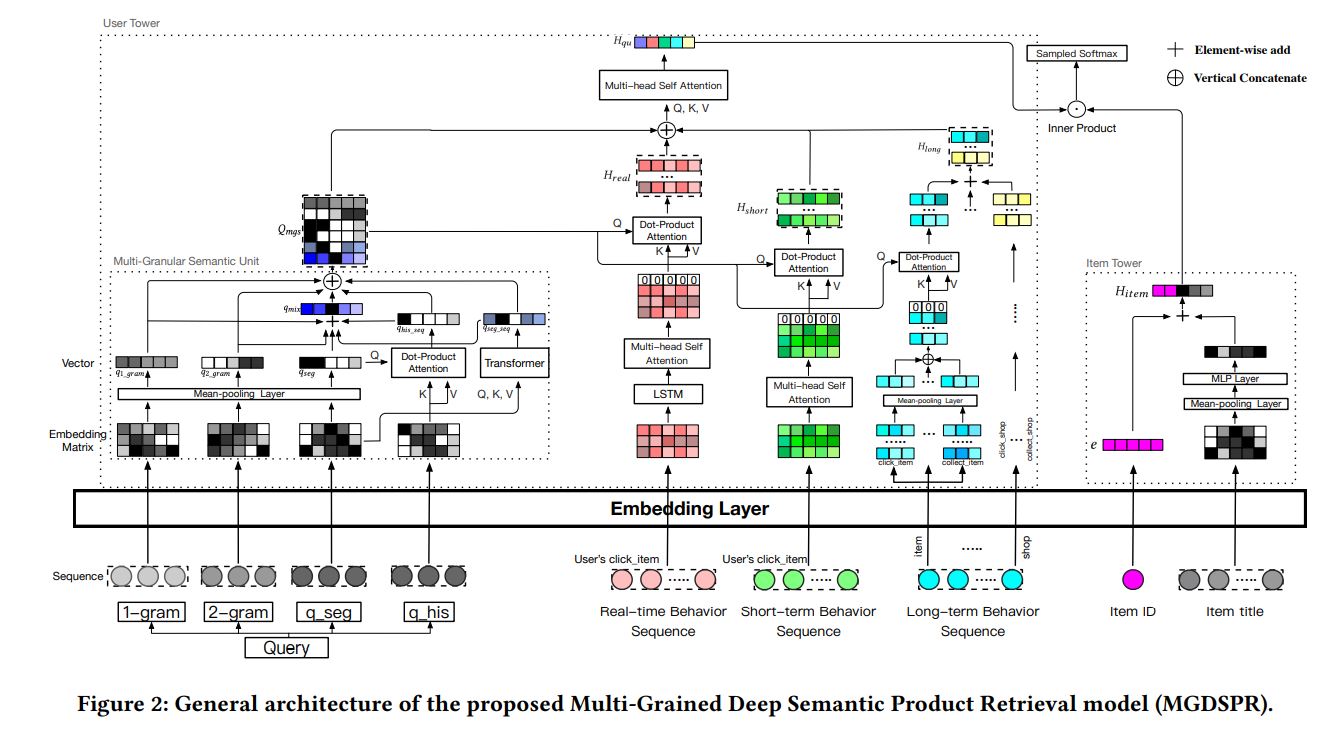
$\mathcal{U}=\{u_1,…,u_u,…u_N\}$表示$N$个用户,$\mathcal{Q}=\{q_1,…,q_u,…q_N\}$表示与用户对应的$N$个query,$\mathcal{I}=\{i_1,…,i_u,…i_M\}$表示$M$个商品。将用户$u$的历史行为根据时间分成3个部分:1.real-time,before
the current time step,$\mathcal{R}^u=\{i_1^u,…,i_t^u,…i_T^u\}$ 2.short-term, before $\mathcal{R}$ and within ten days,$\mathcal{S}^u=\{i_1^u,…,i_t^u,…i_T^u\}$ 3.long-term sequences,before $\mathcal{S}$ and within one month,$\mathcal{L}^u=\{i_1^u,…,i_t^u,…i_T^u\}$ ,$T$为时间长度。任务可以定义为:
其中$\mathcal{F}(\cdot),\phi(\cdot),\varphi(\cdot)$分别表示scoring function, query and behaviors encoder, and item encoder
挖掘query的语义,原始输入包含当前query和历史query
没有说明为什么这么设计,感觉就是工程试验的结论。有个疑问,直接用BERT等深度语言模型来挖掘query的语义不好吗?
query表示为$q_u=\{w_1^u,…,w_n^u\}$,例如{红色,连衣裙},$w_u=\{c_1^u,…,c_m^u\}$,例如{红,色},history query表示为$q_{his}=\{q_1^u,…,q_k^u\} $,例如{绿色,半身裙,黄色,长裙},其中$w_n \in \mathbb{R}^{1\times d},c_m \in \mathbb{R}^{1\times d},q_k \in \mathbb{R}^{1\times d}$
其中𝑇𝑟𝑚,𝑚𝑒𝑎𝑛_𝑝𝑜𝑜𝑙𝑖𝑛𝑔, and 𝑐𝑜𝑛𝑐𝑎𝑡 denote the Transformer ,average, and vertical concatenation operation, respectively
其中$W_f$是embedding matrix,$x_i^{f}$是one-hot vector, $\mathcal{F}$是side information (e.g., leaf category, first-level category, brand and,shop)
real-time sequences
User’s click_item
short-term sequences
User’s click_item
long-term sequence
$\mathcal{L}^u$由四个部分构成,分别为$\mathcal{L}^{u}_{item},\mathcal{L}^{u}_{shop},\mathcal{L}^{u}_{leaf},\mathcal{L}^{u}_{brand}$,每个部分包含3个动作,分别为click,buy,collect。
For the item tower, we experimentally use item ID and title to obtain the item representation 𝐻𝑖𝑡𝑒𝑚.Given the representation of item 𝑖’s ID, $e_i \in \mathbb{R}^{1\times d}$ , and its title segmentation result $T_i=\{w_1^{i},…,w_N^{i}\}$
where $W_t$ is the transformation matrix. We empirically find that applying LSTM [12] or Transformer [27] to capture the context of the title is not as effective as simple mean-pooling since the title is stacked by keywords and lacks grammatical structure.
adapt the softmax cross-entropy loss as the training objective
where $\mathcal{F},I,i^+,q_u$denote the inner product, the full item pool, the item tower’s representation $H_{item}$, and the user tower’s representation $H_{qu}$, respectively.
the softmax function with the temperature parameter $\tau$ is defined as follows
If 𝜏->0, the fitted distribution is close to one hot distribution,If 𝜏->∞, the fitted distribution is close to a uniform distribution
We first select the negative items of $i^-$ that have the top-𝑁 inner product scores with $q_u $ to form the hard sample set $I_{hard}$
其中$\alpha\in \mathbb{R}^{N\times1}$is sampled from the uniform distribution 𝑈 (𝑎, 𝑏) (0 ≤ 𝑎 < 𝑏 ≤ 1).
https://tech.meituan.com/2022/08/11/coarse-ranking-exploration-practice.html
https://tech.meituan.com/2021/07/08/multi-business-modeling.html
https://tech.meituan.com/2020/07/09/bert-in-meituan-search.html
整体结构如下
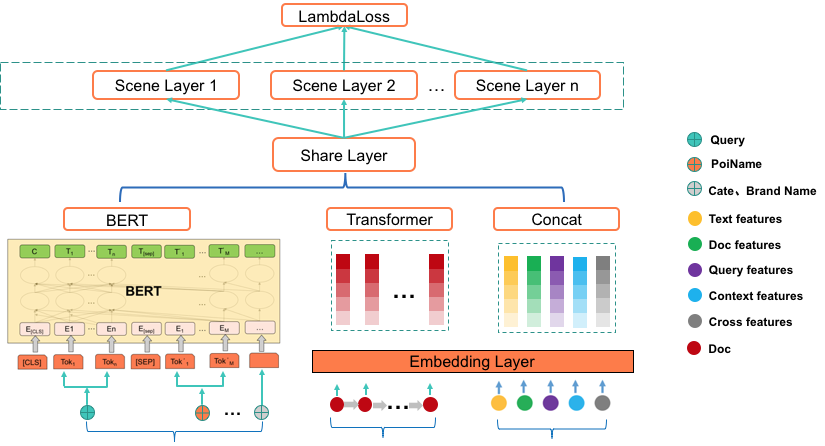
1 BERT预训练
2 多任务学习
场景层:根据业务场景进行划分,每个业务场景单独设计网络结构
3 联合训练
两个任务分别为:
1 相关性任务:相关性+NER(多任务增强相关性)
2 排序任务
怎么联合没看出来
之前是两阶段finetune: 1. 先相关性任务 2 然后排序任务
简单介绍微软出品的DSSM,CNN-DSSM,LSTM-DSSM
原文分别为:
《Learning Deep Structured Semantic Models for Web Search using Clickthrough Data》
《A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval》
《SEMANTIC MODELLING WITH LONG-SHORT-TERM MEMORY FOR INFORMATION RETRIEVAL》
首先为什么叫做双塔,query塔做在线serving,doc塔离线计算embeding建索引,推到线上即可。
注意, DSSM中query和不同的doc是共享参数的, https://flashgene.com/archives/72820.html
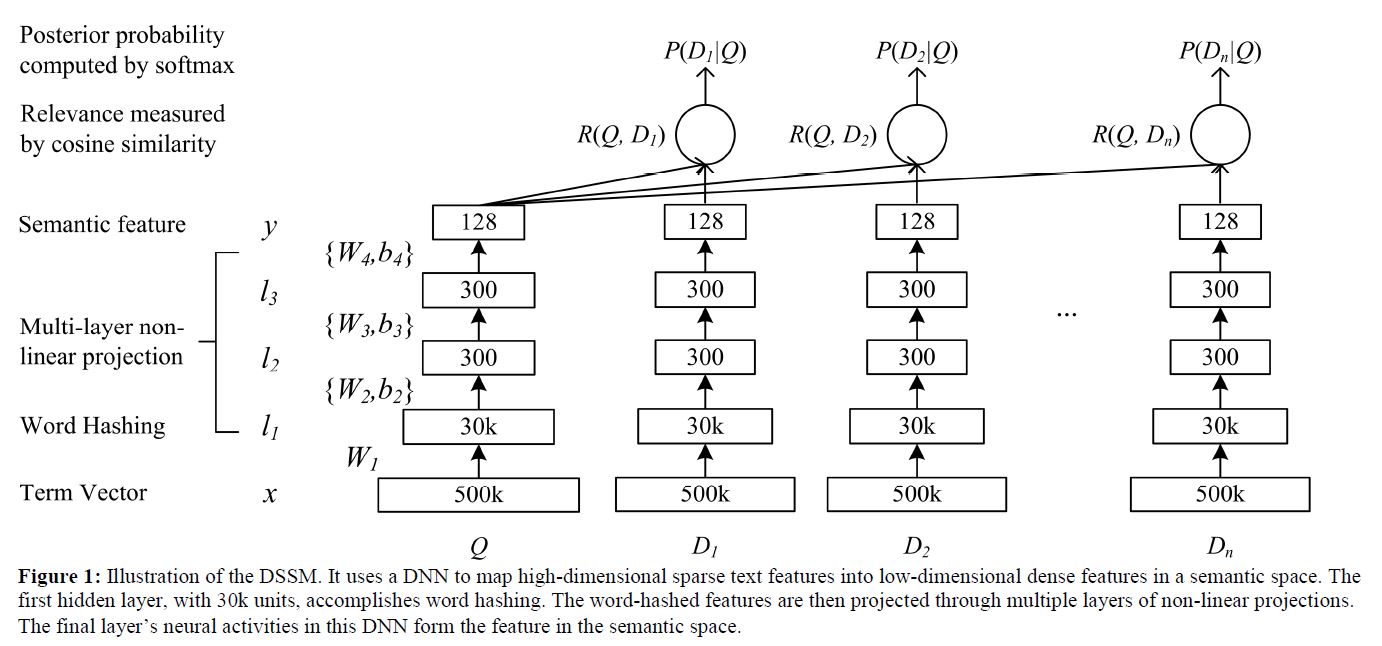
模型的整体结构如上图所示,$Q$为query,$D_i$为文档。
文本的初始词袋表示为$x$,因为参数过多,不利于训练,所以降低维度,就提出了word hashing
word hashing其实就是利于char n-gram分词,然后用向量表示(只是这里依然用词袋表示向量,而不是稠密向量),如下所示

这里有个顾虑为是否存在不同的词使用相同的向量表示。关于这个作者做了实验,结果如下。
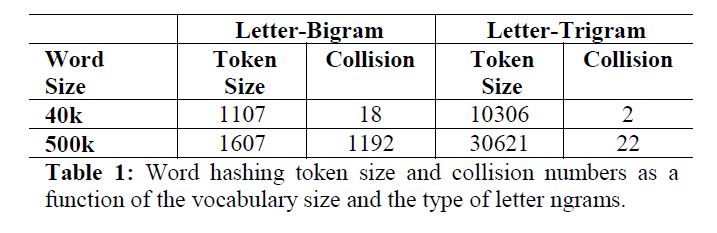
对于词汇数量500K大小的词表,采用3-gram后,此表压缩到30k,而且重复表示的仅为22个。重复表示率为0.0044%,维度压缩到原来6%,可以说非常有效。
然后为多层的非线性映射,每层都为全连接网络,得到
非线性映射层的最后一层得到语义特征$y$为
利用余弦相似度衡量$Q$和$D$相似度得到
最后的概率输出为
其中$\gamma$为smoothing factor。
样本集构造,对每个正样本$(Q,D^+)$,搭配4个随机负样本$(Q,D_j^-;j=1,..,4)$
损失函数为:
其中$\wedge$为模型参数。
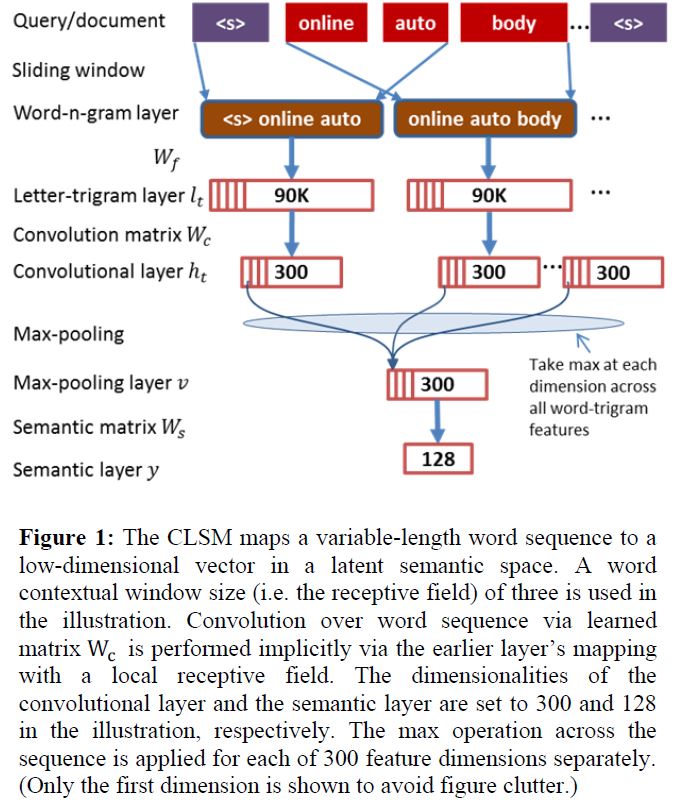
模型包括几个部分:(1) a word-n-gram layer obtained by running a contextual sliding window over the input word sequence (2) a letter-trigram layer that transforms each word-trigram into a letter-trigram representation vector (3) a convolutional layer that extracts contextual features for each word with its neighboring words defined by a window (4) a max-pooling layer that discovers and combines salient word-n-gram features to form a fixed-length sentence-level feature vector (5) a semantic layer that extracts a high-level semantic feature vector for the input word sequence.
在DSSM的Letter-trigram的基础上加了Word-n-gram,Word-n-gram就是对原始输入文本做滑窗,对于第$t$个word-n-gram可以表示为:
其中$n=2d+1,f_t$为的第$t$个词语的letter-trigram。一个letter-trigram的维度为$30K$,那么一个word-n-gram维度为$n\times30K$
举个例子,如上图,输入文本为$(s) \ online \ auto\ body \ (s)$,滑动窗口大小为n=3,可得$(s)\ online \ auto,\ online \ auto \ body ,auto\ body \ (s) $,那么
$l_1=[f^T((s)),f^T(online ),f^T(auto)]^T,\\l_2=[f^T(online ),f^T(auto),f^T(body)]^T,\\l_3=[f^T(auto),f^T(body),f^T((s))]^T$
语境相关特征向量$h_t$可以表示为:
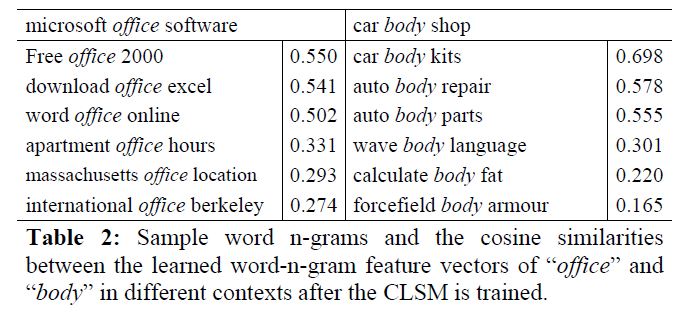
其中$W_c$为特征转换矩阵,也就是卷积矩阵,对于全部的word n-grams,$W_c$共享。有小伙伴肯定好奇,这不就是全连接吗,和卷积什么关系,俺也疑惑?
下图为作者做的一个实验。
获取局部的语境相关的特征向量后,我们需要把它们合在一起组合句子级别的特征向量。由于语句中某些词语不重要,我们可以忽略它,有些词语很重要,要保留。为了达到这个目的,使用了max pooling,用式子描述如下
其中$v(i)$表示池化层输出$v$的第$i$个元素,$K$为$v$的维度和$h_t$的维度一样,$h_t(i)$是第$t$个局部语境特征向量的第$i$个元素。举个例子如下,

语义向量表示$y$,用公式描述如下
和DSSM都一样,
cnn-dssm只能捕获局部的文本信息,lstm对于长序列的信息捕获能力强于lstm,因此使用lstm改进dssm。
整体结构如下图,注意红色的部分为残差传递的方向。
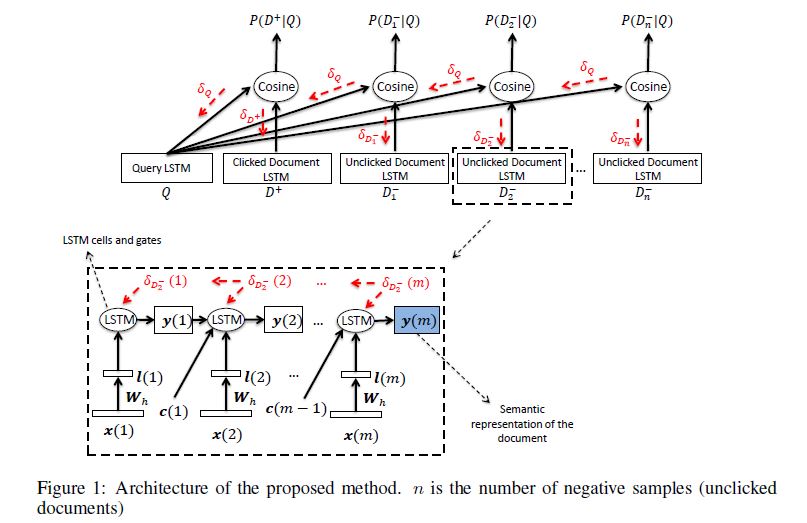
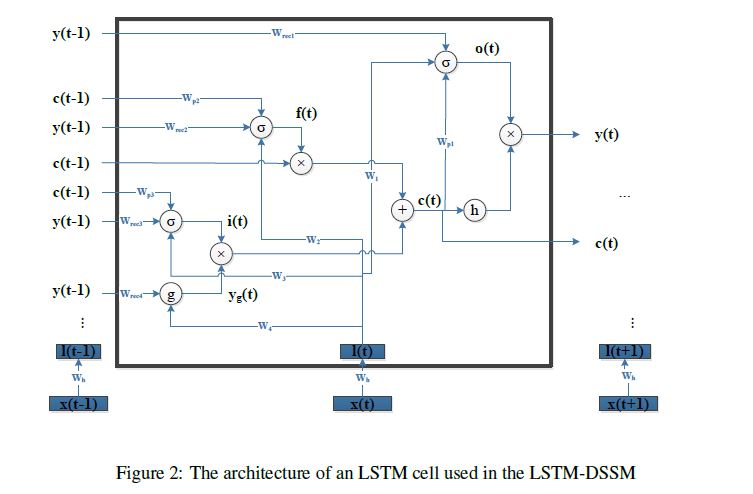
图中的LSTM单元是LSTM的变种,加入了peep hole的 LSTM,具体结构如下。
https://zhuanlan.zhihu.com/p/112719984
https://zhuanlan.zhihu.com/p/382001982
物料获取-> 处理物料 -> 1.构建索引 2.属性库
query -> query理解 -> 召回 -> 排序 -> 结果