前馈神经网络
Feedforward neural network,FNN
和全连接神经网络的区别???
很多的深度模型都属于表示学习,是为了得到好的特征表示,比如文本表示之类的模型,有了好的特征表示,才能增强分类或者回归的效果。某些端到端的模型其实可以拆解成几个部分,比如前置的环节包括了特征提取,特征表示,然后顶层是分类或者回归层。下文总结的是纯粹的分类和回归的模型。
https://www.jianshu.com/p/169dc01f0589
大佬写的很详细,Mark一下
https://www.cnblogs.com/pinard/p/7048333.html
https://zhuanlan.zhihu.com/p/148813079#
KNN可以用来分类和回归,以分类为例。
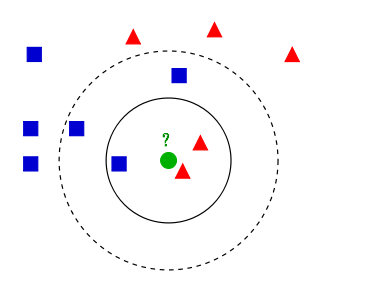
KNN分类算法的计算过程:
1)计算待分类点与已知类别的点之间的距离
2)按照距离递增次序排序
3)选取与待分类点距离最小的K个点
4)确定前K个点所在类别的出现次数
5)返回前K个点出现次数最高的类别作为待分类点的预测分类
如上图,举个例子:
1.闵可夫斯基距离
2.欧式距离
3.曼哈顿距离
选择较小的K值,容易发生过拟合;选择较大的K值,则容易欠拟合。在应用中,通常采用交叉验证法来选择最优K值。
优点:
1)算法简单,理论成熟,既可以用来做分类也可以用来做回归。
2)可用于非线性分类。
缺点:
1)需要算每个测试点与训练集的距离,当训练集较大时,计算量相当大,时间复杂度高,特别是特征数量比较大的时候。
2)样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少),对稀有类别的预测准确度低。
线性回归是解决回归任务的线性模型
LR是二分类模型,在线性模型的基础上加入激活函数sigmoid,适用在线性可分的二分类任务
简单总结:1.对于完全线性可分,硬间隔 2.不能够完全线性可分,引入松弛变量 ,软间隔 3.线性不可分,引入核函数
原理可参考: https://zhuanlan.zhihu.com/p/77750026 或者 https://blog.csdn.net/qq_37321378/article/details/108807595
核函数 https://blog.csdn.net/mengjizhiyou/article/details/103437423
