调节学习率
当学习率过大的时候会导致模型难以收敛,过小的时候会收敛速度过慢,合理的学习率才能让模型收敛到最小点而非局部最优点或鞍点
经验值: 0.01 ~ 0.001
学习率衰减
原因:起初距离目标偏离大,可以设置较大,为了快速收敛,后续逐渐靠近目标,需要精细化一点,所以希望值小一点
分类
1.轮数衰减
每经过k个epochs后学习率减半
2.指数衰减
3.分数衰减
参考
https://blog.csdn.net/LiuPeiP_VIPL/article/details/119581343
权重初始化
参数初始权重为什么不全0或者任意相同值
如果我们将神经网络中的权重集初始化为零或者相同,那么同一层的所有神经元将在反向传播期间开始产生相同的输出和相同的梯度。导致同一层每个神经元完全一样,等价于只有一个
常用的三种权值初始化方法
随机初始化、Xavier initialization、He initialization
参考
https://mdnice.com/writing/6fe7dfe1954945d180d6b36562658af8
https://m.ofweek.com/ai/2021-06/ART-201700-11000-30502442.html
调参
1. 调什么参数
1 训练层面
0 权重初始化
1 学习率
2 batch size
3 epoch
4 dropout
5 正则化
6 优化算法
2 模型层面
1 激活函数
2 网络尺寸
2. 超参数怎么调
1.手动调参
经验值
2.自动化调参
a.网格搜索
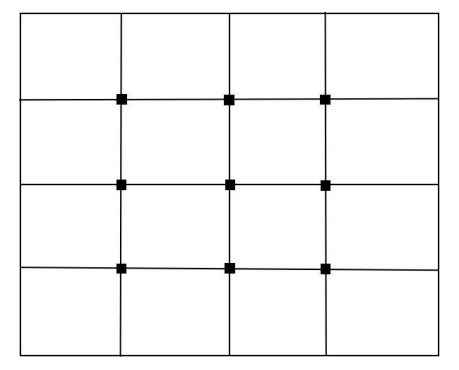
超参数排序组合,如果有n个参数,每个参数都有m个候选值,那么网格搜索中就要训练m的n次方个模型。
b.随机搜索
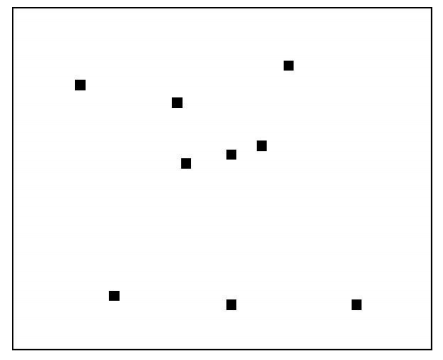
比起网格搜索:1、搜索次数少,快 2. 因为有偶然性,可能不是最优
c.贝叶斯优化
https://zhuanlan.zhihu.com/p/146633409
Bayesian optimization algorithm,简称BOA
网格搜索和随机搜索,每次都是相互独立的,贝叶斯优化利用之前已搜索点的信息确定下一个搜索点
参考
https://zhuanlan.zhihu.com/p/340578370
https://www.jianshu.com/p/92d8943fb0ba
https://zhuanlan.zhihu.com/p/146633409
https://blog.csdn.net/weixin_45884316/article/details/109828084
正则化
是机器学习中对原始损失函数引入额外信息,以便防止过拟合和提高模型泛化性能的一类方法的统称。
1.L1正则(Lasso回归)
L1正则化可以使得参数稀疏化,即得到的参数是一个稀疏矩阵,可以用于特征选择。
L1是每次减去一个常数的收敛,所以L1更容易收敛到0。
2.L2正则(Ridge回归)
L2正则化使得参数平滑。
L2是每次乘上一个小于1的倍数进行收敛,所以L2使得参数平滑。
3.dropout
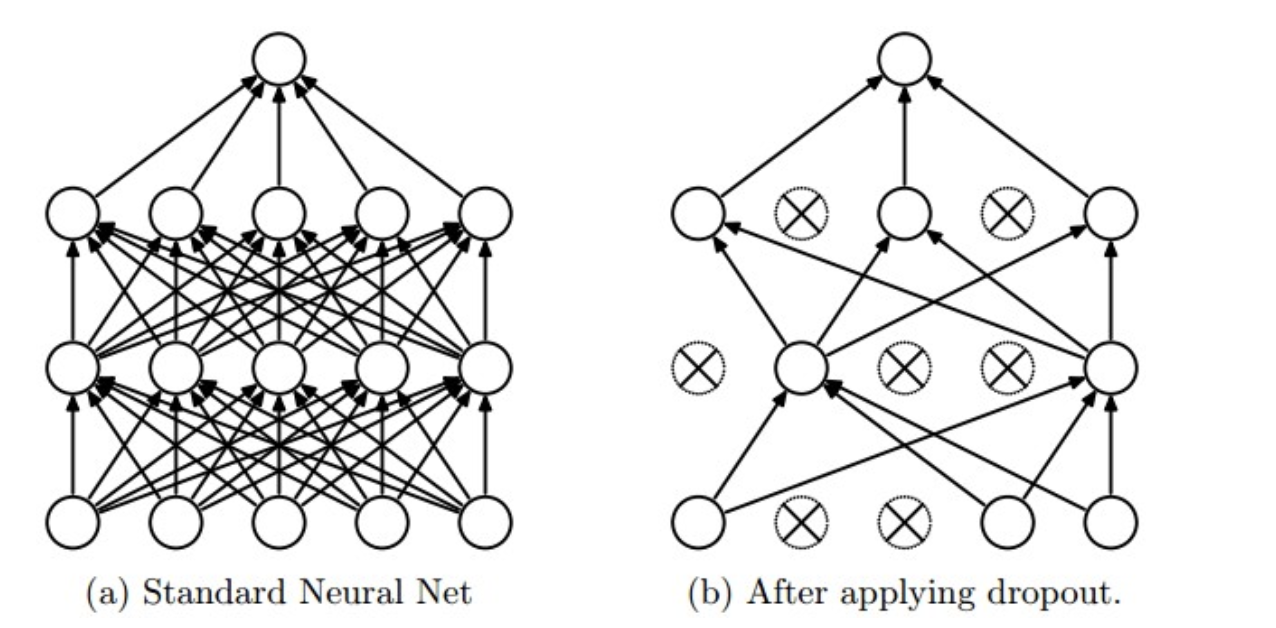
使用:在训练时,每个神经单元以概率$p$被保留(Dropout丢弃率为$1−p$);在预测阶段,每个神经单元都是存在的。
原理:神经网络通过Dropout层以一定比例随即的丢弃神经元,使得每次训练的网络模型都不相同,多个Epoch下来相当于训练了多个模型,同时每一个模型都参与了对最终结果的投票,从而提高了模型的泛化能力,类似bagging。
参考
https://www.cnblogs.com/zingp/p/11631913.html