分类任务的衡量指标
一、二分类
1.1 confusion matrix
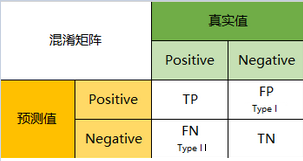
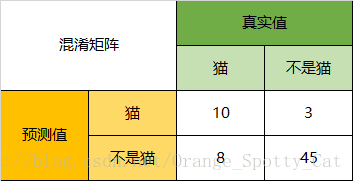
1.2 accuracy
accuracy 衡量全局分类正确的数量占总样本的比例
1.3 precision
precision为预测正确正样本数占预测的全部正样本数的比例,即系统判定为正样本的正确率。通俗地说,假如医生给病人检查,医生判断病人有疾病,然后医生判断的正确率有多少。
1.4 recall
recall为预测正确的正样本数量占真实正样本数量的比例,即衡量正样本的召回比例。通俗说,假如有一批病人,医生能从中找出病人的比例
1.5 F1
由于precision和recall往往是矛盾的,因此为了综合考虑二者,引入F1,即为precision和recall的调和平均
当$precision$和$recall$的任一个值为0,$F_1$都为0
之所以采用调和平均,是因为调和平均数受极端值影响较大,更适合评价不平衡数据的分类问题
通用的F值表达式:
除了$F_1$分数之外,$F_2$ 分数和$F_{0.5}$分数在统计学中也得到大量的应用。其中,$F_2$分数中,召回率的权重高于精确率,而$F_{0.5}$分数中,精确率的权重高于召回率。
1.6 ROC
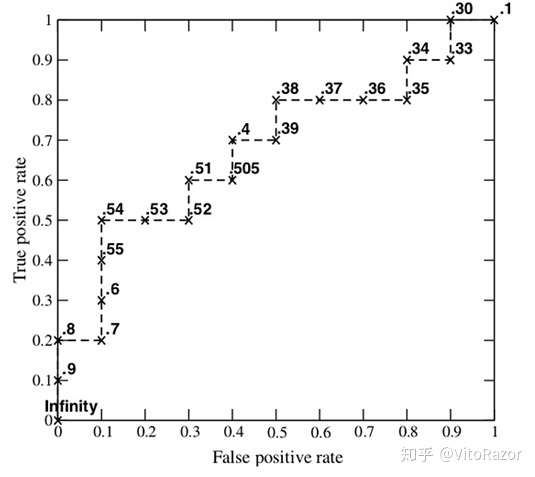
roc曲线:接收者操作特征(receiver operating characteristic), roc曲线上每个点反映某个阈值下的FPR和TPR的组合。
横轴:$FPR$,叫做假正类率,表示预测为正例但真实情况为反例的占所有真实情况中反例的比率,公式为$FPR=\frac{FP}{TN+FP}$。
纵轴:$TPR$ ,叫做真正例率,表示预测为正例且真实情况为正例的占所有真实情况中正例的比率,公式为
$TPR=\frac{TP}{TP+FN}$。
1.7 AUC
$AUC$(Area under Curve):ROC曲线下的面积,数值可以直观评价分类器的好坏,值越大越好,对于二分类,结果介于0.5和1之间,1为完美分类器,0.5是因为二分类分类效果最差也是0.5。
二、多分类
2.1 混淆矩阵
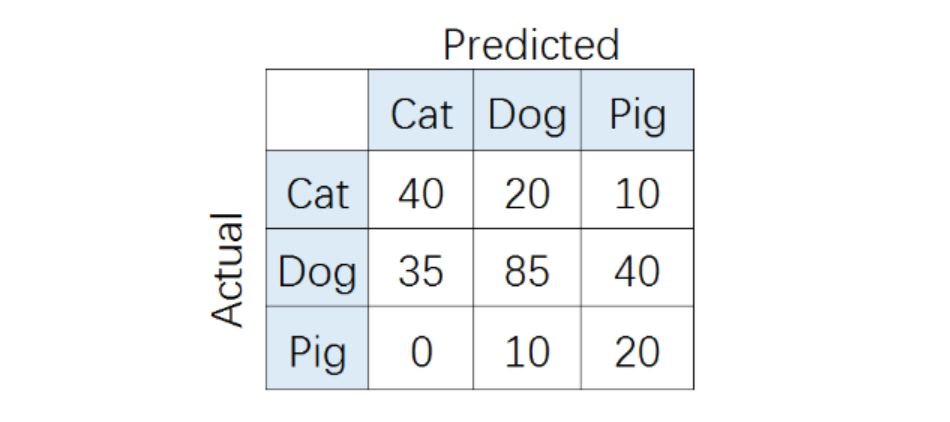
2.2 accuracy
2.3 某个类别的precision,recall,F1
与二分类公式一样
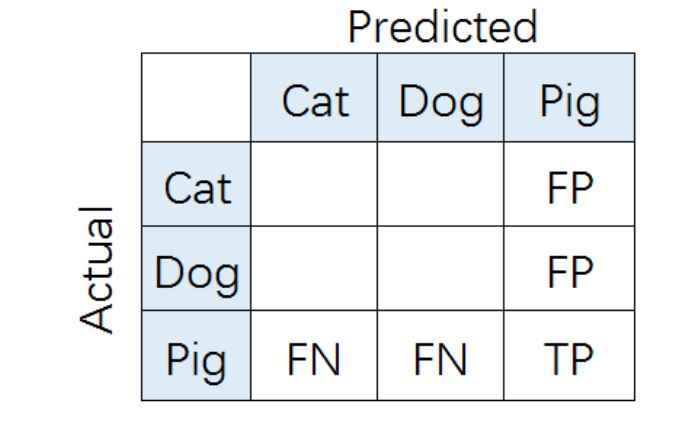
2.4 系统的precision,recall,F1
系统的precision,recall,$F_1$需要综合考虑所有类别,即同时考虑猫、狗、猪的precision,recall,$F_1$。有如下几种方案:
2.4.1 Macro average
2.4.2 Weighted average
对macro的推广
2.4.3 Micro average
2.5 ROC
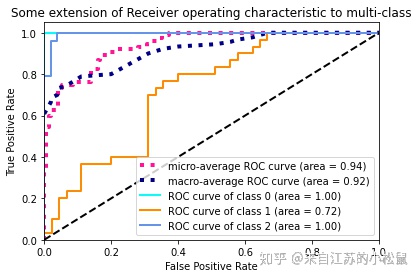
对于多分类分类器整体效果的ROC如上micro或者macro曲线,其余3条描述单个类别的分类效果。对于多分类,ROC上的点,同样是某个阈值下的FPR和TPR的组合。
对于多分类的$FPR$,$TPR$,有几种计算方式
a. micro average
b. macro average
2.6 AUC
$AUC$依旧为ROC曲线下的面积,对于多分类个人认为取值范围为[0,1]。
三.代码
accuracy,precision,recall,F1
1 | from sklearn.metrics import precision_recall_fscore_support, accuracy_score |
ROC和AUC
1 | # 引入必要的库 |
参考资料:
https://blog.csdn.net/Orange_Spotty_Cat/article/details/80520839
https://zhuanlan.zhihu.com/p/147663370