调参
1. 调什么参数
1 训练层面
0 权重初始化
1 学习率
2 batch size
3 epoch
4 dropout
5 正则化
6 优化算法
2 模型层面
1 激活函数
2 网络尺寸
2. 超参数怎么调
1.手动调参
经验值
2.自动化调参
a.网格搜索
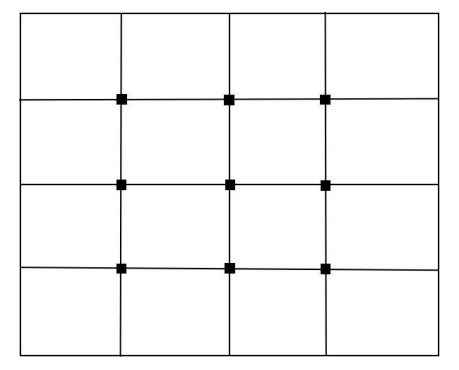
超参数排序组合,如果有n个参数,每个参数都有m个候选值,那么网格搜索中就要训练m的n次方个模型。
b.随机搜索
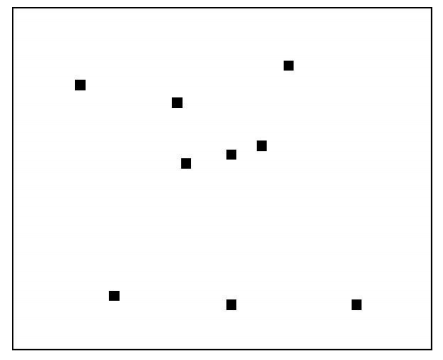
比起网格搜索:1、搜索次数少,快 2. 因为有偶然性,可能不是最优
c.贝叶斯优化
https://zhuanlan.zhihu.com/p/146633409
Bayesian optimization algorithm,简称BOA
网格搜索和随机搜索,每次都是相互独立的,贝叶斯优化利用之前已搜索点的信息确定下一个搜索点
参考
https://zhuanlan.zhihu.com/p/340578370
https://www.jianshu.com/p/92d8943fb0ba
https://zhuanlan.zhihu.com/p/146633409
https://blog.csdn.net/weixin_45884316/article/details/109828084
分类回归模型总结
很多的深度模型都属于表示学习,是为了得到好的特征表示,比如文本表示之类的模型,有了好的特征表示,才能增强分类或者回归的效果。某些端到端的模型其实可以拆解成几个部分,比如前置的环节包括了特征提取,特征表示,然后顶层是分类或者回归层。下文总结的是纯粹的分类和回归的模型。
1.分类
https://www.jianshu.com/p/169dc01f0589
2.回归
分类任务的类别数量很大(万以上)怎么处理?
https://www.zhihu.com/question/387899184
Extreme Multi Label Classification,XML,可以提供一些启发 https://zhuanlan.zhihu.com/p/131584886
特征工程
https://zhuanlan.zhihu.com/p/111296130
1.特征预处理
0.是否去重
1.缺失值
均值补全
2.异常值
检测异常值
数值范围
sigma准则
knn
箱线图
处理异常值
剔除
均值补全
2.特征表示
特征分类:数值特征,文本特征,类别特征
1.数值特征
1.直接使用数值
2.离散化
分桶
2.类别特征
1.one hot
2.embedding
3.其他
catboost
3.特征选择
https://blog.csdn.net/Datawhale/article/details/120582526
大致分为3种,filter,wrapper,embedded