原文 https://arxiv.org/pdf/1909.03193.pdf
一.背景补充
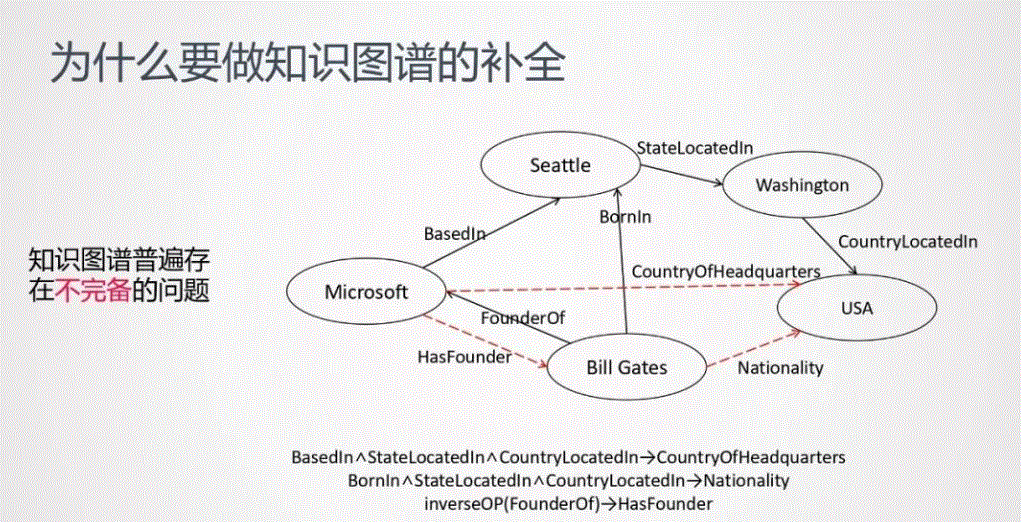
知识图谱普遍存在不完备的问题。以上图为例,黑色的箭头表示已经存在的关系,红色的虚线则是缺失的关系。知识图谱补全是基于图谱里已有的关系去推理出缺失的关系。由于BERT在NLP取得的成绩,作者将其迁移到知识图谱补全的应用上。
二.结构
作者设计了两种训练方式的KG - BERT, 可以运用到不同的知识图谱补全任务当中。
2.1 Illustrations of fine-tuning KG-BERT for predicting the plausibility of a triple
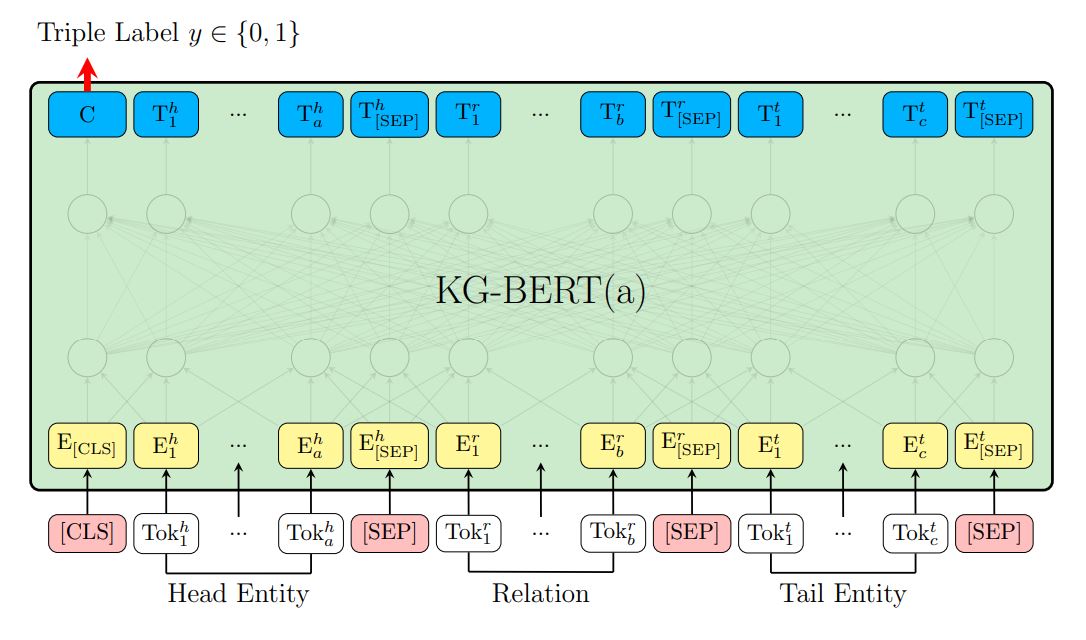
输入由三部分组成,$Head$,$Relation$,$Tail$。举个例子,$Head$可以是“Steven Paul Jobs was an American business magnate,entrepreneur and investor.” 或者“Steve Jobs”,$Relation$可以是“founded”,$Tail$可以是“Apple Inc. is an American multinational technology company headquartered in Cupertino, California.”或者“Apple Inc.”。用$[SEP]$分隔实体和关系。输入为3个向量的sum,即token, segment 和position embeddings。对于segment,实体的segment Embedding为$e_A$,而关系的segment Embedding为$e_B$。对于position ,相同position的不同token使用相同的position embedding。
对于输入的三元组$\tau=(h,r,t)$,目标函数为:
损失函数是$S$和$y$的交叉熵:
其中$y_{\tau}\in \{0,1\}$是标签。
关于负样本的构造,作者是将正样本的$Head$或者$Tail$变成随机替换成别的,如下
其中$E$为实体的集合。
2.2 Illustrations of fine-tuning KG-BERT for predicting the relation between two entities
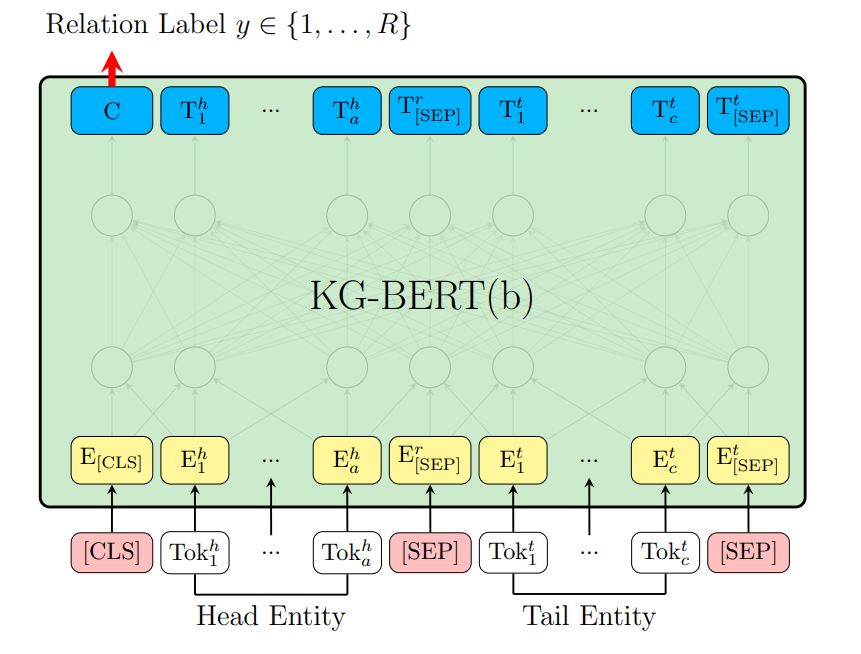
作者发现直接使用两个实体去预测关系,效果优于使用两个实体和一个随机关系(这里本人认为一个随机的关系本来就是错误特征,感觉肯定会影响预测结果)。这里和2.1结构的差异在于:1.输入从实体加关系的三输入变成基于实体的双输入2.输出从二分类变成多分类
目标函数为:
损失函数为$S^{‘}$和$y^{‘}$的交叉熵:
三.实验
setting: We choose pre-trained BERT-Base model with 12 layers, 12 self-attention heads and H = 768 as the initialization of KG-BERT, then fine tune KG-BERT with Adam implemented in BERT.